 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe First MPDD Challenge: Multimodal Personality-aware Depression Detection
May 15, 2025
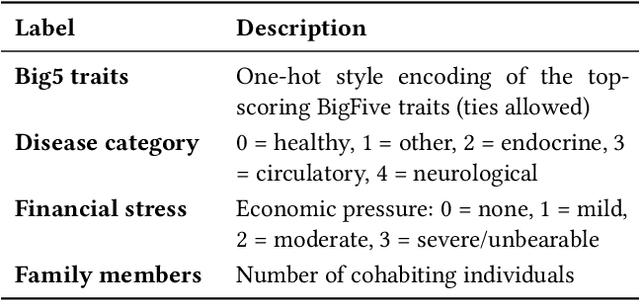


Depression is a widespread mental health issue affecting diverse age groups, with notable prevalence among college students and the elderly. However, existing datasets and detection methods primarily focus on young adults, neglecting the broader age spectrum and individual differences that influence depression manifestation. Current approaches often establish a direct mapping between multimodal data and depression indicators, failing to capture the complexity and diversity of depression across individuals. This challenge includes two tracks based on age-specific subsets: Track 1 uses the MPDD-Elderly dataset for detecting depression in older adults, and Track 2 uses the MPDD-Young dataset for detecting depression in younger participants. The Multimodal Personality-aware Depression Detection (MPDD) Challenge aims to address this gap by incorporating multimodal data alongside individual difference factors. We provide a baseline model that fuses audio and video modalities with individual difference information to detect depression manifestations in diverse populations. This challenge aims to promote the development of more personalized and accurate de pression detection methods, advancing mental health research and fostering inclusive detection systems. More details are available on the official challenge website: https://hacilab.github.io/MPDDChallenge.github.io.
Learnable Infinite Taylor Gaussian for Dynamic View Rendering
Dec 05, 2024



Capturing the temporal evolution of Gaussian properties such as position, rotation, and scale is a challenging task due to the vast number of time-varying parameters and the limited photometric data available, which generally results in convergence issues, making it difficult to find an optimal solution. While feeding all inputs into an end-to-end neural network can effectively model complex temporal dynamics, this approach lacks explicit supervision and struggles to generate high-quality transformation fields. On the other hand, using time-conditioned polynomial functions to model Gaussian trajectories and orientations provides a more explicit and interpretable solution, but requires significant handcrafted effort and lacks generalizability across diverse scenes. To overcome these limitations, this paper introduces a novel approach based on a learnable infinite Taylor Formula to model the temporal evolution of Gaussians. This method offers both the flexibility of an implicit network-based approach and the interpretability of explicit polynomial functions, allowing for more robust and generalizable modeling of Gaussian dynamics across various dynamic scenes. Extensive experiments on dynamic novel view rendering tasks are conducted on public datasets, demonstrating that the proposed method achieves state-of-the-art performance in this domain. More information is available on our project page(https://ellisonking.github.io/TaylorGaussian).
Not All Languages are Equal: Insights into Multilingual Retrieval-Augmented Generation
Oct 29, 2024



RALMs (Retrieval-Augmented Language Models) broaden their knowledge scope by incorporating external textual resources. However, the multilingual nature of global knowledge necessitates RALMs to handle diverse languages, a topic that has received limited research focus. In this work, we propose \textit{Futurepedia}, a carefully crafted benchmark containing parallel texts across eight representative languages. We evaluate six multilingual RALMs using our benchmark to explore the challenges of multilingual RALMs. Experimental results reveal linguistic inequalities: 1) high-resource languages stand out in Monolingual Knowledge Extraction; 2) Indo-European languages lead RALMs to provide answers directly from documents, alleviating the challenge of expressing answers across languages; 3) English benefits from RALMs' selection bias and speaks louder in multilingual knowledge selection. Based on these findings, we offer advice for improving multilingual Retrieval Augmented Generation. For monolingual knowledge extraction, careful attention must be paid to cascading errors from translating low-resource languages into high-resource ones. In cross-lingual knowledge transfer, encouraging RALMs to provide answers within documents in different languages can improve transfer performance. For multilingual knowledge selection, incorporating more non-English documents and repositioning English documents can help mitigate RALMs' selection bias. Through comprehensive experiments, we underscore the complexities inherent in multilingual RALMs and offer valuable insights for future research.
A Learning Rate Path Switching Training Paradigm for Version Updates of Large Language Models
Oct 05, 2024
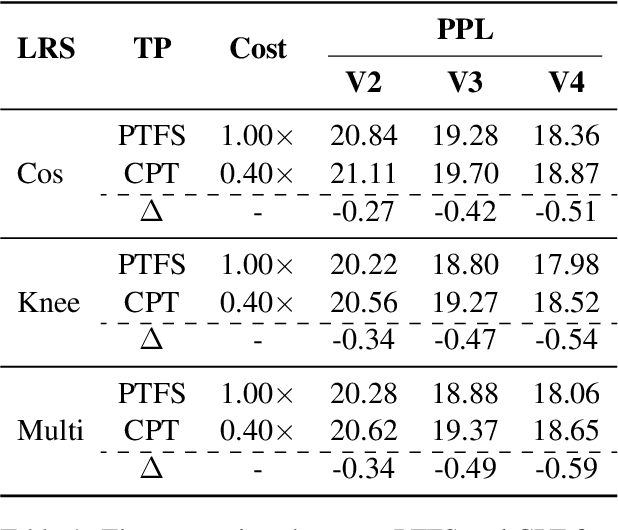


Due to the continuous emergence of new data, version updates have become an indispensable requirement for Large Language Models (LLMs). The training paradigms for version updates of LLMs include pre-training from scratch (PTFS) and continual pre-training (CPT). Preliminary experiments demonstrate that PTFS achieves better pre-training performance, while CPT has lower training cost. Moreover, their performance and training cost gaps widen progressively with version updates. To investigate the underlying reasons for this phenomenon, we analyze the effect of learning rate adjustments during the two stages of CPT: preparing an initialization checkpoint and continual pre-training based on this checkpoint. We find that a large learning rate in the first stage and a complete learning rate decay process in the second stage are crucial for version updates of LLMs. Hence, we propose a learning rate path switching training paradigm. Our paradigm comprises one main path, where we pre-train a LLM with the maximal learning rate, and multiple branching paths, each of which corresponds to an update of the LLM with newly-added training data. Extensive experiments demonstrate the effectiveness and generalization of our paradigm. Particularly, when training four versions of LLMs, our paradigm reduces the total training cost to 58% compared to PTFS, while maintaining comparable pre-training performance.
Mitigating the Negative Impact of Over-association for Conversational Query Production
Sep 29, 2024



Conversational query generation aims at producing search queries from dialogue histories, which are then used to retrieve relevant knowledge from a search engine to help knowledge-based dialogue systems. Trained to maximize the likelihood of gold queries, previous models suffer from the data hunger issue, and they tend to both drop important concepts from dialogue histories and generate irrelevant concepts at inference time. We attribute these issues to the over-association phenomenon where a large number of gold queries are indirectly related to the dialogue topics, because annotators may unconsciously perform reasoning with their background knowledge when generating these gold queries. We carefully analyze the negative effects of this phenomenon on pretrained Seq2seq query producers and then propose effective instance-level weighting strategies for training to mitigate these issues from multiple perspectives. Experiments on two benchmarks, Wizard-of-Internet and DuSinc, show that our strategies effectively alleviate the negative effects and lead to significant performance gains (2%-5% across automatic metrics and human evaluation). Further analysis shows that our model selects better concepts from dialogue histories and is 10 times more data efficient than the baseline. The code is available at https://github.com/DeepLearnXMU/QG-OverAsso.
Audio-driven High-resolution Seamless Talking Head Video Editing via StyleGAN
Jul 08, 2024



The existing methods for audio-driven talking head video editing have the limitations of poor visual effects. This paper tries to tackle this problem through editing talking face images seamless with different emotions based on two modules: (1) an audio-to-landmark module, consisting of the CrossReconstructed Emotion Disentanglement and an alignment network module. It bridges the gap between speech and facial motions by predicting corresponding emotional landmarks from speech; (2) a landmark-based editing module edits face videos via StyleGAN. It aims to generate the seamless edited video consisting of the emotion and content components from the input audio. Extensive experiments confirm that compared with state-of-the-arts methods, our method provides high-resolution videos with high visual quality.
SurgicalGaussian: Deformable 3D Gaussians for High-Fidelity Surgical Scene Reconstruction
Jul 06, 2024



Dynamic reconstruction of deformable tissues in endoscopic video is a key technology for robot-assisted surgery. Recent reconstruction methods based on neural radiance fields (NeRFs) have achieved remarkable results in the reconstruction of surgical scenes. However, based on implicit representation, NeRFs struggle to capture the intricate details of objects in the scene and cannot achieve real-time rendering. In addition, restricted single view perception and occluded instruments also propose special challenges in surgical scene reconstruction. To address these issues, we develop SurgicalGaussian, a deformable 3D Gaussian Splatting method to model dynamic surgical scenes. Our approach models the spatio-temporal features of soft tissues at each time stamp via a forward-mapping deformation MLP and regularization to constrain local 3D Gaussians to comply with consistent movement. With the depth initialization strategy and tool mask-guided training, our method can remove surgical instruments and reconstruct high-fidelity surgical scenes. Through experiments on various surgical videos, our network outperforms existing method on many aspects, including rendering quality, rendering speed and GPU usage. The project page can be found at https://surgicalgaussian.github.io.
Towards Better Graph-based Cross-document Relation Extraction via Non-bridge Entity Enhancement and Prediction Debiasing
Jun 24, 2024



Cross-document Relation Extraction aims to predict the relation between target entities located in different documents. In this regard, the dominant models commonly retain useful information for relation prediction via bridge entities, which allows the model to elaborately capture the intrinsic interdependence between target entities. However, these studies ignore the non-bridge entities, each of which co-occurs with only one target entity and offers the semantic association between target entities for relation prediction. Besides, the commonly-used dataset--CodRED contains substantial NA instances, leading to the prediction bias during inference. To address these issues, in this paper, we propose a novel graph-based cross-document RE model with non-bridge entity enhancement and prediction debiasing. Specifically, we use a unified entity graph to integrate numerous non-bridge entities with target entities and bridge entities, modeling various associations between them, and then use a graph recurrent network to encode this graph. Finally, we introduce a novel debiasing strategy to calibrate the original prediction distribution. Experimental results on the closed and open settings show that our model significantly outperforms all baselines, including the GPT-3.5-turbo and InstructUIE, achieving state-of-the-art performance. Particularly, our model obtains 66.23% and 55.87% AUC points in the official leaderboard\footnote{\url{https://codalab.lisn.upsaclay.fr/competitions/3770#results}} under the two settings, respectively, ranking the first place in all submissions since December 2023. Our code is available at https://github.com/DeepLearnXMU/CoRE-NEPD.
On the Information Redundancy in Non-Autoregressive Translation
May 04, 2024Token repetition is a typical form of multi-modal problem in fully non-autoregressive translation (NAT). In this work, we revisit the multi-modal problem in recently proposed NAT models. Our study reveals that these advanced models have introduced other types of information redundancy errors, which cannot be measured by the conventional metric - the continuous repetition ratio. By manually annotating the NAT outputs, we identify two types of information redundancy errors that correspond well to lexical and reordering multi-modality problems. Since human annotation is time-consuming and labor-intensive, we propose automatic metrics to evaluate the two types of redundant errors. Our metrics allow future studies to evaluate new methods and gain a more comprehensive understanding of their effectiveness.
CMU-Flownet: Exploring Point Cloud Scene Flow Estimation in Occluded Scenario
Apr 16, 2024Occlusions hinder point cloud frame alignment in LiDAR data, a challenge inadequately addressed by scene flow models tested mainly on occlusion-free datasets. Attempts to integrate occlusion handling within networks often suffer accuracy issues due to two main limitations: a) the inadequate use of occlusion information, often merging it with flow estimation without an effective integration strategy, and b) reliance on distance-weighted upsampling that falls short in correcting occlusion-related errors. To address these challenges, we introduce the Correlation Matrix Upsampling Flownet (CMU-Flownet), incorporating an occlusion estimation module within its cost volume layer, alongside an Occlusion-aware Cost Volume (OCV) mechanism. Specifically, we propose an enhanced upsampling approach that expands the sensory field of the sampling process which integrates a Correlation Matrix designed to evaluate point-level similarity. Meanwhile, our model robustly integrates occlusion data within the context of scene flow, deploying this information strategically during the refinement phase of the flow estimation. The efficacy of this approach is demonstrated through subsequent experimental validation. Empirical assessments reveal that CMU-Flownet establishes state-of-the-art performance within the realms of occluded Flyingthings3D and KITTY datasets, surpassing previous methodologies across a majority of evaluated metrics.