 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAerial Path Online Planning for Urban Scene Updation
May 02, 2025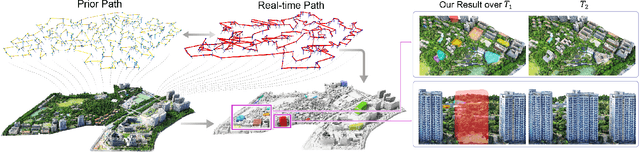



We present the first scene-update aerial path planning algorithm specifically designed for detecting and updating change areas in urban environments. While existing methods for large-scale 3D urban scene reconstruction focus on achieving high accuracy and completeness, they are inefficient for scenarios requiring periodic updates, as they often re-explore and reconstruct entire scenes, wasting significant time and resources on unchanged areas. To address this limitation, our method leverages prior reconstructions and change probability statistics to guide UAVs in detecting and focusing on areas likely to have changed. Our approach introduces a novel changeability heuristic to evaluate the likelihood of changes, driving the planning of two flight paths: a prior path informed by static priors and a dynamic real-time path that adapts to newly detected changes. The framework integrates surface sampling and candidate view generation strategies, ensuring efficient coverage of change areas with minimal redundancy. Extensive experiments on real-world urban datasets demonstrate that our method significantly reduces flight time and computational overhead, while maintaining high-quality updates comparable to full-scene re-exploration and reconstruction. These contributions pave the way for efficient, scalable, and adaptive UAV-based scene updates in complex urban environments.
CADDreamer: CAD object Generation from Single-view Images
Feb 28, 2025



Diffusion-based 3D generation has made remarkable progress in recent years. However, existing 3D generative models often produce overly dense and unstructured meshes, which stand in stark contrast to the compact, structured, and sharply-edged Computer-Aided Design (CAD) models crafted by human designers. To address this gap, we introduce CADDreamer, a novel approach for generating boundary representations (B-rep) of CAD objects from a single image. CADDreamer employs a primitive-aware multi-view diffusion model that captures both local geometric details and high-level structural semantics during the generation process. By encoding primitive semantics into the color domain, the method leverages the strong priors of pre-trained diffusion models to align with well-defined primitives. This enables the inference of multi-view normal maps and semantic maps from a single image, facilitating the reconstruction of a mesh with primitive labels. Furthermore, we introduce geometric optimization techniques and topology-preserving extraction methods to mitigate noise and distortion in the generated primitives. These enhancements result in a complete and seamless B-rep of the CAD model. Experimental results demonstrate that our method effectively recovers high-quality CAD objects from single-view images. Compared to existing 3D generation techniques, the B-rep models produced by CADDreamer are compact in representation, clear in structure, sharp in edges, and watertight in topology.
WonderHuman: Hallucinating Unseen Parts in Dynamic 3D Human Reconstruction
Feb 03, 2025In this paper, we present WonderHuman to reconstruct dynamic human avatars from a monocular video for high-fidelity novel view synthesis. Previous dynamic human avatar reconstruction methods typically require the input video to have full coverage of the observed human body. However, in daily practice, one typically has access to limited viewpoints, such as monocular front-view videos, making it a cumbersome task for previous methods to reconstruct the unseen parts of the human avatar. To tackle the issue, we present WonderHuman, which leverages 2D generative diffusion model priors to achieve high-quality, photorealistic reconstructions of dynamic human avatars from monocular videos, including accurate rendering of unseen body parts. Our approach introduces a Dual-Space Optimization technique, applying Score Distillation Sampling (SDS) in both canonical and observation spaces to ensure visual consistency and enhance realism in dynamic human reconstruction. Additionally, we present a View Selection strategy and Pose Feature Injection to enforce the consistency between SDS predictions and observed data, ensuring pose-dependent effects and higher fidelity in the reconstructed avatar. In the experiments, our method achieves SOTA performance in producing photorealistic renderings from the given monocular video, particularly for those challenging unseen parts. The project page and source code can be found at https://wyiguanw.github.io/WonderHuman/.
RMAvatar: Photorealistic Human Avatar Reconstruction from Monocular Video Based on Rectified Mesh-embedded Gaussians
Jan 13, 2025



We introduce RMAvatar, a novel human avatar representation with Gaussian splatting embedded on mesh to learn clothed avatar from a monocular video. We utilize the explicit mesh geometry to represent motion and shape of a virtual human and implicit appearance rendering with Gaussian Splatting. Our method consists of two main modules: Gaussian initialization module and Gaussian rectification module. We embed Gaussians into triangular faces and control their motion through the mesh, which ensures low-frequency motion and surface deformation of the avatar. Due to the limitations of LBS formula, the human skeleton is hard to control complex non-rigid transformations. We then design a pose-related Gaussian rectification module to learn fine-detailed non-rigid deformations, further improving the realism and expressiveness of the avatar. We conduct extensive experiments on public datasets, RMAvatar shows state-of-the-art performance on both rendering quality and quantitative evaluations. Please see our project page at https://rm-avatar.github.io.
TexHOI: Reconstructing Textures of 3D Unknown Objects in Monocular Hand-Object Interaction Scenes
Jan 07, 2025



Reconstructing 3D models of dynamic, real-world objects with high-fidelity textures from monocular frame sequences has been a challenging problem in recent years. This difficulty stems from factors such as shadows, indirect illumination, and inaccurate object-pose estimations due to occluding hand-object interactions. To address these challenges, we propose a novel approach that predicts the hand's impact on environmental visibility and indirect illumination on the object's surface albedo. Our method first learns the geometry and low-fidelity texture of the object, hand, and background through composite rendering of radiance fields. Simultaneously, we optimize the hand and object poses to achieve accurate object-pose estimations. We then refine physics-based rendering parameters - including roughness, specularity, albedo, hand visibility, skin color reflections, and environmental illumination - to produce precise albedo, and accurate hand illumination and shadow regions. Our approach surpasses state-of-the-art methods in texture reconstruction and, to the best of our knowledge, is the first to account for hand-object interactions in object texture reconstruction.
Joint Co-Speech Gesture and Expressive Talking Face Generation using Diffusion with Adapters
Dec 18, 2024



Recent advances in co-speech gesture and talking head generation have been impressive, yet most methods focus on only one of the two tasks. Those that attempt to generate both often rely on separate models or network modules, increasing training complexity and ignoring the inherent relationship between face and body movements. To address the challenges, in this paper, we propose a novel model architecture that jointly generates face and body motions within a single network. This approach leverages shared weights between modalities, facilitated by adapters that enable adaptation to a common latent space. Our experiments demonstrate that the proposed framework not only maintains state-of-the-art co-speech gesture and talking head generation performance but also significantly reduces the number of parameters required.
NASM: Neural Anisotropic Surface Meshing
Oct 30, 2024This paper introduces a new learning-based method, NASM, for anisotropic surface meshing. Our key idea is to propose a graph neural network to embed an input mesh into a high-dimensional (high-d) Euclidean embedding space to preserve curvature-based anisotropic metric by using a dot product loss between high-d edge vectors. This can dramatically reduce the computational time and increase the scalability. Then, we propose a novel feature-sensitive remeshing on the generated high-d embedding to automatically capture sharp geometric features. We define a high-d normal metric, and then derive an automatic differentiation on a high-d centroidal Voronoi tessellation (CVT) optimization with the normal metric to simultaneously preserve geometric features and curvature anisotropy that exhibit in the original 3D shapes. To our knowledge, this is the first time that a deep learning framework and a large dataset are proposed to construct a high-d Euclidean embedding space for 3D anisotropic surface meshing. Experimental results are evaluated and compared with the state-of-the-art in anisotropic surface meshing on a large number of surface models from Thingi10K dataset as well as tested on extensive unseen 3D shapes from Multi-Garment Network dataset and FAUST human dataset.
DiffTED: One-shot Audio-driven TED Talk Video Generation with Diffusion-based Co-speech Gestures
Sep 11, 2024



Audio-driven talking video generation has advanced significantly, but existing methods often depend on video-to-video translation techniques and traditional generative networks like GANs and they typically generate taking heads and co-speech gestures separately, leading to less coherent outputs. Furthermore, the gestures produced by these methods often appear overly smooth or subdued, lacking in diversity, and many gesture-centric approaches do not integrate talking head generation. To address these limitations, we introduce DiffTED, a new approach for one-shot audio-driven TED-style talking video generation from a single image. Specifically, we leverage a diffusion model to generate sequences of keypoints for a Thin-Plate Spline motion model, precisely controlling the avatar's animation while ensuring temporally coherent and diverse gestures. This innovative approach utilizes classifier-free guidance, empowering the gestures to flow naturally with the audio input without relying on pre-trained classifiers. Experiments demonstrate that DiffTED generates temporally coherent talking videos with diverse co-speech gestures.
SurgicalGaussian: Deformable 3D Gaussians for High-Fidelity Surgical Scene Reconstruction
Jul 06, 2024



Dynamic reconstruction of deformable tissues in endoscopic video is a key technology for robot-assisted surgery. Recent reconstruction methods based on neural radiance fields (NeRFs) have achieved remarkable results in the reconstruction of surgical scenes. However, based on implicit representation, NeRFs struggle to capture the intricate details of objects in the scene and cannot achieve real-time rendering. In addition, restricted single view perception and occluded instruments also propose special challenges in surgical scene reconstruction. To address these issues, we develop SurgicalGaussian, a deformable 3D Gaussian Splatting method to model dynamic surgical scenes. Our approach models the spatio-temporal features of soft tissues at each time stamp via a forward-mapping deformation MLP and regularization to constrain local 3D Gaussians to comply with consistent movement. With the depth initialization strategy and tool mask-guided training, our method can remove surgical instruments and reconstruct high-fidelity surgical scenes. Through experiments on various surgical videos, our network outperforms existing method on many aspects, including rendering quality, rendering speed and GPU usage. The project page can be found at https://surgicalgaussian.github.io.
HO-Cap: A Capture System and Dataset for 3D Reconstruction and Pose Tracking of Hand-Object Interaction
Jun 10, 2024



We introduce a data capture system and a new dataset named HO-Cap that can be used to study 3D reconstruction and pose tracking of hands and objects in videos. The capture system uses multiple RGB-D cameras and a HoloLens headset for data collection, avoiding the use of expensive 3D scanners or mocap systems. We propose a semi-automatic method to obtain annotations of shape and pose of hands and objects in the collected videos, which significantly reduces the required annotation time compared to manual labeling. With this system, we captured a video dataset of humans using objects to perform different tasks, as well as simple pick-and-place and handover of an object from one hand to the other, which can be used as human demonstrations for embodied AI and robot manipulation research. Our data capture setup and annotation framework can be used by the community to reconstruct 3D shapes of objects and human hands and track their poses in videos.