 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learning Rate Path Switching Training Paradigm for Version Updates of Large Language Models
Oct 05, 2024
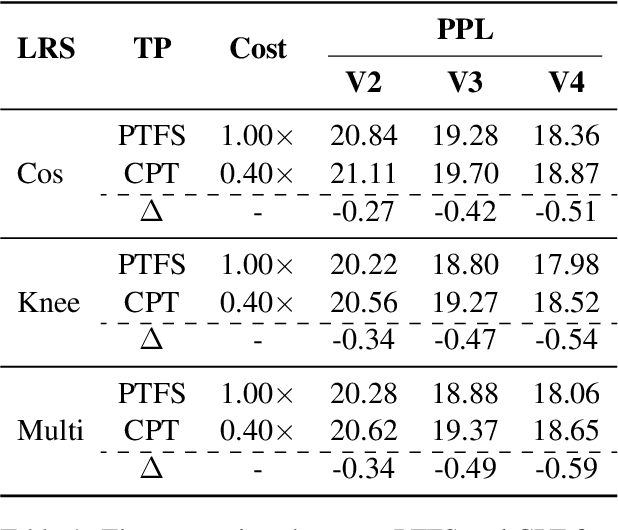


Due to the continuous emergence of new data, version updates have become an indispensable requirement for Large Language Models (LLMs). The training paradigms for version updates of LLMs include pre-training from scratch (PTFS) and continual pre-training (CPT). Preliminary experiments demonstrate that PTFS achieves better pre-training performance, while CPT has lower training cost. Moreover, their performance and training cost gaps widen progressively with version updates. To investigate the underlying reasons for this phenomenon, we analyze the effect of learning rate adjustments during the two stages of CPT: preparing an initialization checkpoint and continual pre-training based on this checkpoint. We find that a large learning rate in the first stage and a complete learning rate decay process in the second stage are crucial for version updates of LLMs. Hence, we propose a learning rate path switching training paradigm. Our paradigm comprises one main path, where we pre-train a LLM with the maximal learning rate, and multiple branching paths, each of which corresponds to an update of the LLM with newly-added training data. Extensive experiments demonstrate the effectiveness and generalization of our paradigm. Particularly, when training four versions of LLMs, our paradigm reduces the total training cost to 58% compared to PTFS, while maintaining comparable pre-training performance.
Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal
Mar 02, 2024



Large language models (LLMs) suffer from catastrophic forgetting during continual learning. Conventional rehearsal-based methods rely on previous training data to retain the model's ability, which may not be feasible in real-world applications. When conducting continual learning based on a publicly-released LLM checkpoint, the availability of the original training data may be non-existent. To address this challenge, we propose a framework called Self-Synthesized Rehearsal (SSR) that uses the LLM to generate synthetic instances for rehearsal. Concretely, we first employ the base LLM for in-context learning to generate synthetic instances. Subsequently, we utilize the latest LLM to refine the instance outputs based on the synthetic inputs, preserving its acquired ability. Finally, we select diverse high-quality synthetic instances for rehearsal in future stages. Experimental results demonstrate that SSR achieves superior or comparable performance compared to conventional rehearsal-based approaches while being more data-efficient. Besides, SSR effectively preserves the generalization capabilities of LLMs in general domains.
Response Enhanced Semi-Supervised Dialogue Query Generation
Dec 20, 2023Leveraging vast and continually updated knowledge from the Internet has been considered an important ability for a dialogue system. Therefore, the dialogue query generation task is proposed for generating search queries from dialogue histories, which will be submitted to a search engine for retrieving relevant websites on the Internet. In this regard, previous efforts were devoted to collecting conversations with annotated queries and training a query producer (QP) via standard supervised learning. However, these studies still face the challenges of data scarcity and domain adaptation. To address these issues, in this paper, we propose a semi-supervised learning framework -- SemiDQG, to improve model performance with unlabeled conversations. Based on the observation that the search query is typically related to the topic of dialogue response, we train a response-augmented query producer (RA) to provide rich and effective training signals for QP. We first apply a similarity-based query selection strategy to select high-quality RA-generated pseudo queries, which are used to construct pseudo instances for training QP and RA. Then, we adopt the REINFORCE algorithm to further enhance QP, with RA-provided rewards as fine-grained training signals. Experimental results and in-depth analysis of three benchmarks show the effectiveness of our framework in cross-domain and low-resource scenarios. Particularly, SemiDQG significantly surpasses ChatGPT and competitive baselines. Our code is available at \url{https://github.com/DeepLearnXMU/SemiDQG}.