 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Local Matches to Global Masks: Novel Instance Detection in Open-World Scenes
Mar 03, 2026Detecting and segmenting novel object instances in open-world environments is a fundamental problem in robotic perception. Given only a small set of template images, a robot must locate and segment a specific object instance in a cluttered, previously unseen scene. Existing proposal-based approaches are highly sensitive to proposal quality and often fail under occlusion and background clutter. We propose L2G-Det, a local-to-global instance detection framework that bypasses explicit object proposals by leveraging dense patch-level matching between templates and the query image. Locally matched patches generate candidate points, which are refined through a candidate selection module to suppress false positives. The filtered points are then used to prompt an augmented Segment Anything Model (SAM) with instance-specific object tokens, enabling reliable reconstruction of complete instance masks. Experiments demonstrate improved performance over proposal-based methods in challenging open-world settings.
Accelerate Speculative Decoding with Sparse Computation in Verification
Dec 26, 2025Speculative decoding accelerates autoregressive language model inference by verifying multiple draft tokens in parallel. However, the verification stage often becomes the dominant computational bottleneck, especially for long-context inputs and mixture-of-experts (MoE) models. Existing sparsification methods are designed primarily for standard token-by-token autoregressive decoding to remove substantial computational redundancy in LLMs. This work systematically adopts different sparse methods on the verification stage of the speculative decoding and identifies structured redundancy across multiple dimensions. Based on these observations, we propose a sparse verification framework that jointly sparsifies attention, FFN, and MoE components during the verification stage to reduce the dominant computation cost. The framework further incorporates an inter-draft token and inter-layer retrieval reuse strategy to further reduce redundant computation without introducing additional training. Extensive experiments across summarization, question answering, and mathematical reasoning datasets demonstrate that the proposed methods achieve favorable efficiency-accuracy trade-offs, while maintaining stable acceptance length.
Alignment-Augmented Speculative Decoding with Alignment Sampling and Conditional Verification
May 19, 2025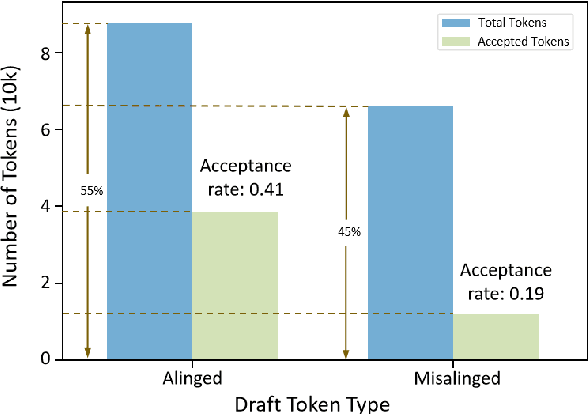
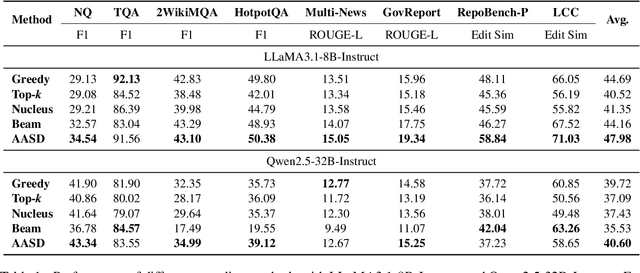
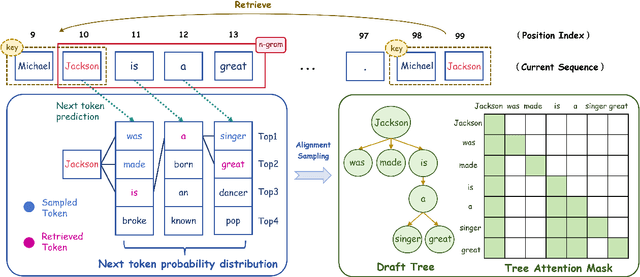
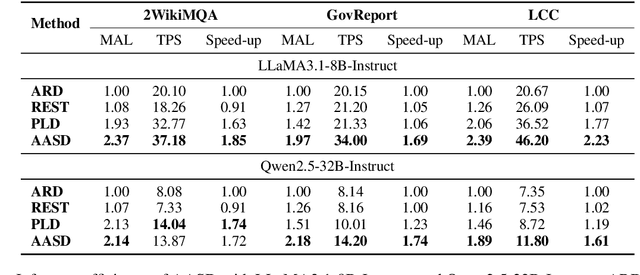
Recent works have revealed the great potential of speculative decoding in accelerating the autoregressive generation process of large language models. The success of these methods relies on the alignment between draft candidates and the sampled outputs of the target model. Existing methods mainly achieve draft-target alignment with training-based methods, e.g., EAGLE, Medusa, involving considerable training costs. In this paper, we present a training-free alignment-augmented speculative decoding algorithm. We propose alignment sampling, which leverages output distribution obtained in the prefilling phase to provide more aligned draft candidates. To further benefit from high-quality but non-aligned draft candidates, we also introduce a simple yet effective flexible verification strategy. Through an adaptive probability threshold, our approach can improve generation accuracy while further improving inference efficiency. Experiments on 8 datasets (including question answering, summarization and code completion tasks) show that our approach increases the average generation score by 3.3 points for the LLaMA3 model. Our method achieves a mean acceptance length up to 2.39 and speed up generation by 2.23.
Efficient Reasoning for LLMs through Speculative Chain-of-Thought
Apr 27, 2025Large reasoning language models such as OpenAI-o1 and Deepseek-R1 have recently attracted widespread attention due to their impressive task-solving abilities. However, the enormous model size and the generation of lengthy thought chains introduce significant reasoning costs and response latency. Existing methods for efficient reasoning mainly focus on reducing the number of model parameters or shortening the chain-of-thought length. In this paper, we introduce Speculative Chain-of-Thought (SCoT), which reduces reasoning latency from another perspective by accelerated average reasoning speed through large and small model collaboration. SCoT conducts thought-level drafting using a lightweight draft model. Then it selects the best CoT draft and corrects the error cases with the target model. The proposed thinking behavior alignment improves the efficiency of drafting and the draft selection strategy maintains the prediction accuracy for complex problems. Experimental results on GSM8K, MATH, GaoKao, CollegeMath and Olympiad datasets show that SCoT reduces reasoning latency by 48\%$\sim$66\% for Deepseek-R1-Distill-Qwen-32B while achieving near-target-model-level performance. Our code is available at https://github.com/Jikai0Wang/Speculative_CoT.
Visual Style Prompt Learning Using Diffusion Models for Blind Face Restoration
Dec 30, 2024



Blind face restoration aims to recover high-quality facial images from various unidentified sources of degradation, posing significant challenges due to the minimal information retrievable from the degraded images. Prior knowledge-based methods, leveraging geometric priors and facial features, have led to advancements in face restoration but often fall short of capturing fine details. To address this, we introduce a visual style prompt learning framework that utilizes diffusion probabilistic models to explicitly generate visual prompts within the latent space of pre-trained generative models. These prompts are designed to guide the restoration process. To fully utilize the visual prompts and enhance the extraction of informative and rich patterns, we introduce a style-modulated aggregation transformation layer. Extensive experiments and applications demonstrate the superiority of our method in achieving high-quality blind face restoration. The source code is available at \href{https://github.com/LonglongaaaGo/VSPBFR}{https://github.com/LonglongaaaGo/VSPBFR}.
* Published at Pattern Recognition; 13 pages, 11 figures
FACEMUG: A Multimodal Generative and Fusion Framework for Local Facial Editing
Dec 26, 2024Existing facial editing methods have achieved remarkable results, yet they often fall short in supporting multimodal conditional local facial editing. One of the significant evidences is that their output image quality degrades dramatically after several iterations of incremental editing, as they do not support local editing. In this paper, we present a novel multimodal generative and fusion framework for globally-consistent local facial editing (FACEMUG) that can handle a wide range of input modalities and enable fine-grained and semantic manipulation while remaining unedited parts unchanged. Different modalities, including sketches, semantic maps, color maps, exemplar images, text, and attribute labels, are adept at conveying diverse conditioning details, and their combined synergy can provide more explicit guidance for the editing process. We thus integrate all modalities into a unified generative latent space to enable multimodal local facial edits. Specifically, a novel multimodal feature fusion mechanism is proposed by utilizing multimodal aggregation and style fusion blocks to fuse facial priors and multimodalities in both latent and feature spaces. We further introduce a novel self-supervised latent warping algorithm to rectify misaligned facial features, efficiently transferring the pose of the edited image to the given latent codes. We evaluate our FACEMUG through extensive experiments and comparisons to state-of-the-art (SOTA) methods. The results demonstrate the superiority of FACEMUG in terms of editing quality, flexibility, and semantic control, making it a promising solution for a wide range of local facial editing tasks.
CubeFormer: A Simple yet Effective Baseline for Lightweight Image Super-Resolution
Dec 03, 2024Lightweight image super-resolution (SR) methods aim at increasing the resolution and restoring the details of an image using a lightweight neural network. However, current lightweight SR methods still suffer from inferior performance and unpleasant details. Our analysis reveals that these methods are hindered by constrained feature diversity, which adversely impacts feature representation and detail recovery. To respond this issue, we propose a simple yet effective baseline called CubeFormer, designed to enhance feature richness by completing holistic information aggregation. To be specific, we introduce cube attention, which expands 2D attention to 3D space, facilitating exhaustive information interactions, further encouraging comprehensive information extraction and promoting feature variety. In addition, we inject block and grid sampling strategies to construct intra-cube transformer blocks (Intra-CTB) and inter-cube transformer blocks (Inter-CTB), which perform local and global modeling, respectively. Extensive experiments show that our CubeFormer achieves state-of-the-art performance on commonly used SR benchmarks. Our source code and models will be publicly available.
OPT-Tree: Speculative Decoding with Adaptive Draft Tree Structure
Jun 25, 2024



Autoregressive language models demonstrate excellent performance in various scenarios. However, the inference efficiency is limited by its one-step-one-word generation mode, which has become a pressing problem recently as the models become increasingly larger. Speculative decoding employs a "draft and then verify" mechanism to allow multiple tokens to be generated in one step, realizing lossless acceleration. Existing methods mainly adopt fixed heuristic draft structures, which fail to adapt to different situations to maximize the acceptance length during verification. To alleviate this dilemma, we proposed OPT-Tree, an algorithm to construct adaptive and scalable draft trees. It searches the optimal tree structure that maximizes the mathematical expectation of the acceptance length in each decoding step. Experimental results reveal that OPT-Tree outperforms the existing draft structures and achieves a speed-up ratio of up to 3.2 compared with autoregressive decoding. If the draft model is powerful enough and the node budget is sufficient, it can generate more than ten tokens in a single step. Our code is available at https://github.com/Jikai0Wang/OPT-Tree.
HO-Cap: A Capture System and Dataset for 3D Reconstruction and Pose Tracking of Hand-Object Interaction
Jun 10, 2024



We introduce a data capture system and a new dataset named HO-Cap that can be used to study 3D reconstruction and pose tracking of hands and objects in videos. The capture system uses multiple RGB-D cameras and a HoloLens headset for data collection, avoiding the use of expensive 3D scanners or mocap systems. We propose a semi-automatic method to obtain annotations of shape and pose of hands and objects in the collected videos, which significantly reduces the required annotation time compared to manual labeling. With this system, we captured a video dataset of humans using objects to perform different tasks, as well as simple pick-and-place and handover of an object from one hand to the other, which can be used as human demonstrations for embodied AI and robot manipulation research. Our data capture setup and annotation framework can be used by the community to reconstruct 3D shapes of objects and human hands and track their poses in videos.
OpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
May 09, 2024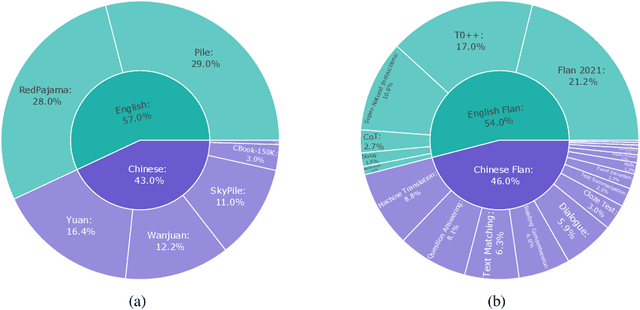

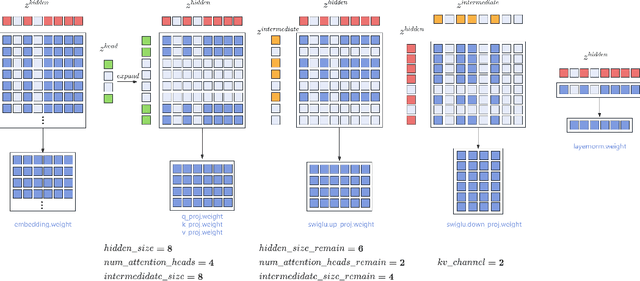
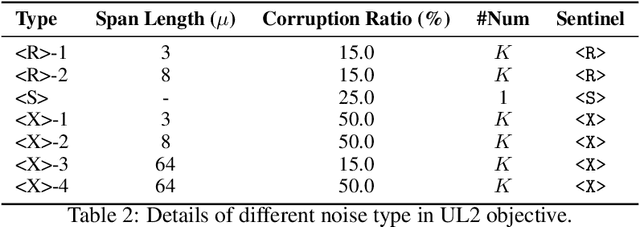
Large Language Models (LLMs) have played an important role in many fields due to their powerful capabilities.However, their massive number of parameters leads to high deployment requirements and incurs significant inference costs, which impedes their practical applications. Training smaller models is an effective way to address this problem. Therefore, we introduce OpenBA-V2, a 3.4B model derived from multi-stage compression and continual pre-training from the original 15B OpenBA model. OpenBA-V2 utilizes more data, more flexible training objectives, and techniques such as layer pruning, neural pruning, and vocabulary pruning to achieve a compression rate of 77.3\% with minimal performance loss. OpenBA-V2 demonstrates competitive performance compared to other open-source models of similar size, achieving results close to or on par with the 15B OpenBA model in downstream tasks such as common sense reasoning and Named Entity Recognition (NER). OpenBA-V2 illustrates that LLMs can be compressed into smaller ones with minimal performance loss by employing advanced training objectives and data strategies, which may help deploy LLMs in resource-limited scenarios.