 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing and Mitigating Over-Attention in Knowledge Editing
Feb 20, 2025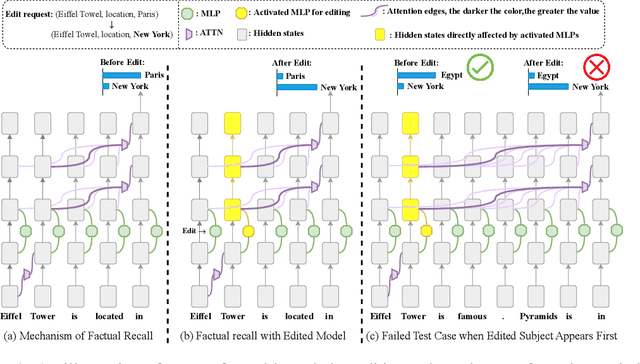



Large Language Models have demonstrated superior performance across a wide range of tasks, but they still exhibit undesirable errors due to incorrect knowledge learned from the training data. To avoid this, knowledge editing methods emerged to precisely edit the specific model knowledge via efficiently modifying a very small percentage of parameters. % However, those methods can lead to the problem of Specificity Failure: when the content related to the edited knowledge occurs in the context, it can inadvertently corrupt other pre-existing knowledge. However, those methods can lead to the problem of Specificity Failure, where the existing knowledge and capabilities are severely degraded due to editing. Our preliminary indicates that Specificity Failure primarily stems from the model's attention heads assigning excessive attention scores to entities related to the edited knowledge, thereby unduly focusing on specific snippets within the context, which we denote as the Attention Drift phenomenon. To mitigate such Attention Drift issue, we introduce a simple yet effective method Selective Attention Drift Restriction}(SADR), which introduces an additional regularization term during the knowledge editing process to restrict changes in the attention weight distribution, thereby preventing undue focus on the edited entity. Experiments on five frequently used strong LLMs demonstrate the effectiveness of our method, where SADR can significantly mitigate Specificity Failure in the predominant knowledge editing tasks.
OpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
May 09, 2024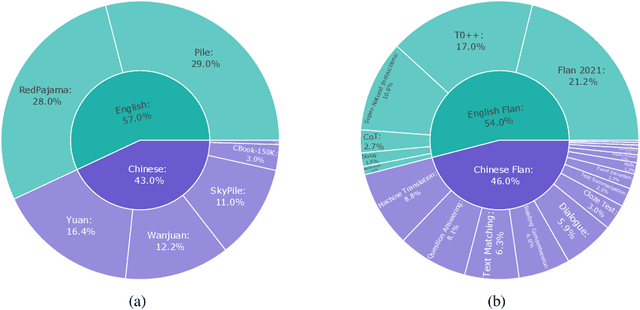

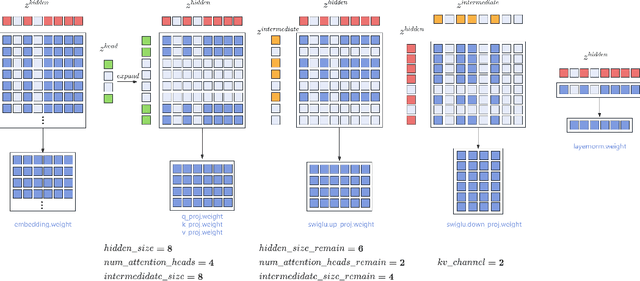
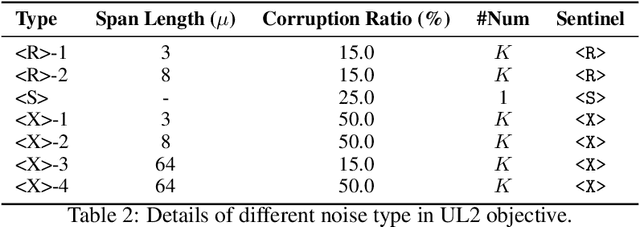
Large Language Models (LLMs) have played an important role in many fields due to their powerful capabilities.However, their massive number of parameters leads to high deployment requirements and incurs significant inference costs, which impedes their practical applications. Training smaller models is an effective way to address this problem. Therefore, we introduce OpenBA-V2, a 3.4B model derived from multi-stage compression and continual pre-training from the original 15B OpenBA model. OpenBA-V2 utilizes more data, more flexible training objectives, and techniques such as layer pruning, neural pruning, and vocabulary pruning to achieve a compression rate of 77.3\% with minimal performance loss. OpenBA-V2 demonstrates competitive performance compared to other open-source models of similar size, achieving results close to or on par with the 15B OpenBA model in downstream tasks such as common sense reasoning and Named Entity Recognition (NER). OpenBA-V2 illustrates that LLMs can be compressed into smaller ones with minimal performance loss by employing advanced training objectives and data strategies, which may help deploy LLMs in resource-limited scenarios.
Rethinking Negative Instances for Generative Named Entity Recognition
Feb 26, 2024



Large Language Models (LLMs) have demonstrated impressive capabilities for generalizing in unseen tasks. In the Named Entity Recognition (NER) task, recent advancements have seen the remarkable improvement of LLMs in a broad range of entity domains via instruction tuning, by adopting entity-centric schema. In this work, we explore the potential enhancement of the existing methods by incorporating negative instances into training. Our experiments reveal that negative instances contribute to remarkable improvements by (1) introducing contextual information, and (2) clearly delineating label boundaries. Furthermore, we introduce a novel and efficient algorithm named Hierarchical Matching, which is tailored to transform unstructured predictions into structured entities. By integrating these components, we present GNER, a Generative NER system that shows improved zero-shot performance across unseen entity domains. Our comprehensive evaluation illustrates our system's superiority, surpassing state-of-the-art (SoTA) methods by 11 $F_1$ score in zero-shot evaluation.
OpenBA: An Open-sourced 15B Bilingual Asymmetric seq2seq Model Pre-trained from Scratch
Oct 01, 2023



Large language models (LLMs) with billions of parameters have demonstrated outstanding performance on various natural language processing tasks. This report presents OpenBA, an open-sourced 15B bilingual asymmetric seq2seq model, to contribute an LLM variant to the Chinese-oriented open-source model community. We enhance OpenBA with effective and efficient techniques as well as adopt a three-stage training strategy to train the model from scratch. Our solution can also achieve very competitive performance with only 380B tokens, which is better than LLaMA-70B on the BELEBELE benchmark, BLOOM-176B on the MMLU benchmark, GLM-130B on the C-Eval (hard) benchmark. This report provides the main details to pre-train an analogous model, including pre-training data processing, Bilingual Flan data collection, the empirical observations that inspire our model architecture design, training objectives of different stages, and other enhancement techniques. Additionally, we also provide the fine-tuning details of OpenBA on four downstream tasks. We have refactored our code to follow the design principles of the Huggingface Transformers Library, making it more convenient for developers to use, and released checkpoints of different training stages at https://huggingface.co/openBA. More details of our project are available at https://github.com/OpenNLG/openBA.git.
Detoxify Language Model Step-by-Step
Aug 16, 2023



Detoxification for LLMs is challenging since it requires models to avoid generating harmful content while maintaining the generation capability. To ensure the safety of generations, previous detoxification methods detoxify the models by changing the data distributions or constraining the generations from different aspects in a single-step manner. However, these approaches will dramatically affect the generation quality of LLMs, e.g., discourse coherence and semantic consistency, since language models tend to generate along the toxic prompt while detoxification methods work in the opposite direction. To handle such a conflict, we decompose the detoxification process into different sub-steps, where the detoxification is concentrated in the input stage and the subsequent continual generation is based on the non-toxic prompt. Besides, we also calibrate the strong reasoning ability of LLMs by designing a Detox-Chain to connect the above sub-steps in an orderly manner, which allows LLMs to detoxify the text step-by-step. Automatic and human evaluation on two benchmarks reveals that by training with Detox-Chain, six LLMs scaling from 1B to 33B can obtain significant detoxification and generation improvement. Our code and data are available at https://github.com/CODINNLG/Detox-CoT. Warning: examples in the paper may contain uncensored offensive content.
Can Diffusion Model Achieve Better Performance in Text Generation? Bridging the Gap between Training and Inference!
May 08, 2023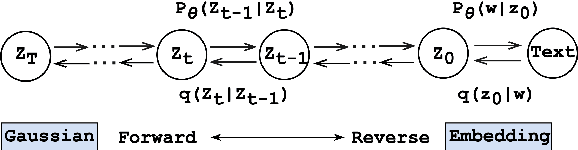

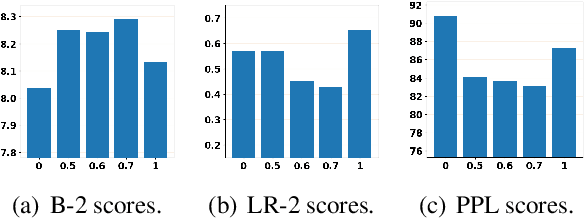

Diffusion models have been successfully adapted to text generation tasks by mapping the discrete text into the continuous space. However, there exist nonnegligible gaps between training and inference, owing to the absence of the forward process during inference. Thus, the model only predicts based on the previously generated reverse noise rather than the noise computed by the forward process. Besides, the widely-used downsampling strategy in speeding up the inference will cause the mismatch of diffusion trajectories between training and inference. To understand and mitigate the above two types of training-inference discrepancies, we launch a thorough preliminary study. Based on our observations, we propose two simple yet effective methods to bridge the gaps mentioned above, named Distance Penalty and Adaptive Decay Sampling. Extensive experiments on \textbf{6} generation tasks confirm the superiority of our methods, which can achieve $100\times \rightarrow 200\times$ speedup with better performance.
UFNRec: Utilizing False Negative Samples for Sequential Recommendation
Aug 08, 2022



Sequential recommendation models are primarily optimized to distinguish positive samples from negative ones during training in which negative sampling serves as an essential component in learning the evolving user preferences through historical records. Except for randomly sampling negative samples from a uniformly distributed subset, many delicate methods have been proposed to mine negative samples with high quality. However, due to the inherent randomness of negative sampling, false negative samples are inevitably collected in model training. Current strategies mainly focus on removing such false negative samples, which leads to overlooking potential user interests, lack of recommendation diversity, less model robustness, and suffering from exposure bias. To this end, we propose a novel method that can Utilize False Negative samples for sequential Recommendation (UFNRec) to improve model performance. We first devise a simple strategy to extract false negative samples and then transfer these samples to positive samples in the following training process. Furthermore, we construct a teacher model to provide soft labels for false negative samples and design a consistency loss to regularize the predictions of these samples from the student model and the teacher model. To the best of our knowledge, this is the first work to utilize false negative samples instead of simply removing them for the sequential recommendation. Experiments on three benchmark public datasets are conducted using three widely applied SOTA models. The experiment results demonstrate that our proposed UFNRec can effectively draw information from false negative samples and further improve the performance of SOTA models. The code is available at https://github.com/UFNRec-code/UFNRec.