 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelve into the Applicability of Advanced Optimizers for Multi-Task Learning
Apr 10, 2026Multi-Task Learning (MTL) is a foundational machine learning problem that has seen extensive development over the past decade. Recently, various optimization-based MTL approaches have been proposed to learn multiple tasks simultaneously by altering the optimization trajectory. Although these methods strive to de-conflict and re-balance tasks, we empirically identify that their effectiveness is often undermined by an overlooked factor when employing advanced optimizers: the instant-derived gradients play only a marginal role in the actual parameter updates. This discrepancy prevents MTL frameworks from fully releasing its power on learning dynamics. Furthermore, we observe that Muon-a recently emerged advanced optimizer-inherently functions as a multi-task learner, which underscores the critical importance of the gradients used for its orthogonalization. To address these issues, we propose APT (Applicability of advanced oPTimizers), a framework featuring a simple adaptive momentum mechanism designed to balance the strengths between advanced optimizers and MTL. Additionally, we introduce a light direction preservation method to facilitate Muon's orthogonalization. Extensive experiments across four mainstream MTL datasets demonstrate that APT consistently augments existing MTL approaches, yielding substantial performance improvements.
PASK: Toward Intent-Aware Proactive Agents with Long-Term Memory
Apr 09, 2026Proactivity is a core expectation for AGI. Prior work remains largely confined to laboratory settings, leaving a clear gap in real-world proactive agent: depth, complexity, ambiguity, precision and real-time constraints. We study this setting, where useful intervention requires inferring latent needs from ongoing context and grounding actions in evolving user memory under latency and long-horizon constraints. We first propose DD-MM-PAS (Demand Detection, Memory Modeling, Proactive Agent System) as a general paradigm for streaming proactive AI agent. We instantiate this paradigm in Pask, with streaming IntentFlow model for DD, a hybrid memory (workspace, user, global) for long-term MM, PAS infra framework and introduce how these components form a closed loop. We also introduce LatentNeeds-Bench, a real-world benchmark built from user-consented data and refined through thousands of rounds of human editing. Experiments show that IntentFlow matches leading Gemini3-Flash models under latency constraints, while identifying deeper user intent.
IESR:Efficient MCTS-Based Modular Reasoning for Text-to-SQL with Large Language Models
Feb 05, 2026Text-to-SQL is a key natural language processing task that maps natural language questions to SQL queries, enabling intuitive interaction with web-based databases. Although current methods perform well on benchmarks like BIRD and Spider, they struggle with complex reasoning, domain knowledge, and hypothetical queries, and remain costly in enterprise deployment. To address these issues, we propose a framework named IESR(Information Enhanced Structured Reasoning) for lightweight large language models: (i) leverages LLMs for key information understanding and schema linking, and decoupling mathematical computation and SQL generation, (ii) integrates a multi-path reasoning mechanism based on Monte Carlo Tree Search (MCTS) with majority voting, and (iii) introduces a trajectory consistency verification module with a discriminator model to ensure accuracy and consistency. Experimental results demonstrate that IESR achieves state-of-the-art performance on the complex reasoning benchmark LogicCat (24.28 EX) and the Archer dataset (37.28 EX) using only compact lightweight models without fine-tuning. Furthermore, our analysis reveals that current coder models exhibit notable biases and deficiencies in physical knowledge, mathematical computation, and common-sense reasoning, highlighting important directions for future research. We released code at https://github.com/Ffunkytao/IESR-SLM.
Sharpness-aware Federated Graph Learning
Dec 18, 2025
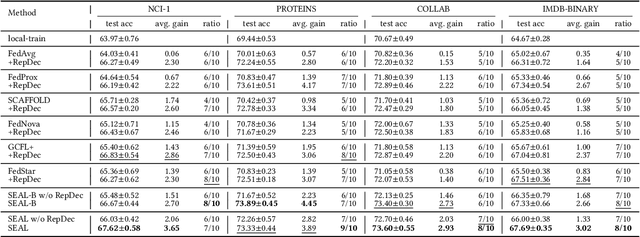
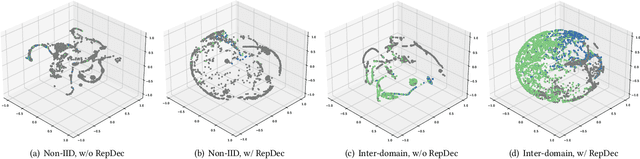
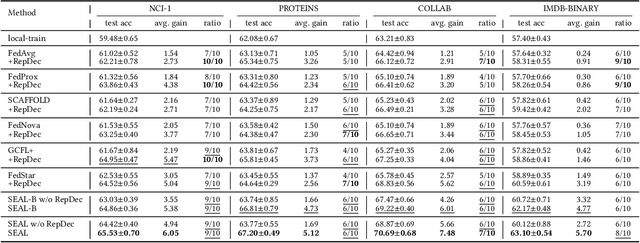
One of many impediments to applying graph neural networks (GNNs) to large-scale real-world graph data is the challenge of centralized training, which requires aggregating data from different organizations, raising privacy concerns. Federated graph learning (FGL) addresses this by enabling collaborative GNN model training without sharing private data. However, a core challenge in FGL systems is the variation in local training data distributions among clients, known as the data heterogeneity problem. Most existing solutions suffer from two problems: (1) The typical optimizer based on empirical risk minimization tends to cause local models to fall into sharp valleys and weakens their generalization to out-of-distribution graph data. (2) The prevalent dimensional collapse in the learned representations of local graph data has an adverse impact on the classification capacity of the GNN model. To this end, we formulate a novel optimization objective that is aware of the sharpness (i.e., the curvature of the loss surface) of local GNN models. By minimizing the loss function and its sharpness simultaneously, we seek out model parameters in a flat region with uniformly low loss values, thus improving the generalization over heterogeneous data. By introducing a regularizer based on the correlation matrix of local representations, we relax the correlations of representations generated by individual local graph samples, so as to alleviate the dimensional collapse of the learned model. The proposed \textbf{S}harpness-aware f\textbf{E}derated gr\textbf{A}ph \textbf{L}earning (SEAL) algorithm can enhance the classification accuracy and generalization ability of local GNN models in federated graph learning. Experimental studies on several graph classification benchmarks show that SEAL consistently outperforms SOTA FGL baselines and provides gains for more participants.
Laplacian Analysis Meets Dynamics Modelling: Gaussian Splatting for 4D Reconstruction
Aug 07, 2025



While 3D Gaussian Splatting (3DGS) excels in static scene modeling, its extension to dynamic scenes introduces significant challenges. Existing dynamic 3DGS methods suffer from either over-smoothing due to low-rank decomposition or feature collision from high-dimensional grid sampling. This is because of the inherent spectral conflicts between preserving motion details and maintaining deformation consistency at different frequency. To address these challenges, we propose a novel dynamic 3DGS framework with hybrid explicit-implicit functions. Our approach contains three key innovations: a spectral-aware Laplacian encoding architecture which merges Hash encoding and Laplacian-based module for flexible frequency motion control, an enhanced Gaussian dynamics attribute that compensates for photometric distortions caused by geometric deformation, and an adaptive Gaussian split strategy guided by KDTree-based primitive control to efficiently query and optimize dynamic areas. Through extensive experiments, our method demonstrates state-of-the-art performance in reconstructing complex dynamic scenes, achieving better reconstruction fidelity.
Self-Bootstrapping for Versatile Test-Time Adaptation
Apr 10, 2025In this paper, we seek to develop a versatile test-time adaptation (TTA) objective for a variety of tasks - classification and regression across image-, object-, and pixel-level predictions. We achieve this through a self-bootstrapping scheme that optimizes prediction consistency between the test image (as target) and its deteriorated view. The key challenge lies in devising effective augmentations/deteriorations that: i) preserve the image's geometric information, e.g., object sizes and locations, which is crucial for TTA on object/pixel-level tasks, and ii) provide sufficient learning signals for TTA. To this end, we analyze how common distribution shifts affect the image's information power across spatial frequencies in the Fourier domain, and reveal that low-frequency components carry high power and masking these components supplies more learning signals, while masking high-frequency components can not. In light of this, we randomly mask the low-frequency amplitude of an image in its Fourier domain for augmentation. Meanwhile, we also augment the image with noise injection to compensate for missing learning signals at high frequencies, by enhancing the information power there. Experiments show that, either independently or as a plug-and-play module, our method achieves superior results across classification, segmentation, and 3D monocular detection tasks with both transformer and CNN models.
Continual Optimization with Symmetry Teleportation for Multi-Task Learning
Mar 06, 2025



Multi-task learning (MTL) is a widely explored paradigm that enables the simultaneous learning of multiple tasks using a single model. Despite numerous solutions, the key issues of optimization conflict and task imbalance remain under-addressed, limiting performance. Unlike existing optimization-based approaches that typically reweight task losses or gradients to mitigate conflicts or promote progress, we propose a novel approach based on Continual Optimization with Symmetry Teleportation (COST). During MTL optimization, when an optimization conflict arises, we seek an alternative loss-equivalent point on the loss landscape to reduce conflict. Specifically, we utilize a low-rank adapter (LoRA) to facilitate this practical teleportation by designing convergent, loss-invariant objectives. Additionally, we introduce a historical trajectory reuse strategy to continually leverage the benefits of advanced optimizers. Extensive experiments on multiple mainstream datasets demonstrate the effectiveness of our approach. COST is a plug-and-play solution that enhances a wide range of existing MTL methods. When integrated with state-of-the-art methods, COST achieves superior performance.
Audio-Reasoner: Improving Reasoning Capability in Large Audio Language Models
Mar 04, 2025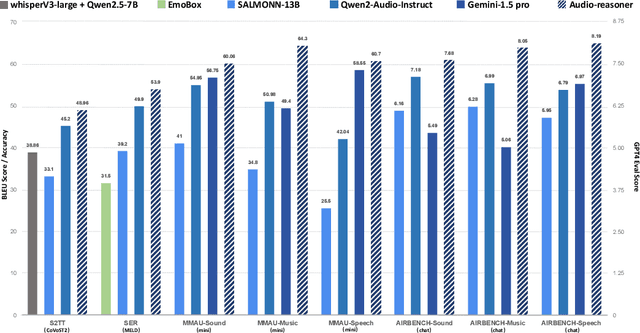
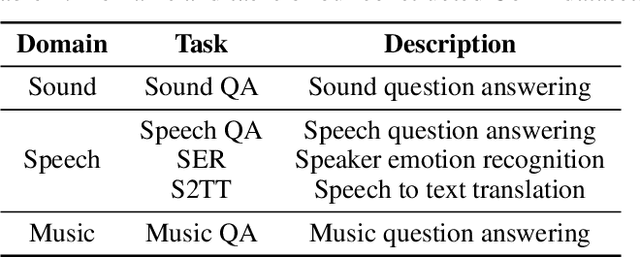
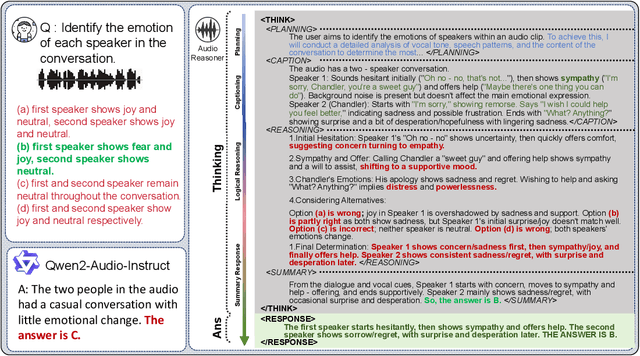

Recent advancements in multimodal reasoning have largely overlooked the audio modality. We introduce Audio-Reasoner, a large-scale audio language model for deep reasoning in audio tasks. We meticulously curated a large-scale and diverse multi-task audio dataset with simple annotations. Then, we leverage closed-source models to conduct secondary labeling, QA generation, along with structured COT process. These datasets together form a high-quality reasoning dataset with 1.2 million reasoning-rich samples, which we name CoTA. Following inference scaling principles, we train Audio-Reasoner on CoTA, enabling it to achieve great logical capabilities in audio reasoning. Experiments show state-of-the-art performance across key benchmarks, including MMAU-mini (+25.42%), AIR-Bench chat/foundation(+14.57%/+10.13%), and MELD (+8.01%). Our findings stress the core of structured CoT training in advancing audio reasoning.
HDT: Hierarchical Discrete Transformer for Multivariate Time Series Forecasting
Feb 12, 2025Generative models have gained significant attention in multivariate time series forecasting (MTS), particularly due to their ability to generate high-fidelity samples. Forecasting the probability distribution of multivariate time series is a challenging yet practical task. Although some recent attempts have been made to handle this task, two major challenges persist: 1) some existing generative methods underperform in high-dimensional multivariate time series forecasting, which is hard to scale to higher dimensions; 2) the inherent high-dimensional multivariate attributes constrain the forecasting lengths of existing generative models. In this paper, we point out that discrete token representations can model high-dimensional MTS with faster inference time, and forecasting the target with long-term trends of itself can extend the forecasting length with high accuracy. Motivated by this, we propose a vector quantized framework called Hierarchical Discrete Transformer (HDT) that models time series into discrete token representations with l2 normalization enhanced vector quantized strategy, in which we transform the MTS forecasting into discrete tokens generation. To address the limitations of generative models in long-term forecasting, we propose a hierarchical discrete Transformer. This model captures the discrete long-term trend of the target at the low level and leverages this trend as a condition to generate the discrete representation of the target at the high level that introduces the features of the target itself to extend the forecasting length in high-dimensional MTS. Extensive experiments on five popular MTS datasets verify the effectiveness of our proposed method.
Test-Time Model Adaptation with Only Forward Passes
Apr 02, 2024



Test-time adaptation has proven effective in adapting a given trained model to unseen test samples with potential distribution shifts. However, in real-world scenarios, models are usually deployed on resource-limited devices, e.g., FPGAs, and are often quantized and hard-coded with non-modifiable parameters for acceleration. In light of this, existing methods are often infeasible since they heavily depend on computation-intensive backpropagation for model updating that may be not supported. To address this, we propose a test-time Forward-Only Adaptation (FOA) method. In FOA, we seek to solely learn a newly added prompt (as model's input) via a derivative-free covariance matrix adaptation evolution strategy. To make this strategy work stably under our online unsupervised setting, we devise a novel fitness function by measuring test-training statistic discrepancy and model prediction entropy. Moreover, we design an activation shifting scheme that directly tunes the model activations for shifted test samples, making them align with the source training domain, thereby further enhancing adaptation performance. Without using any backpropagation and altering model weights, FOA runs on quantized 8-bit ViT outperforms gradient-based TENT on full-precision 32-bit ViT, while achieving an up to 24-fold memory reduction on ImageNet-C. The source code will be released.