 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAAS: Self-Aware Reinforcement Learning for Over-Search Mitigation in Agentic Search
May 28, 2026Agentic search enables LLMs to solve complex multi-hop questions through iterative reasoning and external search. Despite the effectiveness, these systems often suffer from a critical limitation in practice: agents fail to recognize their own knowledge boundaries, blindly triggering searches when internal knowledge suffices and failing to terminate search even when adequate evidence has been collected. The lack of self-awareness leads to severe \textbf{over-search}, incurring substantial inference latency and prohibitive computational cost. To this end, we propose SAAS, a novel RL framework designed to cultivate dynamic self-awareness that precisely regulates search behavior without compromising accuracy. SAAS introduces three key components: (i) a search boundary modeling mechanism, which identifies the search boundary under the evolving policy by contrasting search-disabled and search-enabled rollouts; (ii) a boundary-aware reward module, which translates this boundary awareness into trajectory-level penalties, suppressing unnecessary and redundant searches; and (iii) a stage-wise optimization strategy, which leverages a sequential curriculum to prioritize reasoning over search regularization, thereby avoiding reward hacking. Extensive experiments demonstrate that SAAS substantially reduces over-search, while maintaining accuracy. Our code is anonymously released at https://github.com/XMUDeepLIT/SAAS.
On the Robustness of Machine Unlearning for Vision-Language Models
May 26, 2026Vision-language models (VLMs) may memorize undesirable information from training data, motivating growing interest in machine unlearning. In this work, we present the first systematic survey and robustness analysis of VLM unlearning. We provide a comprehensive taxonomy and review of existing VLM unlearning methods, together with unified evaluations under multiple prompt settings. We then propose three attack paradigms to examine whether forgotten multimodal knowledge can be reactivated through contextual prompting or downstream retraining. Extensive experiments show that many existing methods remain vulnerable under these attacks, indicating that current approaches often hide rather than fully remove target knowledge. Our study provides new insights into the robustness and limitations of current VLM unlearning methods and highlights the need for more reliable multimodal unlearning strategies. Code is available at https://github.com/XMUDeepLIT/VLM-UnL-Attack.
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
SCMAPR: Self-Correcting Multi-Agent Prompt Refinement for Complex-Scenario Text-to-Video Generation
Apr 07, 2026Text-to-Video (T2V) generation has benefited from recent advances in diffusion models, yet current systems still struggle under complex scenarios, which are generally exacerbated by the ambiguity and underspecification of text prompts. In this work, we formulate complex-scenario prompt refinement as a stage-wise multi-agent refinement process and propose SCMAPR, i.e., a scenario-aware and Self-Correcting Multi-Agent Prompt Refinement framework for T2V prompting. SCMAPR coordinates specialized agents to (i) route each prompt to a taxonomy-grounded scenario for strategy selection, (ii) synthesize scenario-aware rewriting policies and perform policy-conditioned refinement, and (iii) conduct structured semantic verification that triggers conditional revision when violations are detected. To clarify what constitutes complex scenarios in T2V prompting, provide representative examples, and enable rigorous evaluation under such challenging conditions, we further introduce {T2V-Complexity}, which is a complex-scenario T2V benchmark consisting exclusively of complex-scenario prompts. Extensive experiments on 3 existing benchmarks and our T2V-Complexity benchmark demonstrate that SCMAPR consistently improves text-video alignment and overall generation quality under complex scenarios, achieving up to 2.67\% and 3.28 gains in average score on VBench and EvalCrafter, and up to 0.028 improvement on T2V-CompBench over 3 State-Of-The-Art baselines.
TTCS: Test-Time Curriculum Synthesis for Self-Evolving
Jan 30, 2026Test-Time Training offers a promising way to improve the reasoning ability of large language models (LLMs) by adapting the model using only the test questions. However, existing methods struggle with difficult reasoning problems for two reasons: raw test questions are often too difficult to yield high-quality pseudo-labels, and the limited size of test sets makes continuous online updates prone to instability. To address these limitations, we propose TTCS, a co-evolving test-time training framework. Specifically, TTCS initializes two policies from the same pretrained model: a question synthesizer and a reasoning solver. These policies evolve through iterative optimization: the synthesizer generates progressively challenging question variants conditioned on the test questions, creating a structured curriculum tailored to the solver's current capability, while the solver updates itself using self-consistency rewards computed from multiple sampled responses on both original test and synthetic questions. Crucially, the solver's feedback guides the synthesizer to generate questions aligned with the model's current capability, and the generated question variants in turn stabilize the solver's test-time training. Experiments show that TTCS consistently strengthens the reasoning ability on challenging mathematical benchmarks and transfers to general-domain tasks across different LLM backbones, highlighting a scalable path towards dynamically constructing test-time curricula for self-evolving. Our code and implementation details are available at https://github.com/XMUDeepLIT/TTCS.
EffiCANet: Efficient Time Series Forecasting with Convolutional Attention
Nov 07, 2024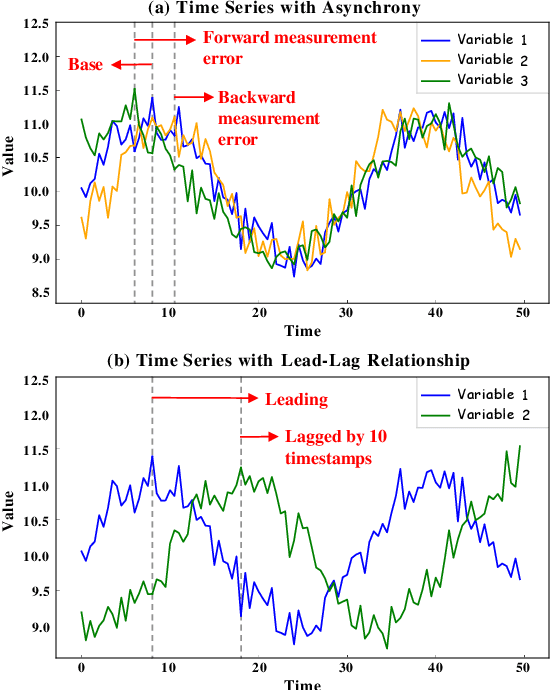
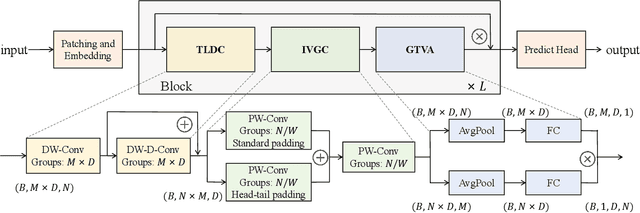

The exponential growth of multivariate time series data from sensor networks in domains like industrial monitoring and smart cities requires efficient and accurate forecasting models. Current deep learning methods often fail to adequately capture long-range dependencies and complex inter-variable relationships, especially under real-time processing constraints. These limitations arise as many models are optimized for either short-term forecasting with limited receptive fields or long-term accuracy at the cost of efficiency. Additionally, dynamic and intricate interactions between variables in real-world data further complicate modeling efforts. To address these limitations, we propose EffiCANet, an Efficient Convolutional Attention Network designed to enhance forecasting accuracy while maintaining computational efficiency. EffiCANet integrates three key components: (1) a Temporal Large-kernel Decomposed Convolution (TLDC) module that captures long-term temporal dependencies while reducing computational overhead; (2) an Inter-Variable Group Convolution (IVGC) module that captures complex and evolving relationships among variables; and (3) a Global Temporal-Variable Attention (GTVA) mechanism that prioritizes critical temporal and inter-variable features. Extensive evaluations across nine benchmark datasets show that EffiCANet achieves the maximum reduction of 10.02% in MAE over state-of-the-art models, while cutting computational costs by 26.2% relative to conventional large-kernel convolution methods, thanks to its efficient decomposition strategy.
Towards Universal Large-Scale Foundational Model for Natural Gas Demand Forecasting
Sep 24, 2024



In the context of global energy strategy, accurate natural gas demand forecasting is crucial for ensuring efficient resource allocation and operational planning. Traditional forecasting methods struggle to cope with the growing complexity and variability of gas consumption patterns across diverse industries and commercial sectors. To address these challenges, we propose the first foundation model specifically tailored for natural gas demand forecasting. Foundation models, known for their ability to generalize across tasks and datasets, offer a robust solution to the limitations of traditional methods, such as the need for separate models for different customer segments and their limited generalization capabilities. Our approach leverages contrastive learning to improve prediction accuracy in real-world scenarios, particularly by tackling issues such as noise in historical consumption data and the potential misclassification of similar data samples, which can lead to degradation in the quaility of the representation and thus the accuracy of downstream forecasting tasks. By integrating advanced noise filtering techniques within the contrastive learning framework, our model enhances the quality of learned representations, leading to more accurate predictions. Furthermore, the model undergoes industry-specific fine-tuning during pretraining, enabling it to better capture the unique characteristics of gas consumption across various sectors. We conducted extensive experiments using a large-scale dataset from ENN Group, which includes data from over 10,000 industrial, commercial, and welfare-related customers across multiple regions. Our model outperformed existing state-of-the-art methods, demonstrating a relative improvement in MSE by 3.68\% and in MASE by 6.15\% compared to the best available model.
Towards Better Graph-based Cross-document Relation Extraction via Non-bridge Entity Enhancement and Prediction Debiasing
Jun 24, 2024



Cross-document Relation Extraction aims to predict the relation between target entities located in different documents. In this regard, the dominant models commonly retain useful information for relation prediction via bridge entities, which allows the model to elaborately capture the intrinsic interdependence between target entities. However, these studies ignore the non-bridge entities, each of which co-occurs with only one target entity and offers the semantic association between target entities for relation prediction. Besides, the commonly-used dataset--CodRED contains substantial NA instances, leading to the prediction bias during inference. To address these issues, in this paper, we propose a novel graph-based cross-document RE model with non-bridge entity enhancement and prediction debiasing. Specifically, we use a unified entity graph to integrate numerous non-bridge entities with target entities and bridge entities, modeling various associations between them, and then use a graph recurrent network to encode this graph. Finally, we introduce a novel debiasing strategy to calibrate the original prediction distribution. Experimental results on the closed and open settings show that our model significantly outperforms all baselines, including the GPT-3.5-turbo and InstructUIE, achieving state-of-the-art performance. Particularly, our model obtains 66.23% and 55.87% AUC points in the official leaderboard\footnote{\url{https://codalab.lisn.upsaclay.fr/competitions/3770#results}} under the two settings, respectively, ranking the first place in all submissions since December 2023. Our code is available at https://github.com/DeepLearnXMU/CoRE-NEPD.
Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal
Mar 02, 2024



Large language models (LLMs) suffer from catastrophic forgetting during continual learning. Conventional rehearsal-based methods rely on previous training data to retain the model's ability, which may not be feasible in real-world applications. When conducting continual learning based on a publicly-released LLM checkpoint, the availability of the original training data may be non-existent. To address this challenge, we propose a framework called Self-Synthesized Rehearsal (SSR) that uses the LLM to generate synthetic instances for rehearsal. Concretely, we first employ the base LLM for in-context learning to generate synthetic instances. Subsequently, we utilize the latest LLM to refine the instance outputs based on the synthetic inputs, preserving its acquired ability. Finally, we select diverse high-quality synthetic instances for rehearsal in future stages. Experimental results demonstrate that SSR achieves superior or comparable performance compared to conventional rehearsal-based approaches while being more data-efficient. Besides, SSR effectively preserves the generalization capabilities of LLMs in general domains.
Wasserstein Differential Privacy
Jan 23, 2024Differential privacy (DP) has achieved remarkable results in the field of privacy-preserving machine learning. However, existing DP frameworks do not satisfy all the conditions for becoming metrics, which prevents them from deriving better basic private properties and leads to exaggerated values on privacy budgets. We propose Wasserstein differential privacy (WDP), an alternative DP framework to measure the risk of privacy leakage, which satisfies the properties of symmetry and triangle inequality. We show and prove that WDP has 13 excellent properties, which can be theoretical supports for the better performance of WDP than other DP frameworks. In addition, we derive a general privacy accounting method called Wasserstein accountant, which enables WDP to be applied in stochastic gradient descent (SGD) scenarios containing sub-sampling. Experiments on basic mechanisms, compositions and deep learning show that the privacy budgets obtained by Wasserstein accountant are relatively stable and less influenced by order. Moreover, the overestimation on privacy budgets can be effectively alleviated. The code is available at https://github.com/Hifipsysta/WDP.