 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexHOI: Reconstructing Textures of 3D Unknown Objects in Monocular Hand-Object Interaction Scenes
Jan 07, 2025



Reconstructing 3D models of dynamic, real-world objects with high-fidelity textures from monocular frame sequences has been a challenging problem in recent years. This difficulty stems from factors such as shadows, indirect illumination, and inaccurate object-pose estimations due to occluding hand-object interactions. To address these challenges, we propose a novel approach that predicts the hand's impact on environmental visibility and indirect illumination on the object's surface albedo. Our method first learns the geometry and low-fidelity texture of the object, hand, and background through composite rendering of radiance fields. Simultaneously, we optimize the hand and object poses to achieve accurate object-pose estimations. We then refine physics-based rendering parameters - including roughness, specularity, albedo, hand visibility, skin color reflections, and environmental illumination - to produce precise albedo, and accurate hand illumination and shadow regions. Our approach surpasses state-of-the-art methods in texture reconstruction and, to the best of our knowledge, is the first to account for hand-object interactions in object texture reconstruction.
MACOptions: Multi-Agent Learning with Centralized Controller and Options Framework
Feb 07, 2023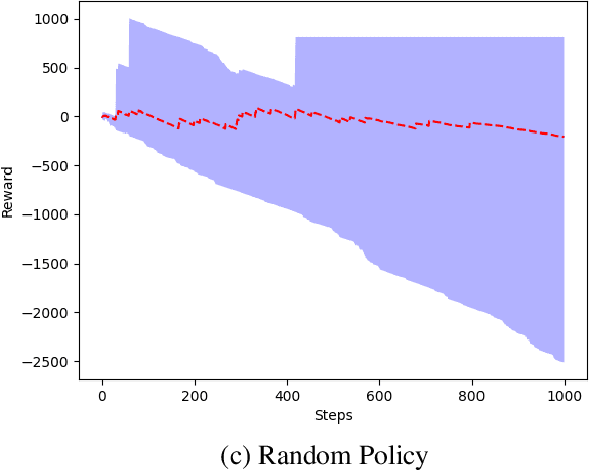
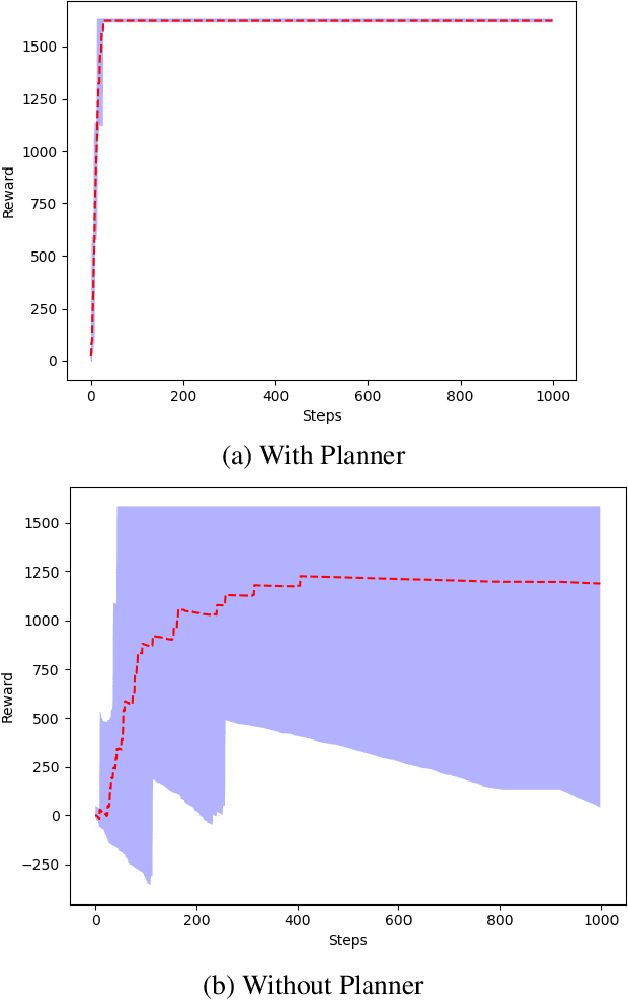
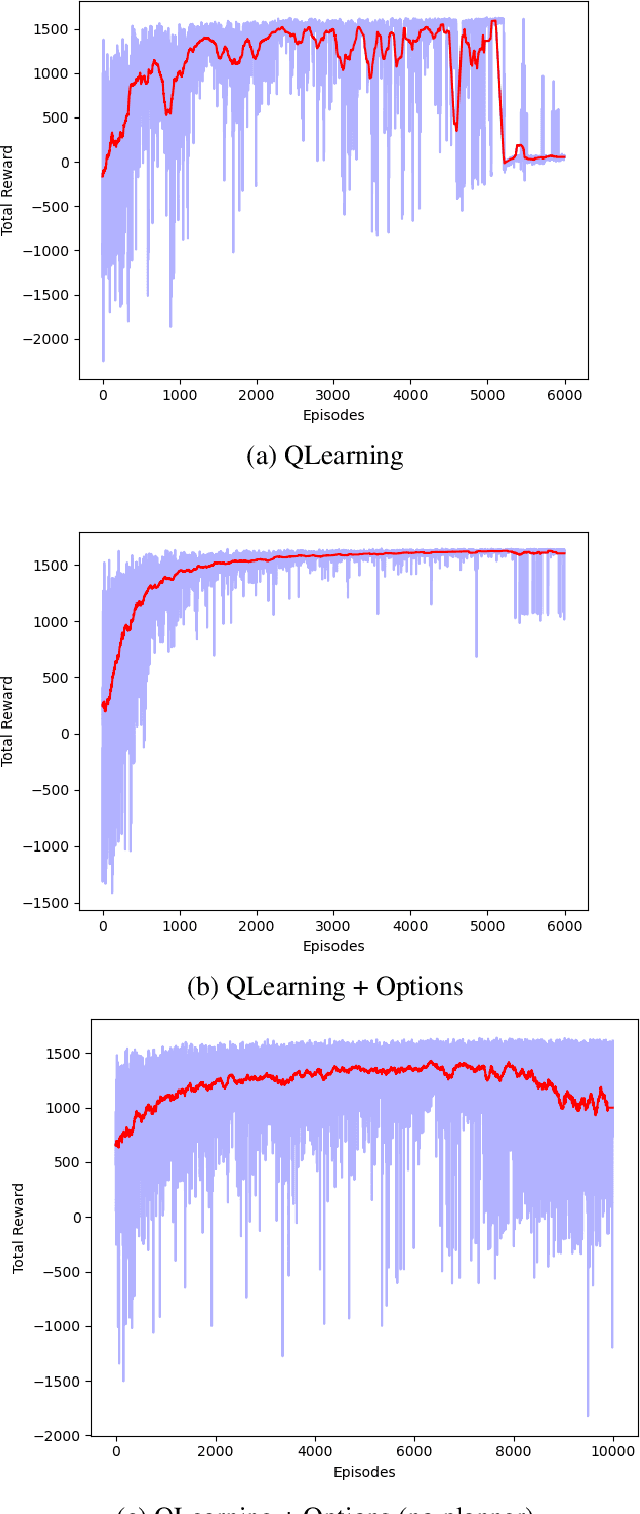
These days automation is being applied everywhere. In every environment, planning for the actions to be taken by the agents is an important aspect. In this paper, we plan to implement planning for multi-agents with a centralized controller. We compare three approaches: random policy, Q-learning, and Q-learning with Options Framework. We also show the effectiveness of planners by showing performance comparison between Q-Learning with Planner and without Planner.
Layered-Garment Net: Generating Multiple Implicit Garment Layers from a Single Image
Nov 22, 2022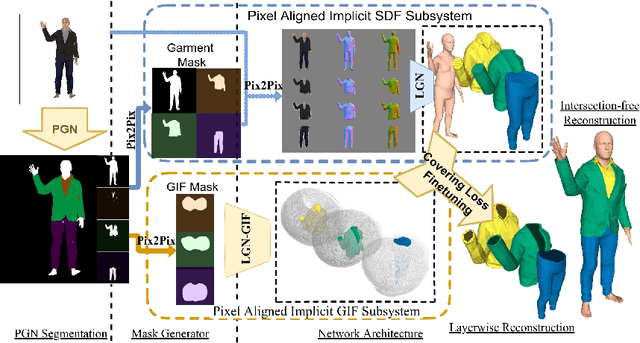

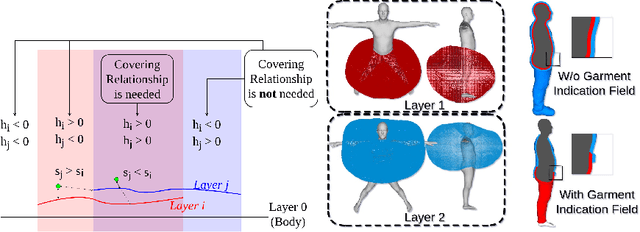
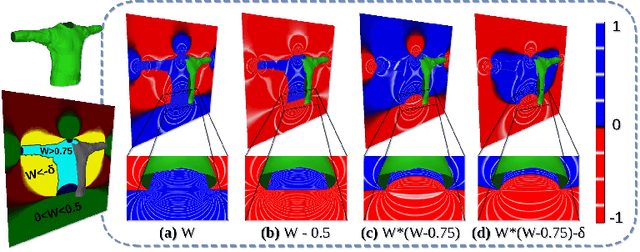
Recent research works have focused on generating human models and garments from their 2D images. However, state-of-the-art researches focus either on only a single layer of the garment on a human model or on generating multiple garment layers without any guarantee of the intersection-free geometric relationship between them. In reality, people wear multiple layers of garments in their daily life, where an inner layer of garment could be partially covered by an outer one. In this paper, we try to address this multi-layer modeling problem and propose the Layered-Garment Net (LGN) that is capable of generating intersection-free multiple layers of garments defined by implicit function fields over the body surface, given the person's near front-view image. With a special design of garment indication fields (GIF), we can enforce an implicit covering relationship between the signed distance fields (SDF) of different layers to avoid self-intersections among different garment surfaces and the human body. Experiments demonstrate the strength of our proposed LGN framework in generating multi-layer garments as compared to state-of-the-art methods. To the best of our knowledge, LGN is the first research work to generate intersection-free multiple layers of garments on the human body from a single image.
Broad Neural Network for Change Detection in Aerial Images
Feb 28, 2019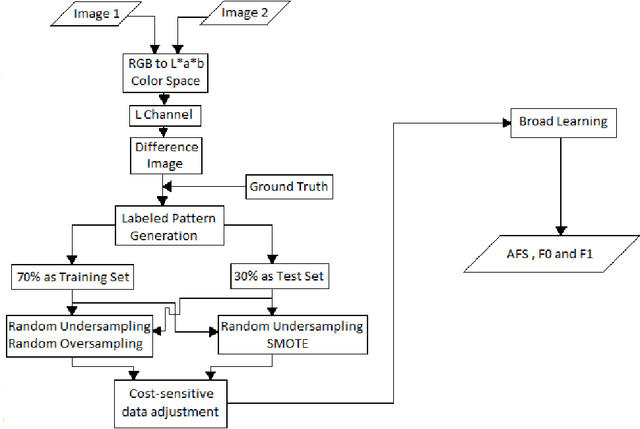
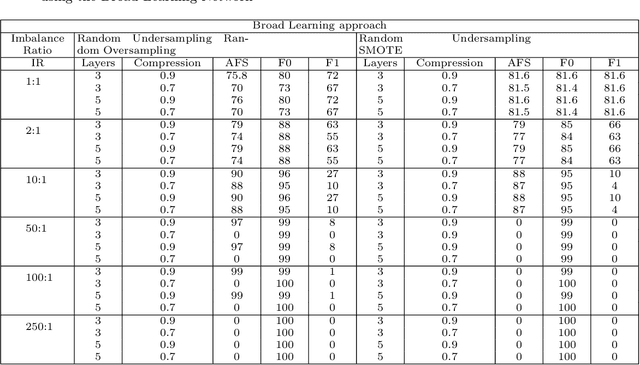
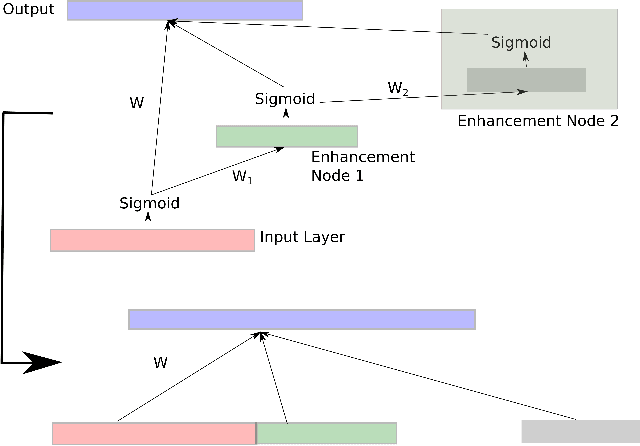
A change detection system takes as input two images of a region captured at two different times, and predicts which pixels in the region have undergone change over the time period. Since pixel-based analysis can be erroneous due to noise, illumination difference and other factors, contextual information is usually used to determine the class of a pixel (changed or not). This contextual information is taken into account by considering a pixel of the difference image along with its neighborhood. With the help of ground truth information, the labeled patterns are generated. Finally, Broad Learning classifier is used to get prediction about the class of each pixel. Results show that Broad Learning can classify the data set with a significantly higher F-Score than that of Multilayer Perceptron. Performance comparison has also been made with other popular classifiers, namely Multilayer Perceptron and Random Forest.