 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV$^2$-SfMLearner: Learning Monocular Depth and Ego-motion for Multimodal Wireless Capsule Endoscopy
Dec 23, 2024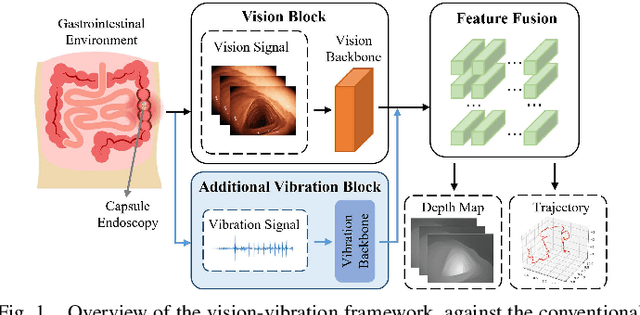
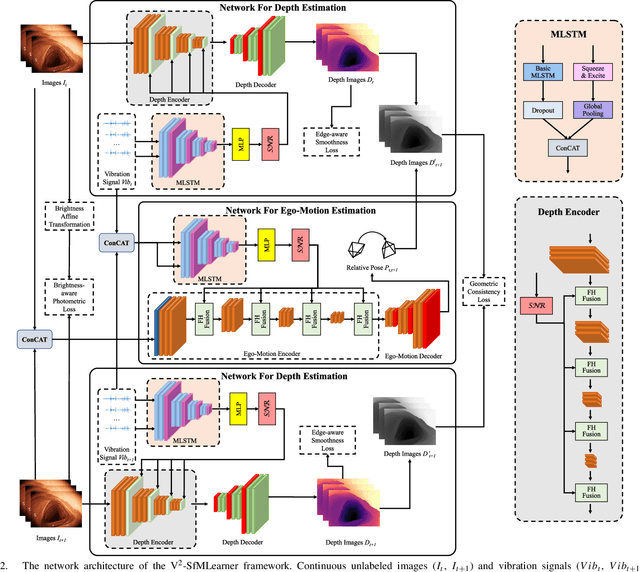
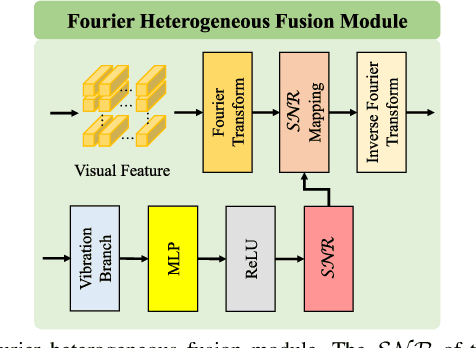
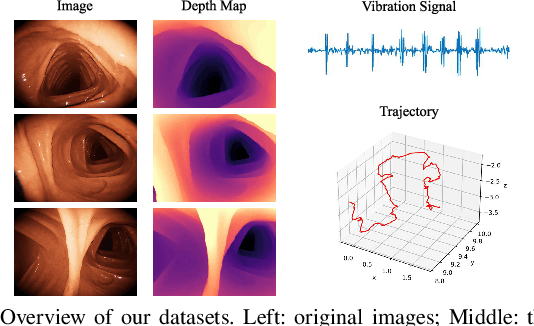
Deep learning can predict depth maps and capsule ego-motion from capsule endoscopy videos, aiding in 3D scene reconstruction and lesion localization. However, the collisions of the capsule endoscopies within the gastrointestinal tract cause vibration perturbations in the training data. Existing solutions focus solely on vision-based processing, neglecting other auxiliary signals like vibrations that could reduce noise and improve performance. Therefore, we propose V$^2$-SfMLearner, a multimodal approach integrating vibration signals into vision-based depth and capsule motion estimation for monocular capsule endoscopy. We construct a multimodal capsule endoscopy dataset containing vibration and visual signals, and our artificial intelligence solution develops an unsupervised method using vision-vibration signals, effectively eliminating vibration perturbations through multimodal learning. Specifically, we carefully design a vibration network branch and a Fourier fusion module, to detect and mitigate vibration noises. The fusion framework is compatible with popular vision-only algorithms. Extensive validation on the multimodal dataset demonstrates superior performance and robustness against vision-only algorithms. Without the need for large external equipment, our V$^2$-SfMLearner has the potential for integration into clinical capsule robots, providing real-time and dependable digestive examination tools. The findings show promise for practical implementation in clinical settings, enhancing the diagnostic capabilities of doctors.
Joint Sparse Representations and Coupled Dictionary Learning in Multi-Source Heterogeneous Image Pseudo-color Fusion
Oct 15, 2023



Considering that Coupled Dictionary Learning (CDL) method can obtain a reasonable linear mathematical relationship between resource images, we propose a novel CDL-based Synthetic Aperture Radar (SAR) and multispectral pseudo-color fusion method. Firstly, the traditional Brovey transform is employed as a pre-processing method on the paired SAR and multispectral images. Then, CDL is used to capture the correlation between the pre-processed image pairs based on the dictionaries generated from the source images via enforced joint sparse coding. Afterward, the joint sparse representation in the pair of dictionaries is utilized to construct an image mask via calculating the reconstruction errors, and therefore generate the final fusion image. The experimental verification results of the SAR images from the Sentinel-1 satellite and the multispectral images from the Landsat-8 satellite show that the proposed method can achieve superior visual effects, and excellent quantitative performance in terms of spectral distortion, correlation coefficient, MSE, NIQE, BRISQUE, and PIQE.
Efficient RRT*-based Safety-Constrained Motion Planning for Continuum Robots in Dynamic Environments
Sep 25, 2023



Continuum robots, characterized by their high flexibility and infinite degrees of freedom (DoFs), have gained prominence in applications such as minimally invasive surgery and hazardous environment exploration. However, the intrinsic complexity of continuum robots requires a significant amount of time for their motion planning, posing a hurdle to their practical implementation. To tackle these challenges, efficient motion planning methods such as Rapidly Exploring Random Trees (RRT) and its variant, RRT*, have been employed. This paper introduces a unique RRT*-based motion control method tailored for continuum robots. Our approach embeds safety constraints derived from the robots' posture states, facilitating autonomous navigation and obstacle avoidance in rapidly changing environments. Simulation results show efficient trajectory planning amidst multiple dynamic obstacles and provide a robust performance evaluation based on the generated postures. Finally, preliminary tests were conducted on a two-segment cable-driven continuum robot prototype, confirming the effectiveness of the proposed planning approach. This method is versatile and can be adapted and deployed for various types of continuum robots through parameter adjustments.