 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterleaved Tool-Call Reasoning for Protein Function Understanding
Jan 07, 2026Recent advances in large language models (LLMs) have highlighted the effectiveness of chain-of-thought reasoning in symbolic domains such as mathematics and programming. However, our study shows that directly transferring such text-based reasoning paradigms to protein function understanding is ineffective: reinforcement learning mainly amplifies superficial keyword patterns while failing to introduce new biological knowledge, resulting in limited generalization. We argue that protein function prediction is a knowledge-intensive scientific task that fundamentally relies on external biological priors and computational tools rather than purely internal reasoning. To address this gap, we propose PFUA, a tool-augmented protein reasoning agent that unifies problem decomposition, tool invocation, and grounded answer generation. Instead of relying on long unconstrained reasoning traces, PFUA integrates domain-specific tools to produce verifiable intermediate evidence. Experiments on four benchmarks demonstrate that PFUA consistently outperforms text-only reasoning models with an average performance improvement of 103%.
ProtTeX: Structure-In-Context Reasoning and Editing of Proteins with Large Language Models
Mar 13, 2025Large language models have made remarkable progress in the field of molecular science, particularly in understanding and generating functional small molecules. This success is largely attributed to the effectiveness of molecular tokenization strategies. In protein science, the amino acid sequence serves as the sole tokenizer for LLMs. However, many fundamental challenges in protein science are inherently structure-dependent. The absence of structure-aware tokens significantly limits the capabilities of LLMs for comprehensive biomolecular comprehension and multimodal generation. To address these challenges, we introduce a novel framework, ProtTeX, which tokenizes the protein sequences, structures, and textual information into a unified discrete space. This innovative approach enables joint training of the LLM exclusively through the Next-Token Prediction paradigm, facilitating multimodal protein reasoning and generation. ProtTeX enables general LLMs to perceive and process protein structures through sequential text input, leverage structural information as intermediate reasoning components, and generate or manipulate structures via sequential text output. Experiments demonstrate that our model achieves significant improvements in protein function prediction, outperforming the state-of-the-art domain expert model with a twofold increase in accuracy. Our framework enables high-quality conformational generation and customizable protein design. For the first time, we demonstrate that by adopting the standard training and inference pipelines from the LLM domain, ProtTeX empowers decoder-only LLMs to effectively address diverse spectrum of protein-related tasks.
ProTeX: Structure-In-Context Reasoning and Editing of Proteins with Large Language Models
Mar 11, 2025Large language models have made remarkable progress in the field of molecular science, particularly in understanding and generating functional small molecules. This success is largely attributed to the effectiveness of molecular tokenization strategies. In protein science, the amino acid sequence serves as the sole tokenizer for LLMs. However, many fundamental challenges in protein science are inherently structure-dependent. The absence of structure-aware tokens significantly limits the capabilities of LLMs for comprehensive biomolecular comprehension and multimodal generation. To address these challenges, we introduce a novel framework, ProTeX, which tokenizes the protein sequences, structures, and textual information into a unified discrete space. This innovative approach enables joint training of the LLM exclusively through the Next-Token Prediction paradigm, facilitating multimodal protein reasoning and generation. ProTeX enables general LLMs to perceive and process protein structures through sequential text input, leverage structural information as intermediate reasoning components, and generate or manipulate structures via sequential text output. Experiments demonstrate that our model achieves significant improvements in protein function prediction, outperforming the state-of-the-art domain expert model with a twofold increase in accuracy. Our framework enables high-quality conformational generation and customizable protein design. For the first time, we demonstrate that by adopting the standard training and inference pipelines from the LLM domain, ProTeX empowers decoder-only LLMs to effectively address diverse spectrum of protein-related tasks.
ChatMol: A Versatile Molecule Designer Based on the Numerically Enhanced Large Language Model
Feb 27, 2025



Goal-oriented de novo molecule design, namely generating molecules with specific property or substructure constraints, is a crucial yet challenging task in drug discovery. Existing methods, such as Bayesian optimization and reinforcement learning, often require training multiple property predictors and struggle to incorporate substructure constraints. Inspired by the success of Large Language Models (LLMs) in text generation, we propose ChatMol, a novel approach that leverages LLMs for molecule design across diverse constraint settings. Initially, we crafted a molecule representation compatible with LLMs and validated its efficacy across multiple online LLMs. Afterwards, we developed specific prompts geared towards diverse constrained molecule generation tasks to further fine-tune current LLMs while integrating feedback learning derived from property prediction. Finally, to address the limitations of LLMs in numerical recognition, we referred to the position encoding method and incorporated additional encoding for numerical values within the prompt. Experimental results across single-property, substructure-property, and multi-property constrained tasks demonstrate that ChatMol consistently outperforms state-of-the-art baselines, including VAE and RL-based methods. Notably, in multi-objective binding affinity maximization task, ChatMol achieves a significantly lower KD value of 0.25 for the protein target ESR1, while maintaining the highest overall performance, surpassing previous methods by 4.76%. Meanwhile, with numerical enhancement, the Pearson correlation coefficient between the instructed property values and those of the generated molecules increased by up to 0.49. These findings highlight the potential of LLMs as a versatile framework for molecule generation, offering a promising alternative to traditional latent space and RL-based approaches.
Interleaved-Modal Chain-of-Thought
Nov 29, 2024
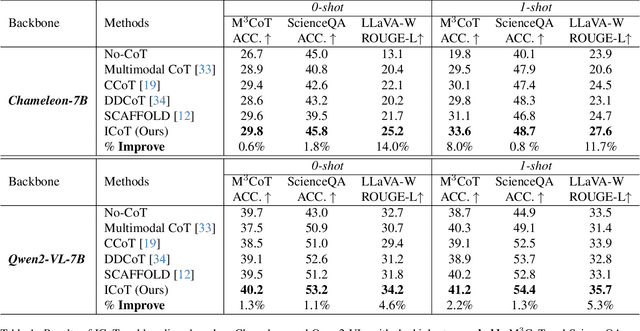


Chain-of-Thought (CoT) prompting elicits large language models (LLMs) to produce a series of intermediate reasoning steps before arriving at the final answer. However, when transitioning to vision-language models (VLMs), their text-only rationales struggle to express the fine-grained associations with the original image. In this paper, we propose an image-incorporated multimodal Chain-of-Thought, named \textbf{Interleaved-modal Chain-of-Thought (ICoT)}, which generates sequential reasoning steps consisting of paired visual and textual rationales to infer the final answer. Intuitively, the novel ICoT requires VLMs to enable the generation of fine-grained interleaved-modal content, which is hard for current VLMs to fulfill. Considering that the required visual information is usually part of the input image, we propose \textbf{Attention-driven Selection (ADS)} to realize ICoT over existing VLMs. ADS intelligently inserts regions of the input image to generate the interleaved-modal reasoning steps with ignorable additional latency. ADS relies solely on the attention map of VLMs without the need for parameterization, and therefore it is a plug-and-play strategy that can be generalized to a spectrum of VLMs. We apply ADS to realize ICoT on two popular VLMs of different architectures. Extensive evaluations of three benchmarks have shown that ICoT prompting achieves substantial performance (up to 14\%) and interpretability improvements compared to existing multimodal CoT prompting methods.
PIP-MM: Pre-Integrating Prompt Information into Visual Encoding via Existing MLLM Structures
Oct 30, 2024


The Multimodal Large Language Models (MLLMs) have activated the capabilitiesof Large Language Models (LLMs) in solving visual-language tasks by integratingvisual information. The prevailing approach in existing MLLMs involvesemploying an image encoder to extract visual features, converting thesefeatures into visual tokens via an adapter, and then integrating them with theprompt into the LLM. However, because the process of image encoding isprompt-agnostic, the extracted visual features only provide a coarsedescription of the image, impossible to focus on the requirements of theprompt. On one hand, it is easy for image features to lack information aboutthe prompt-specified objects, resulting in unsatisfactory responses. On theother hand, the visual features contain a large amount of irrelevantinformation, which not only increases the burden on memory but also worsens thegeneration effectiveness. To address the aforementioned issues, we propose\textbf{PIP-MM}, a framework that \textbf{P}re-\textbf{I}ntegrates\textbf{P}rompt information into the visual encoding process using existingmodules of MLLMs. Specifically, We utilize the frozen LLM in the MLLM tovectorize the input prompt, which summarizes the requirements of the prompt.Then, we input the prompt vector into our trained Multi-Layer Perceptron (MLP)to align with the visual input requirements, and subsequently replace the classembedding in the image encoder. Since our model only requires adding atrainable MLP, it can be applied to any MLLM. To validate the effectiveness ofPIP-MM, we conducted experiments on multiple benchmarks. Automated evaluationmetrics and manual assessments demonstrate the strong performance of PIP-MM.Particularly noteworthy is that our model maintains excellent generationresults even when half of the visual tokens are reduced.
DNTextSpotter: Arbitrary-Shaped Scene Text Spotting via Improved Denoising Training
Aug 01, 2024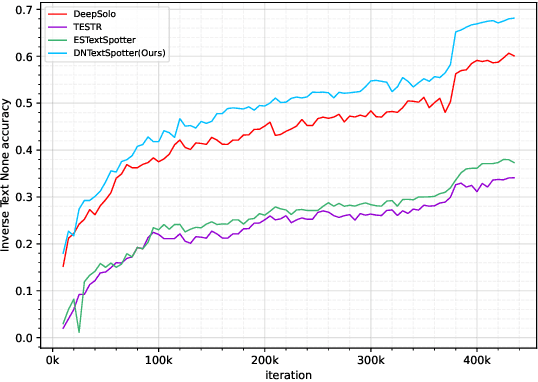
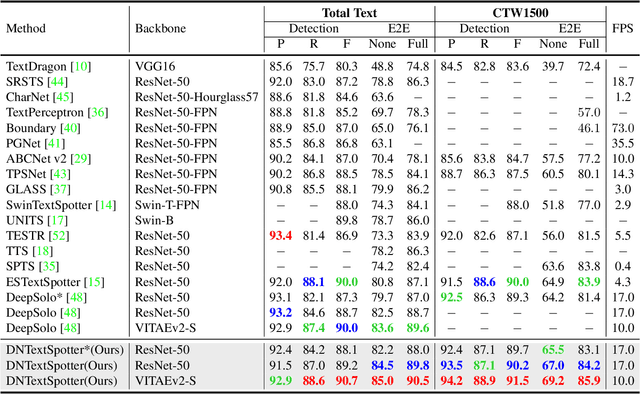
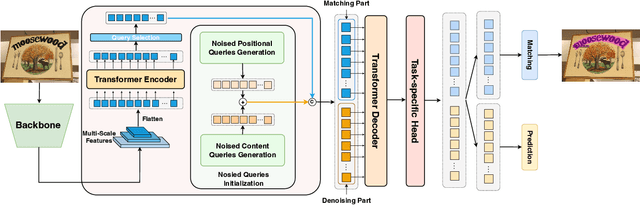
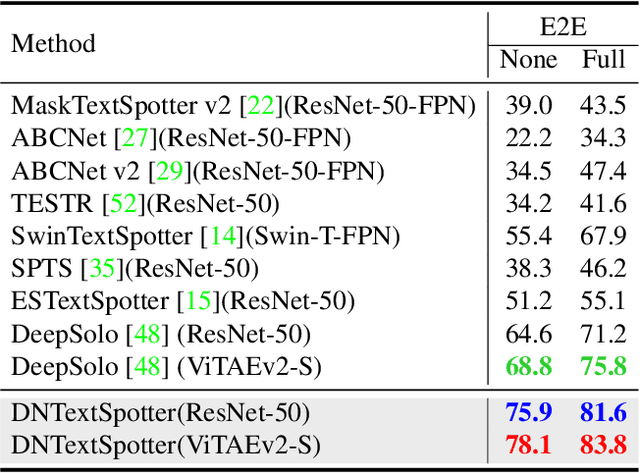
More and more end-to-end text spotting methods based on Transformer architecture have demonstrated superior performance. These methods utilize a bipartite graph matching algorithm to perform one-to-one optimal matching between predicted objects and actual objects. However, the instability of bipartite graph matching can lead to inconsistent optimization targets, thereby affecting the training performance of the model. Existing literature applies denoising training to solve the problem of bipartite graph matching instability in object detection tasks. Unfortunately, this denoising training method cannot be directly applied to text spotting tasks, as these tasks need to perform irregular shape detection tasks and more complex text recognition tasks than classification. To address this issue, we propose a novel denoising training method (DNTextSpotter) for arbitrary-shaped text spotting. Specifically, we decompose the queries of the denoising part into noised positional queries and noised content queries. We use the four Bezier control points of the Bezier center curve to generate the noised positional queries. For the noised content queries, considering that the output of the text in a fixed positional order is not conducive to aligning position with content, we employ a masked character sliding method to initialize noised content queries, thereby assisting in the alignment of text content and position. To improve the model's perception of the background, we further utilize an additional loss function for background characters classification in the denoising training part.Although DNTextSpotter is conceptually simple, it outperforms the state-of-the-art methods on four benchmarks (Total-Text, SCUT-CTW1500, ICDAR15, and Inverse-Text), especially yielding an improvement of 11.3% against the best approach in Inverse-Text dataset.
AIM: Let Any Multi-modal Large Language Models Embrace Efficient In-Context Learning
Jun 11, 2024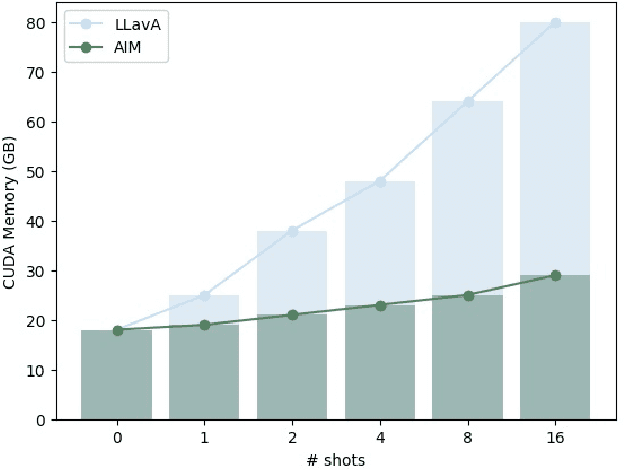

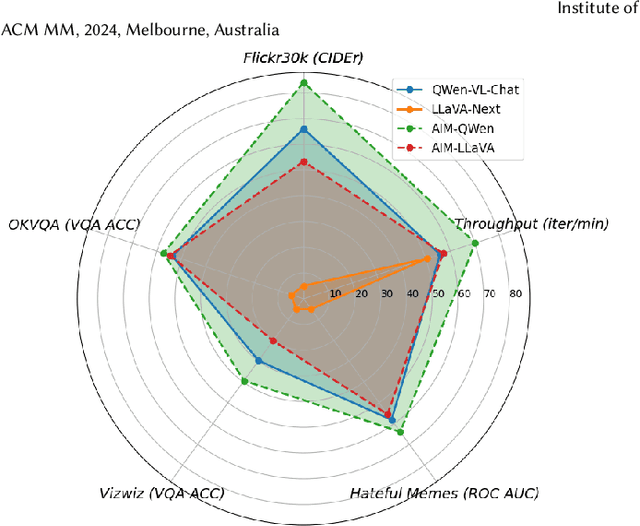
In-context learning (ICL) facilitates Large Language Models (LLMs) exhibiting emergent ability on downstream tasks without updating billions of parameters. However, in the area of multi-modal Large Language Models (MLLMs), two problems hinder the application of multi-modal ICL: (1) Most primary MLLMs are only trained on single-image datasets, making them unable to read multi-modal demonstrations. (2) With the demonstrations increasing, thousands of visual tokens highly challenge hardware and degrade ICL performance. During preliminary explorations, we discovered that the inner LLM tends to focus more on the linguistic modality within multi-modal demonstrations to generate responses. Therefore, we propose a general and light-weighted framework \textbf{AIM} to tackle the mentioned problems through \textbf{A}ggregating \textbf{I}mage information of \textbf{M}ultimodal demonstrations to the dense latent space of the corresponding linguistic part. Specifically, AIM first uses the frozen backbone MLLM to read each image-text demonstration and extracts the vector representations on top of the text. These vectors naturally fuse the information of the image-text pair, and AIM transforms them into fused virtual tokens acceptable for the inner LLM via a trainable projection layer. Ultimately, these fused tokens function as variants of multi-modal demonstrations, fed into the MLLM to direct its response to the current query as usual. Because these fused tokens stem from the textual component of the image-text pair, a multi-modal demonstration is nearly reduced to a pure textual demonstration, thus seamlessly applying to any MLLMs. With its de facto MLLM frozen, AIM is parameter-efficient and we train it on public multi-modal web corpora which have nothing to do with downstream test tasks.
Guiding ChatGPT to Generate Salient Domain Summaries
Jun 03, 2024



ChatGPT is instruct-tuned to generate general and human-expected content to align with human preference through Reinforcement Learning from Human Feedback (RLHF), meanwhile resulting in generated responses not salient enough. Therefore, in this case, ChatGPT may fail to satisfy domain requirements in zero-shot settings, leading to poor ROUGE scores. Inspired by the In-Context Learning (ICL) and retelling ability of ChatGPT, this paper proposes PADS, a \textbf{P}ipeline for \textbf{A}ssisting ChatGPT in \textbf{D}omain \textbf{S}ummarization. PADS consists of a retriever to retrieve similar examples from corpora and a rank model to rerank the multiple candidate summaries generated by ChatGPT. Specifically, given an inference document, we first retrieve an in-context demonstration via the retriever. Then, we require ChatGPT to generate $k$ candidate summaries for the inference document at a time under the guidance of the retrieved demonstration. Finally, the rank model independently scores the $k$ candidate summaries according to their quality and selects the optimal one. We extensively explore dense and sparse retrieval methods to select effective demonstrations for reference and efficiently train the rank model to reflect the quality of candidate summaries for each given summarized document. Additionally, PADS contains merely 400M trainable parameters originating from the rank model and we merely collect 2.5k data to train it. We evaluate PADS on five datasets from different domains, and the result indicates that each module in PADS is committed to effectively guiding ChatGPT to generate salient summaries fitting different domain requirements. Specifically, in the popular summarization dataset Gigaword, PADS achieves over +8 gain on ROUGE-L, compared with the naive ChatGPT in the zero-shot setting. \footnote{Our code are available at \url{https://github.com/jungao1106/PADS}}
Prompt Chaining or Stepwise Prompt? Refinement in Text Summarization
Jun 01, 2024



Large language models (LLMs) have demonstrated the capacity to improve summary quality by mirroring a human-like iterative process of critique and refinement starting from the initial draft. Two strategies are designed to perform this iterative process: Prompt Chaining and Stepwise Prompt. Prompt chaining orchestrates the drafting, critiquing, and refining phases through a series of three discrete prompts, while Stepwise prompt integrates these phases within a single prompt. However, the relative effectiveness of the two methods has not been extensively studied. This paper is dedicated to examining and comparing these two methods in the context of text summarization to ascertain which method stands out as the most effective. Experimental results show that the prompt chaining method can produce a more favorable outcome. This might be because stepwise prompt might produce a simulated refinement process according to our various experiments. Since refinement is adaptable to diverse tasks, our conclusions have the potential to be extrapolated to other applications, thereby offering insights that may contribute to the broader development of LLMs.