 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing and Mitigating Over-Attention in Knowledge Editing
Feb 20, 2025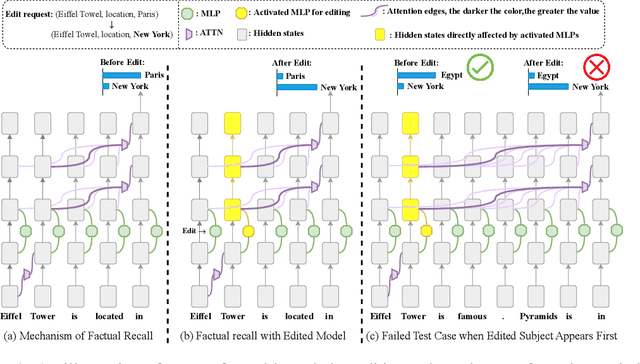



Large Language Models have demonstrated superior performance across a wide range of tasks, but they still exhibit undesirable errors due to incorrect knowledge learned from the training data. To avoid this, knowledge editing methods emerged to precisely edit the specific model knowledge via efficiently modifying a very small percentage of parameters. % However, those methods can lead to the problem of Specificity Failure: when the content related to the edited knowledge occurs in the context, it can inadvertently corrupt other pre-existing knowledge. However, those methods can lead to the problem of Specificity Failure, where the existing knowledge and capabilities are severely degraded due to editing. Our preliminary indicates that Specificity Failure primarily stems from the model's attention heads assigning excessive attention scores to entities related to the edited knowledge, thereby unduly focusing on specific snippets within the context, which we denote as the Attention Drift phenomenon. To mitigate such Attention Drift issue, we introduce a simple yet effective method Selective Attention Drift Restriction}(SADR), which introduces an additional regularization term during the knowledge editing process to restrict changes in the attention weight distribution, thereby preventing undue focus on the edited entity. Experiments on five frequently used strong LLMs demonstrate the effectiveness of our method, where SADR can significantly mitigate Specificity Failure in the predominant knowledge editing tasks.
L-CiteEval: Do Long-Context Models Truly Leverage Context for Responding?
Oct 03, 2024



Long-context models (LCMs) have made remarkable strides in recent years, offering users great convenience for handling tasks that involve long context, such as document summarization. As the community increasingly prioritizes the faithfulness of generated results, merely ensuring the accuracy of LCM outputs is insufficient, as it is quite challenging for humans to verify the results from the extremely lengthy context. Yet, although some efforts have been made to assess whether LCMs respond truly based on the context, these works either are limited to specific tasks or heavily rely on external evaluation resources like GPT-4.In this work, we introduce L-CiteEval, a comprehensive multi-task benchmark for long-context understanding with citations, aiming to evaluate both the understanding capability and faithfulness of LCMs. L-CiteEval covers 11 tasks from diverse domains, spanning context lengths from 8K to 48K, and provides a fully automated evaluation suite. Through testing with 11 cutting-edge closed-source and open-source LCMs, we find that although these models show minor differences in their generated results, open-source models substantially trail behind their closed-source counterparts in terms of citation accuracy and recall. This suggests that current open-source LCMs are prone to responding based on their inherent knowledge rather than the given context, posing a significant risk to the user experience in practical applications. We also evaluate the RAG approach and observe that RAG can significantly improve the faithfulness of LCMs, albeit with a slight decrease in the generation quality. Furthermore, we discover a correlation between the attention mechanisms of LCMs and the citation generation process.
Detoxify Language Model Step-by-Step
Aug 16, 2023



Detoxification for LLMs is challenging since it requires models to avoid generating harmful content while maintaining the generation capability. To ensure the safety of generations, previous detoxification methods detoxify the models by changing the data distributions or constraining the generations from different aspects in a single-step manner. However, these approaches will dramatically affect the generation quality of LLMs, e.g., discourse coherence and semantic consistency, since language models tend to generate along the toxic prompt while detoxification methods work in the opposite direction. To handle such a conflict, we decompose the detoxification process into different sub-steps, where the detoxification is concentrated in the input stage and the subsequent continual generation is based on the non-toxic prompt. Besides, we also calibrate the strong reasoning ability of LLMs by designing a Detox-Chain to connect the above sub-steps in an orderly manner, which allows LLMs to detoxify the text step-by-step. Automatic and human evaluation on two benchmarks reveals that by training with Detox-Chain, six LLMs scaling from 1B to 33B can obtain significant detoxification and generation improvement. Our code and data are available at https://github.com/CODINNLG/Detox-CoT. Warning: examples in the paper may contain uncensored offensive content.
Can Diffusion Model Achieve Better Performance in Text Generation? Bridging the Gap between Training and Inference!
May 08, 2023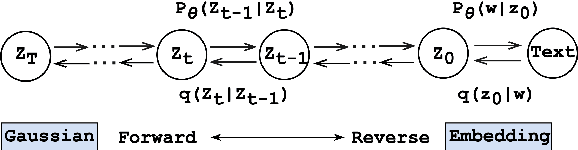

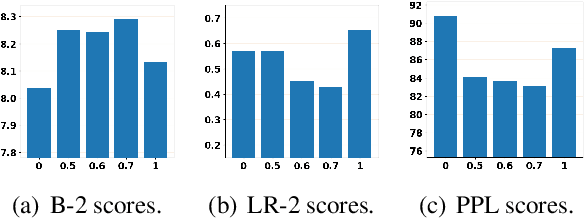

Diffusion models have been successfully adapted to text generation tasks by mapping the discrete text into the continuous space. However, there exist nonnegligible gaps between training and inference, owing to the absence of the forward process during inference. Thus, the model only predicts based on the previously generated reverse noise rather than the noise computed by the forward process. Besides, the widely-used downsampling strategy in speeding up the inference will cause the mismatch of diffusion trajectories between training and inference. To understand and mitigate the above two types of training-inference discrepancies, we launch a thorough preliminary study. Based on our observations, we propose two simple yet effective methods to bridge the gaps mentioned above, named Distance Penalty and Adaptive Decay Sampling. Extensive experiments on \textbf{6} generation tasks confirm the superiority of our methods, which can achieve $100\times \rightarrow 200\times$ speedup with better performance.