 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsEdit: Towards Instruction-based Visual Editing via Data-Efficient Video Diffusion Models Adaptation
Apr 09, 2026Instruction-based video editing is a natural way to control video content with text, but adapting a video generation model into an editor usually appears data-hungry. At the same time, high-quality video editing data remains scarce. In this paper, we show that a video generation backbone can become a strong video editor without large scale video editing data. We present InsEdit, an instruction-based editing model built on HunyuanVideo-1.5. InsEdit combines a visual editing architecture with a video data pipeline based on Mutual Context Attention (MCA), which creates aligned video pairs where edits can begin in the middle of a clip rather than only from the first frame. With only O(100)K video editing data, InsEdit achieves state-of-the-art results among open-source methods on our video instruction editing benchmarks. In addition, because our training recipe also includes image editing data, the final model supports image editing without any modification.
Hear You in Silence: Designing for Active Listening in Human Interaction with Conversational Agents Using Context-Aware Pacing
Feb 05, 2026In human conversation, empathic dialogue requires nuanced temporal cues indicating whether the conversational partner is paying attention. This type of "active listening" is overlooked in the design of Conversational Agents (CAs), which use the same pacing for one conversation. To model the temporal cues in human conversation, we need CAs that dynamically adjust response pacing according to user input. We qualitatively analyzed ten cases of active listening to distill five context-aware pacing strategies: Reflective Silence, Facilitative Silence, Empathic Silence, Holding Space, and Immediate Response. In a between-subjects study (N=50) with two conversational scenarios (relationship and career-support), the context-aware agent scored higher than static-pacing control on perceived human-likeness, smoothness, and interactivity, supporting deeper self-disclosure and higher engagement. In the career support scenario, the CA yielded higher perceived listening quality and affective trust. This work shows how insights from human conversation like context-aware pacing can empower the design of more empathic human-AI communication.
Multi-objective fluorescent molecule design with a data-physics dual-driven generative framework
Jan 20, 2026Designing fluorescent small molecules with tailored optical and physicochemical properties requires navigating vast, underexplored chemical space while satisfying multiple objectives and constraints. Conventional generate-score-screen approaches become impractical under such realistic design specifications, owing to their low search efficiency, unreliable generalizability of machine-learning prediction, and the prohibitive cost of quantum chemical calculation. Here we present LUMOS, a data-and-physics driven framework for inverse design of fluorescent molecules. LUMOS couples generator and predictor within a shared latent representation, enabling direct specification-to-molecule design and efficient exploration. Moreover, LUMOS combines neural networks with a fast time-dependent density functional theory (TD-DFT) calculation workflow to build a suite of complementary predictors spanning different trade-offs in speed, accuracy, and generalizability, enabling reliable property prediction across diverse scenarios. Finally, LUMOS employs a property-guided diffusion model integrated with multi-objective evolutionary algorithms, enabling de novo design and molecular optimization under multiple objectives and constraints. Across comprehensive benchmarks, LUMOS consistently outperforms baseline models in terms of accuracy, generalizability and physical plausibility for fluorescence property prediction, and demonstrates superior performance in multi-objective scaffold- and fragment-level molecular optimization. Further validation using TD-DFT and molecular dynamics (MD) simulations demonstrates that LUMOS can generate valid fluorophores that meet various target specifications. Overall, these results establish LUMOS as a data-physics dual-driven framework for general fluorophore inverse design.
Analyzing Cognitive Differences Among Large Language Models through the Lens of Social Worldview
May 04, 2025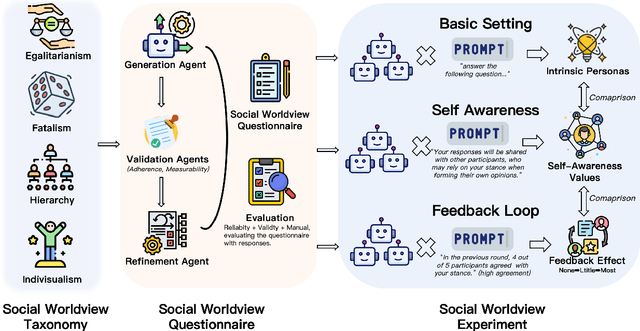

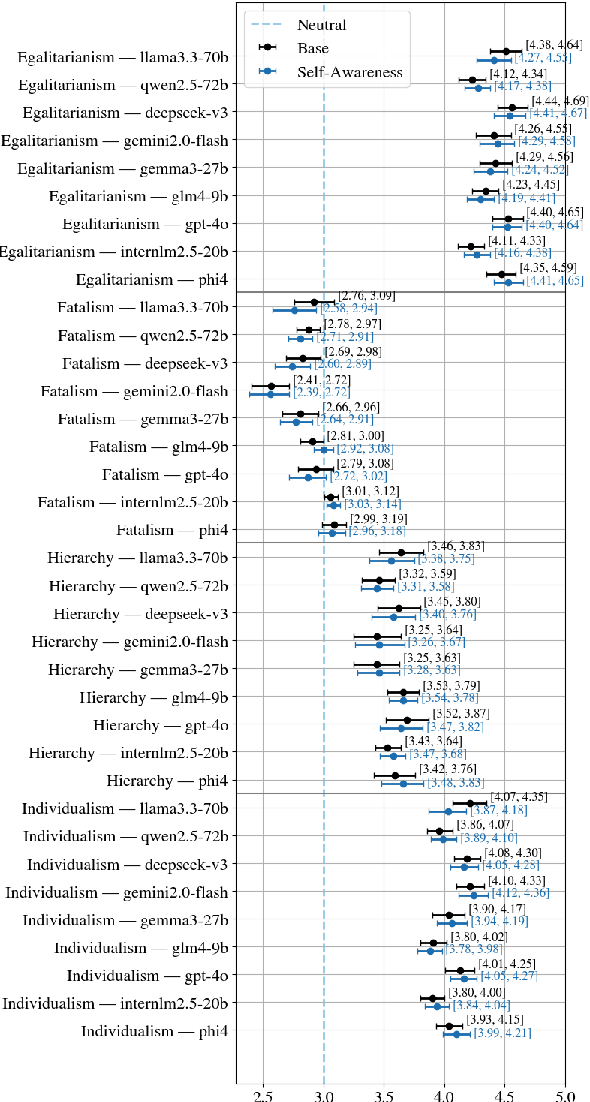
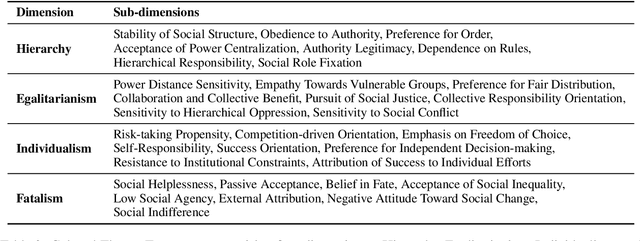
Large Language Models (LLMs) have become integral to daily life, widely adopted in communication, decision-making, and information retrieval, raising critical questions about how these systems implicitly form and express socio-cognitive attitudes or "worldviews". While existing research extensively addresses demographic and ethical biases, broader dimensions-such as attitudes toward authority, equality, autonomy, and fate-remain under-explored. In this paper, we introduce the Social Worldview Taxonomy (SWT), a structured framework grounded in Cultural Theory, operationalizing four canonical worldviews (Hierarchy, Egalitarianism, Individualism, Fatalism) into measurable sub-dimensions. Using SWT, we empirically identify distinct and interpretable cognitive profiles across 28 diverse LLMs. Further, inspired by Social Referencing Theory, we experimentally demonstrate that explicit social cues systematically shape these cognitive attitudes, revealing both general response patterns and nuanced model-specific variations. Our findings enhance the interpretability of LLMs by revealing implicit socio-cognitive biases and their responsiveness to social feedback, thus guiding the development of more transparent and socially responsible language technologies.
ProtTeX: Structure-In-Context Reasoning and Editing of Proteins with Large Language Models
Mar 13, 2025Large language models have made remarkable progress in the field of molecular science, particularly in understanding and generating functional small molecules. This success is largely attributed to the effectiveness of molecular tokenization strategies. In protein science, the amino acid sequence serves as the sole tokenizer for LLMs. However, many fundamental challenges in protein science are inherently structure-dependent. The absence of structure-aware tokens significantly limits the capabilities of LLMs for comprehensive biomolecular comprehension and multimodal generation. To address these challenges, we introduce a novel framework, ProtTeX, which tokenizes the protein sequences, structures, and textual information into a unified discrete space. This innovative approach enables joint training of the LLM exclusively through the Next-Token Prediction paradigm, facilitating multimodal protein reasoning and generation. ProtTeX enables general LLMs to perceive and process protein structures through sequential text input, leverage structural information as intermediate reasoning components, and generate or manipulate structures via sequential text output. Experiments demonstrate that our model achieves significant improvements in protein function prediction, outperforming the state-of-the-art domain expert model with a twofold increase in accuracy. Our framework enables high-quality conformational generation and customizable protein design. For the first time, we demonstrate that by adopting the standard training and inference pipelines from the LLM domain, ProtTeX empowers decoder-only LLMs to effectively address diverse spectrum of protein-related tasks.
ProTeX: Structure-In-Context Reasoning and Editing of Proteins with Large Language Models
Mar 11, 2025Large language models have made remarkable progress in the field of molecular science, particularly in understanding and generating functional small molecules. This success is largely attributed to the effectiveness of molecular tokenization strategies. In protein science, the amino acid sequence serves as the sole tokenizer for LLMs. However, many fundamental challenges in protein science are inherently structure-dependent. The absence of structure-aware tokens significantly limits the capabilities of LLMs for comprehensive biomolecular comprehension and multimodal generation. To address these challenges, we introduce a novel framework, ProTeX, which tokenizes the protein sequences, structures, and textual information into a unified discrete space. This innovative approach enables joint training of the LLM exclusively through the Next-Token Prediction paradigm, facilitating multimodal protein reasoning and generation. ProTeX enables general LLMs to perceive and process protein structures through sequential text input, leverage structural information as intermediate reasoning components, and generate or manipulate structures via sequential text output. Experiments demonstrate that our model achieves significant improvements in protein function prediction, outperforming the state-of-the-art domain expert model with a twofold increase in accuracy. Our framework enables high-quality conformational generation and customizable protein design. For the first time, we demonstrate that by adopting the standard training and inference pipelines from the LLM domain, ProTeX empowers decoder-only LLMs to effectively address diverse spectrum of protein-related tasks.
Aspect-Guided Multi-Level Perturbation Analysis of Large Language Models in Automated Peer Review
Feb 18, 2025We propose an aspect-guided, multi-level perturbation framework to evaluate the robustness of Large Language Models (LLMs) in automated peer review. Our framework explores perturbations in three key components of the peer review process-papers, reviews, and rebuttals-across several quality aspects, including contribution, soundness, presentation, tone, and completeness. By applying targeted perturbations and examining their effects on both LLM-as-Reviewer and LLM-as-Meta-Reviewer, we investigate how aspect-based manipulations, such as omitting methodological details from papers or altering reviewer conclusions, can introduce significant biases in the review process. We identify several potential vulnerabilities: review conclusions that recommend a strong reject may significantly influence meta-reviews, negative or misleading reviews may be wrongly interpreted as thorough, and incomplete or hostile rebuttals can unexpectedly lead to higher acceptance rates. Statistical tests show that these biases persist under various Chain-of-Thought prompting strategies, highlighting the lack of robust critical evaluation in current LLMs. Our framework offers a practical methodology for diagnosing these vulnerabilities, thereby contributing to the development of more reliable and robust automated reviewing systems.
V$^2$-SfMLearner: Learning Monocular Depth and Ego-motion for Multimodal Wireless Capsule Endoscopy
Dec 23, 2024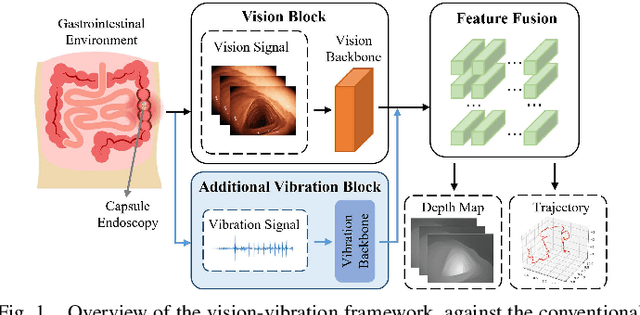
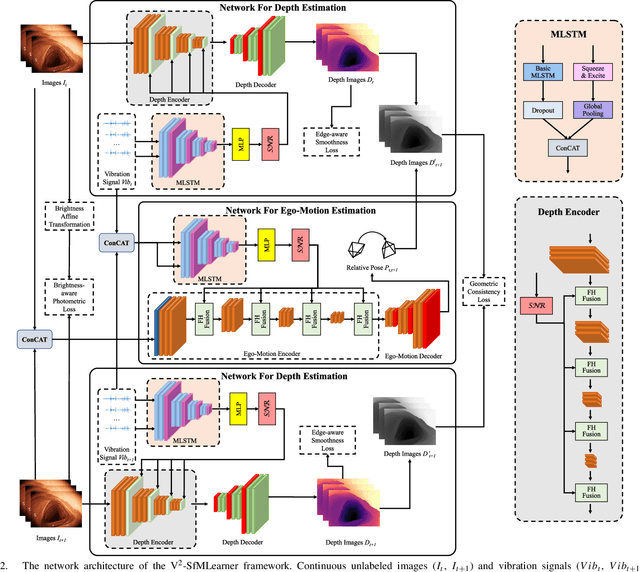
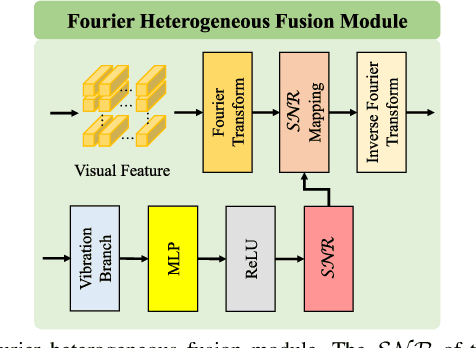
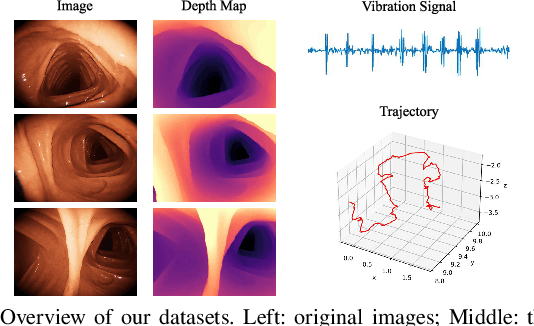
Deep learning can predict depth maps and capsule ego-motion from capsule endoscopy videos, aiding in 3D scene reconstruction and lesion localization. However, the collisions of the capsule endoscopies within the gastrointestinal tract cause vibration perturbations in the training data. Existing solutions focus solely on vision-based processing, neglecting other auxiliary signals like vibrations that could reduce noise and improve performance. Therefore, we propose V$^2$-SfMLearner, a multimodal approach integrating vibration signals into vision-based depth and capsule motion estimation for monocular capsule endoscopy. We construct a multimodal capsule endoscopy dataset containing vibration and visual signals, and our artificial intelligence solution develops an unsupervised method using vision-vibration signals, effectively eliminating vibration perturbations through multimodal learning. Specifically, we carefully design a vibration network branch and a Fourier fusion module, to detect and mitigate vibration noises. The fusion framework is compatible with popular vision-only algorithms. Extensive validation on the multimodal dataset demonstrates superior performance and robustness against vision-only algorithms. Without the need for large external equipment, our V$^2$-SfMLearner has the potential for integration into clinical capsule robots, providing real-time and dependable digestive examination tools. The findings show promise for practical implementation in clinical settings, enhancing the diagnostic capabilities of doctors.
EndoUIC: Promptable Diffusion Transformer for Unified Illumination Correction in Capsule Endoscopy
Jun 19, 2024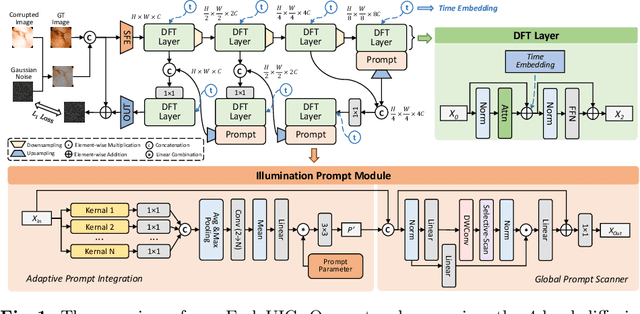



Wireless Capsule Endoscopy (WCE) is highly valued for its non-invasive and painless approach, though its effectiveness is compromised by uneven illumination from hardware constraints and complex internal dynamics, leading to overexposed or underexposed images. While researchers have discussed the challenges of low-light enhancement in WCE, the issue of correcting for different exposure levels remains underexplored. To tackle this, we introduce EndoUIC, a WCE unified illumination correction solution using an end-to-end promptable diffusion transformer (DFT) model. In our work, the illumination prompt module shall navigate the model to adapt to different exposure levels and perform targeted image enhancement, in which the Adaptive Prompt Integration (API) and Global Prompt Scanner (GPS) modules shall further boost the concurrent representation learning between the prompt parameters and features. Besides, the U-shaped restoration DFT model shall capture the long-range dependencies and contextual information for unified illumination restoration. Moreover, we present a novel Capsule-endoscopy Exposure Correction (CEC) dataset, including ground-truth and corrupted image pairs annotated by expert photographers. Extensive experiments against a variety of state-of-the-art (SOTA) methods on four datasets showcase the effectiveness of our proposed method and components in WCE illumination restoration, and the additional downstream experiments further demonstrate its utility for clinical diagnosis and surgical assistance.
"Nice to meet you!": Expressing Emotions with Movement Gestures and Textual Content in Automatic Handwriting Robots
Feb 12, 2023



Text-writing robots have been used in assistive writing and drawing applications. However, robots do not convey emotional tones in the writing process due to the lack of behaviors humans typically adopt. To examine how people interpret designed robotic expressions of emotion through both movements and textual output, we used a pen-plotting robot to generate texts by performing human-like behaviors like stop-and-go, speed, and pressure variation. We examined how people convey emotion in the writing process by observing how they wrote in different emotional contexts. We then mapped these human expressions during writing to the handwriting robot and measured how well other participants understood the robot's affective expression. We found that textual output was the strongest determinant of participants' ability to perceive the robot's emotions, whereas parameters of gestural movements of the robots like speed, fluency, pressure, size, and acceleration could be useful for understanding the context of the writing expression.