 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRVCBench: Benchmarking the Robustness of Voice Cloning Across Modern Audio Generation Models
Jan 31, 2026Modern voice cloning (VC) can synthesize speech that closely matches a target speaker from only seconds of reference audio, enabling applications such as personalized speech interfaces and dubbing. In practical deployments, modern audio generation models inevitably encounter noisy reference audios, imperfect text prompts, and diverse downstream processing, which can significantly hurt robustness. Despite rapid progress in VC driven by autoregressive codec-token language models and diffusion-based models, robustness under realistic deployment shifts remains underexplored. This paper introduces RVCBench, a comprehensive benchmark that evaluates Robustness in VC across the full generation pipeline, including input variation, generation challenges, output post-processing, and adversarial perturbations, covering 10 robustness tasks, 225 speakers, 14,370 utterances, and 11 representative modern VC models. Our evaluation uncovers substantial robustness gaps in VC: performance can deteriorate sharply under common input shifts and post-processing; long-context and cross-lingual scenarios further expose stability limitations; and both passive noise and proactive perturbation influence generation robustness. Collectively, these findings provide a unified picture of how current VC models fail in practice and introduce a standardized, open-source testbed to support the development of more robust and deployable VC models. We open-source our project at https://github.com/Nanboy-Ronan/RVCBench.
When RAG Hurts: Diagnosing and Mitigating Attention Distraction in Retrieval-Augmented LVLMs
Jan 30, 2026While Retrieval-Augmented Generation (RAG) is one of the dominant paradigms for enhancing Large Vision-Language Models (LVLMs) on knowledge-based VQA tasks, recent work attributes RAG failures to insufficient attention towards the retrieved context, proposing to reduce the attention allocated to image tokens. In this work, we identify a distinct failure mode that previous study overlooked: Attention Distraction (AD). When the retrieved context is sufficient (highly relevant or including the correct answer), the retrieved text suppresses the visual attention globally, and the attention on image tokens shifts away from question-relevant regions. This leads to failures on questions the model could originally answer correctly without the retrieved text. To mitigate this issue, we propose MAD-RAG, a training-free intervention that decouples visual grounding from context integration through a dual-question formulation, combined with attention mixing to preserve image-conditioned evidence. Extensive experiments on OK-VQA, E-VQA, and InfoSeek demonstrate that MAD-RAG consistently outperforms existing baselines across different model families, yielding absolute gains of up to 4.76%, 9.20%, and 6.18% over the vanilla RAG baseline. Notably, MAD-RAG rectifies up to 74.68% of failure cases with negligible computational overhead.
Joint Similarity Item Exploration and Overlapped User Guidance for Multi-Modal Cross-Domain Recommendation
Feb 22, 2025Cross-Domain Recommendation (CDR) has been widely investigated for solving long-standing data sparsity problem via knowledge sharing across domains. In this paper, we focus on the Multi-Modal Cross-Domain Recommendation (MMCDR) problem where different items have multi-modal information while few users are overlapped across domains. MMCDR is particularly challenging in two aspects: fully exploiting diverse multi-modal information within each domain and leveraging useful knowledge transfer across domains. However, previous methods fail to cluster items with similar characteristics while filtering out inherit noises within different modalities, hurdling the model performance. What is worse, conventional CDR models primarily rely on overlapped users for domain adaptation, making them ill-equipped to handle scenarios where the majority of users are non-overlapped. To fill this gap, we propose Joint Similarity Item Exploration and Overlapped User Guidance (SIEOUG) for solving the MMCDR problem. SIEOUG first proposes similarity item exploration module, which not only obtains pair-wise and group-wise item-item graph knowledge, but also reduces irrelevant noise for multi-modal modeling. Then SIEOUG proposes user-item collaborative filtering module to aggregate user/item embeddings with the attention mechanism for collaborative filtering. Finally SIEOUG proposes overlapped user guidance module with optimal user matching for knowledge sharing across domains. Our empirical study on Amazon dataset with several different tasks demonstrates that SIEOUG significantly outperforms the state-of-the-art models under the MMCDR setting.
FOOGD: Federated Collaboration for Both Out-of-distribution Generalization and Detection
Oct 15, 2024



Federated learning (FL) is a promising machine learning paradigm that collaborates with client models to capture global knowledge. However, deploying FL models in real-world scenarios remains unreliable due to the coexistence of in-distribution data and unexpected out-of-distribution (OOD) data, such as covariate-shift and semantic-shift data. Current FL researches typically address either covariate-shift data through OOD generalization or semantic-shift data via OOD detection, overlooking the simultaneous occurrence of various OOD shifts. In this work, we propose FOOGD, a method that estimates the probability density of each client and obtains reliable global distribution as guidance for the subsequent FL process. Firstly, SM3D in FOOGD estimates score model for arbitrary distributions without prior constraints, and detects semantic-shift data powerfully. Then SAG in FOOGD provides invariant yet diverse knowledge for both local covariate-shift generalization and client performance generalization. In empirical validations, FOOGD significantly enjoys three main advantages: (1) reliably estimating non-normalized decentralized distributions, (2) detecting semantic shift data via score values, and (3) generalizing to covariate-shift data by regularizing feature extractor. The prejoct is open in https://github.com/XeniaLLL/FOOGD-main.git.
Rethinking the Representation in Federated Unsupervised Learning with Non-IID Data
Mar 25, 2024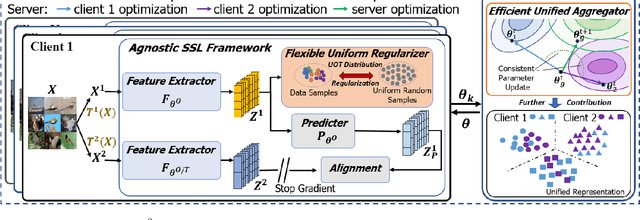
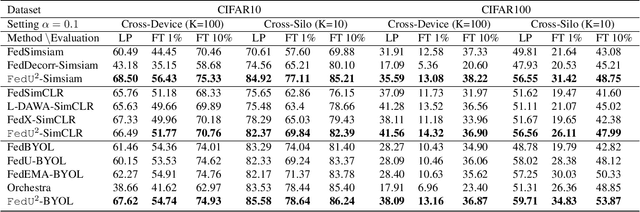

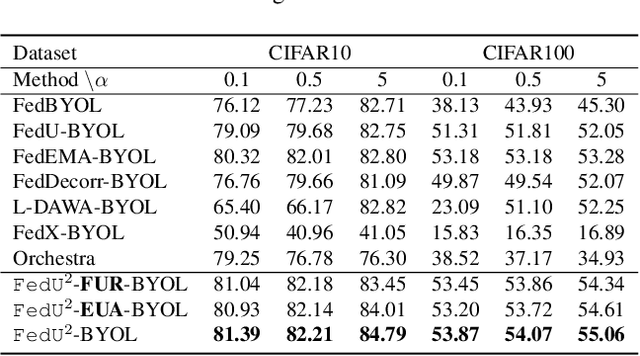
Federated learning achieves effective performance in modeling decentralized data. In practice, client data are not well-labeled, which makes it potential for federated unsupervised learning (FUSL) with non-IID data. However, the performance of existing FUSL methods suffers from insufficient representations, i.e., (1) representation collapse entanglement among local and global models, and (2) inconsistent representation spaces among local models. The former indicates that representation collapse in local model will subsequently impact the global model and other local models. The latter means that clients model data representation with inconsistent parameters due to the deficiency of supervision signals. In this work, we propose FedU2 which enhances generating uniform and unified representation in FUSL with non-IID data. Specifically, FedU2 consists of flexible uniform regularizer (FUR) and efficient unified aggregator (EUA). FUR in each client avoids representation collapse via dispersing samples uniformly, and EUA in server promotes unified representation by constraining consistent client model updating. To extensively validate the performance of FedU2, we conduct both cross-device and cross-silo evaluation experiments on two benchmark datasets, i.e., CIFAR10 and CIFAR100.
Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal
Mar 02, 2024



Large language models (LLMs) suffer from catastrophic forgetting during continual learning. Conventional rehearsal-based methods rely on previous training data to retain the model's ability, which may not be feasible in real-world applications. When conducting continual learning based on a publicly-released LLM checkpoint, the availability of the original training data may be non-existent. To address this challenge, we propose a framework called Self-Synthesized Rehearsal (SSR) that uses the LLM to generate synthetic instances for rehearsal. Concretely, we first employ the base LLM for in-context learning to generate synthetic instances. Subsequently, we utilize the latest LLM to refine the instance outputs based on the synthetic inputs, preserving its acquired ability. Finally, we select diverse high-quality synthetic instances for rehearsal in future stages. Experimental results demonstrate that SSR achieves superior or comparable performance compared to conventional rehearsal-based approaches while being more data-efficient. Besides, SSR effectively preserves the generalization capabilities of LLMs in general domains.
Learning Uniform Clusters on Hypersphere for Deep Graph-level Clustering
Nov 23, 2023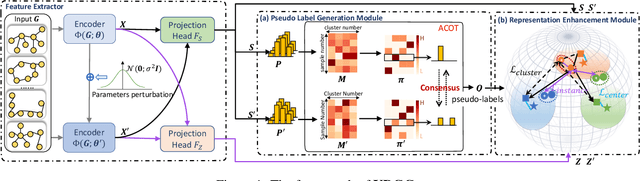



Graph clustering has been popularly studied in recent years. However, most existing graph clustering methods focus on node-level clustering, i.e., grouping nodes in a single graph into clusters. In contrast, graph-level clustering, i.e., grouping multiple graphs into clusters, remains largely unexplored. Graph-level clustering is critical in a variety of real-world applications, such as, properties prediction of molecules and community analysis in social networks. However, graph-level clustering is challenging due to the insufficient discriminability of graph-level representations, and the insufficient discriminability makes deep clustering be more likely to obtain degenerate solutions (cluster collapse). To address the issue, we propose a novel deep graph-level clustering method called Uniform Deep Graph Clustering (UDGC). UDGC assigns instances evenly to different clusters and then scatters those clusters on unit hypersphere, leading to a more uniform cluster-level distribution and a slighter cluster collapse. Specifically, we first propose Augmentation-Consensus Optimal Transport (ACOT) for generating uniformly distributed and reliable pseudo labels for partitioning clusters. Then we adopt contrastive learning to scatter those clusters. Besides, we propose Center Alignment Optimal Transport (CAOT) for guiding the model to learn better parameters, which further promotes the cluster performance. Our empirical study on eight well-known datasets demonstrates that UDGC significantly outperforms the state-of-the-art models.
Joint Local Relational Augmentation and Global Nash Equilibrium for Federated Learning with Non-IID Data
Aug 17, 2023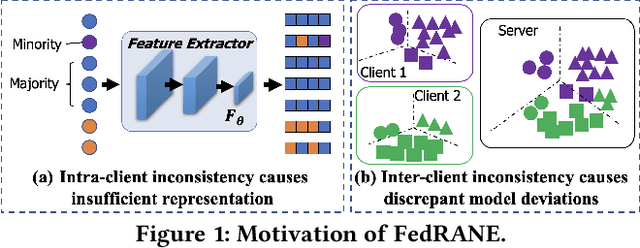
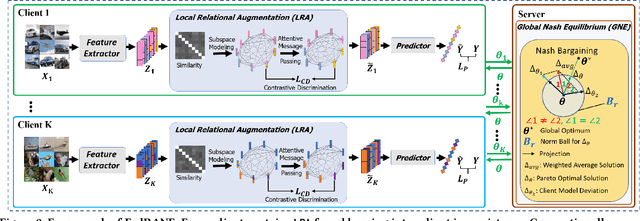
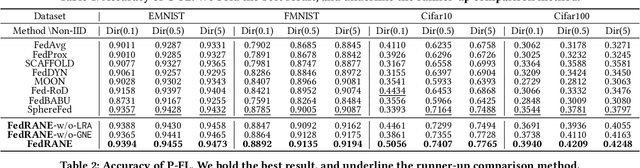
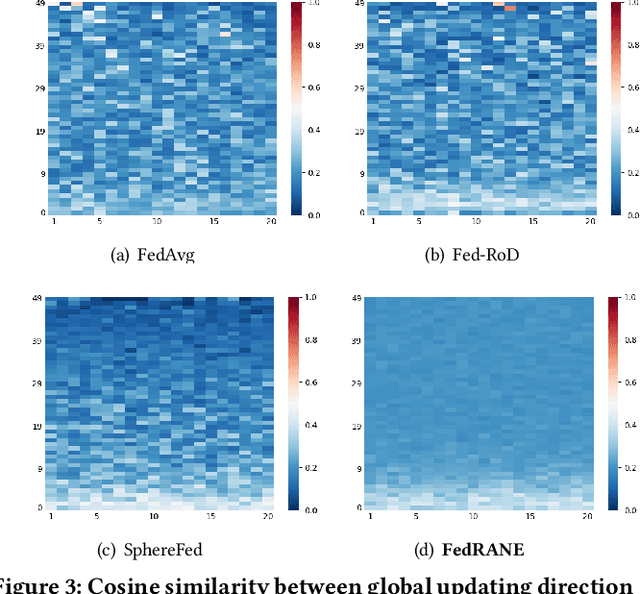
Federated learning (FL) is a distributed machine learning paradigm that needs collaboration between a server and a series of clients with decentralized data. To make FL effective in real-world applications, existing work devotes to improving the modeling of decentralized data with non-independent and identical distributions (non-IID). In non-IID settings, there are intra-client inconsistency that comes from the imbalanced data modeling, and inter-client inconsistency among heterogeneous client distributions, which not only hinders sufficient representation of the minority data, but also brings discrepant model deviations. However, previous work overlooks to tackle the above two coupling inconsistencies together. In this work, we propose FedRANE, which consists of two main modules, i.e., local relational augmentation (LRA) and global Nash equilibrium (GNE), to resolve intra- and inter-client inconsistency simultaneously. Specifically, in each client, LRA mines the similarity relations among different data samples and enhances the minority sample representations with their neighbors using attentive message passing. In server, GNE reaches an agreement among inconsistent and discrepant model deviations from clients to server, which encourages the global model to update in the direction of global optimum without breaking down the clients optimization toward their local optimums. We conduct extensive experiments on four benchmark datasets to show the superiority of FedRANE in enhancing the performance of FL with non-IID data.
HyperFed: Hyperbolic Prototypes Exploration with Consistent Aggregation for Non-IID Data in Federated Learning
Jul 26, 2023



Federated learning (FL) collaboratively models user data in a decentralized way. However, in the real world, non-identical and independent data distributions (non-IID) among clients hinder the performance of FL due to three issues, i.e., (1) the class statistics shifting, (2) the insufficient hierarchical information utilization, and (3) the inconsistency in aggregating clients. To address the above issues, we propose HyperFed which contains three main modules, i.e., hyperbolic prototype Tammes initialization (HPTI), hyperbolic prototype learning (HPL), and consistent aggregation (CA). Firstly, HPTI in the server constructs uniformly distributed and fixed class prototypes, and shares them with clients to match class statistics, further guiding consistent feature representation for local clients. Secondly, HPL in each client captures the hierarchical information in local data with the supervision of shared class prototypes in the hyperbolic model space. Additionally, CA in the server mitigates the impact of the inconsistent deviations from clients to server. Extensive studies of four datasets prove that HyperFed is effective in enhancing the performance of FL under the non-IID set.
Robust Representation Learning with Reliable Pseudo-labels Generation via Self-Adaptive Optimal Transport for Short Text Clustering
May 23, 2023



Short text clustering is challenging since it takes imbalanced and noisy data as inputs. Existing approaches cannot solve this problem well, since (1) they are prone to obtain degenerate solutions especially on heavy imbalanced datasets, and (2) they are vulnerable to noises. To tackle the above issues, we propose a Robust Short Text Clustering (RSTC) model to improve robustness against imbalanced and noisy data. RSTC includes two modules, i.e., pseudo-label generation module and robust representation learning module. The former generates pseudo-labels to provide supervision for the later, which contributes to more robust representations and correctly separated clusters. To provide robustness against the imbalance in data, we propose self-adaptive optimal transport in the pseudo-label generation module. To improve robustness against the noise in data, we further introduce both class-wise and instance-wise contrastive learning in the robust representation learning module. Our empirical studies on eight short text clustering datasets demonstrate that RSTC significantly outperforms the state-of-the-art models. The code is available at: https://github.com/hmllmh/RSTC.