 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Perceptual to Conceptual First-Order Rule Learning Networks
Apr 09, 2026Learning rules plays a crucial role in deep learning, particularly in explainable artificial intelligence and enhancing the reasoning capabilities of large language models. While existing rule learning methods are primarily designed for symbolic data, learning rules from image data without supporting image labels and automatically inventing predicates remains a challenge. In this paper, we tackle these inductive rule learning problems from images with a framework called γILP, which provides a fully differentiable pipeline from image constant substitution to rule structure induction. Extensive experiments demonstrate that γILP achieves strong performance not only on classical symbolic relational datasets but also on relational image data and pure image datasets, such as Kandinsky patterns.
Differentiable Rule Induction from Raw Sequence Inputs
Feb 14, 2026Rule learning-based models are widely used in highly interpretable scenarios due to their transparent structures. Inductive logic programming (ILP), a form of machine learning, induces rules from facts while maintaining interpretability. Differentiable ILP models enhance this process by leveraging neural networks to improve robustness and scalability. However, most differentiable ILP methods rely on symbolic datasets, facing challenges when learning directly from raw data. Specifically, they struggle with explicit label leakage: The inability to map continuous inputs to symbolic variables without explicit supervision of input feature labels. In this work, we address this issue by integrating a self-supervised differentiable clustering model with a novel differentiable ILP model, enabling rule learning from raw data without explicit label leakage. The learned rules effectively describe raw data through its features. We demonstrate that our method intuitively and precisely learns generalized rules from time series and image data.
R-Tuning: Wavelet-Decomposed Replay and Semantic Alignment for Continual Adaptation of Pretrained Time-Series Models
Nov 12, 2025Pre-trained models have demonstrated exceptional generalization capabilities in time-series forecasting; however, adapting them to evolving data distributions remains a significant challenge. A key hurdle lies in accessing the original training data, as fine-tuning solely on new data often leads to catastrophic forgetting. To address this issue, we propose Replay Tuning (R-Tuning), a novel framework designed for the continual adaptation of pre-trained time-series models. R-Tuning constructs a unified latent space that captures both prior and current task knowledge through a frequency-aware replay strategy. Specifically, it augments model-generated samples via wavelet-based decomposition across multiple frequency bands, generating trend-preserving and fusion-enhanced variants to improve representation diversity and replay efficiency. To further reduce reliance on synthetic samples, R-Tuning introduces a latent consistency constraint that aligns new representations with the prior task space. This constraint guides joint optimization within a compact and semantically coherent latent space, ensuring robust knowledge retention and adaptation. Extensive experimental results demonstrate the superiority of R-Tuning, which reduces MAE and MSE by up to 46.9% and 46.8%, respectively, on new tasks, while preserving prior knowledge with gains of up to 5.7% and 6.0% on old tasks. Notably, under few-shot settings, R-Tuning outperforms all state-of-the-art baselines even when synthetic proxy samples account for only 5% of the new task dataset.
Data Duplication: A Novel Multi-Purpose Attack Paradigm in Machine Unlearning
Jan 28, 2025



Duplication is a prevalent issue within datasets. Existing research has demonstrated that the presence of duplicated data in training datasets can significantly influence both model performance and data privacy. However, the impact of data duplication on the unlearning process remains largely unexplored. This paper addresses this gap by pioneering a comprehensive investigation into the role of data duplication, not only in standard machine unlearning but also in federated and reinforcement unlearning paradigms. Specifically, we propose an adversary who duplicates a subset of the target model's training set and incorporates it into the training set. After training, the adversary requests the model owner to unlearn this duplicated subset, and analyzes the impact on the unlearned model. For example, the adversary can challenge the model owner by revealing that, despite efforts to unlearn it, the influence of the duplicated subset remains in the model. Moreover, to circumvent detection by de-duplication techniques, we propose three novel near-duplication methods for the adversary, each tailored to a specific unlearning paradigm. We then examine their impacts on the unlearning process when de-duplication techniques are applied. Our findings reveal several crucial insights: 1) the gold standard unlearning method, retraining from scratch, fails to effectively conduct unlearning under certain conditions; 2) unlearning duplicated data can lead to significant model degradation in specific scenarios; and 3) meticulously crafted duplicates can evade detection by de-duplication methods.
Probabilistic Prediction of Longitudinal Trajectory Considering Driving Heterogeneity with Interpretability
Dec 19, 2023



Automated vehicles are envisioned to navigate safely in complex mixed-traffic scenarios alongside human-driven vehicles. To promise a high degree of safety, accurately predicting the maneuvers of surrounding vehicles and their future positions is a critical task and attracts much attention. However, most existing studies focused on reasoning about positional information based on objective historical trajectories without fully considering the heterogeneity of driving behaviors. Therefore, this study proposes a trajectory prediction framework that combines Mixture Density Networks (MDN) and considers the driving heterogeneity to provide probabilistic and personalized predictions. Specifically, based on a certain length of historical trajectory data, the situation-specific driving preferences of each driver are identified, where key driving behavior feature vectors are extracted to characterize heterogeneity in driving behavior among different drivers. With the inputs of the short-term historical trajectory data and key driving behavior feature vectors, a probabilistic LSTMMD-DBV model combined with LSTM-based encoder-decoder networks and MDN layers is utilized to carry out personalized predictions. Finally, the SHapley Additive exPlanations (SHAP) method is employed to interpret the trained model for predictions. The proposed framework is tested based on a wide-range vehicle trajectory dataset. The results indicate that the proposed model can generate probabilistic future trajectories with remarkably improved predictions compared to existing benchmark models. Moreover, the results confirm that the additional input of driving behavior feature vectors representing the heterogeneity of driving behavior could provide more information and thus contribute to improving the prediction accuracy.
Joint Sparse Representations and Coupled Dictionary Learning in Multi-Source Heterogeneous Image Pseudo-color Fusion
Oct 15, 2023



Considering that Coupled Dictionary Learning (CDL) method can obtain a reasonable linear mathematical relationship between resource images, we propose a novel CDL-based Synthetic Aperture Radar (SAR) and multispectral pseudo-color fusion method. Firstly, the traditional Brovey transform is employed as a pre-processing method on the paired SAR and multispectral images. Then, CDL is used to capture the correlation between the pre-processed image pairs based on the dictionaries generated from the source images via enforced joint sparse coding. Afterward, the joint sparse representation in the pair of dictionaries is utilized to construct an image mask via calculating the reconstruction errors, and therefore generate the final fusion image. The experimental verification results of the SAR images from the Sentinel-1 satellite and the multispectral images from the Landsat-8 satellite show that the proposed method can achieve superior visual effects, and excellent quantitative performance in terms of spectral distortion, correlation coefficient, MSE, NIQE, BRISQUE, and PIQE.
Reinforcement Logic Rule Learning for Temporal Point Processes
Aug 11, 2023We propose a framework that can incrementally expand the explanatory temporal logic rule set to explain the occurrence of temporal events. Leveraging the temporal point process modeling and learning framework, the rule content and weights will be gradually optimized until the likelihood of the observational event sequences is optimal. The proposed algorithm alternates between a master problem, where the current rule set weights are updated, and a subproblem, where a new rule is searched and included to best increase the likelihood. The formulated master problem is convex and relatively easy to solve using continuous optimization, whereas the subproblem requires searching the huge combinatorial rule predicate and relationship space. To tackle this challenge, we propose a neural search policy to learn to generate the new rule content as a sequence of actions. The policy parameters will be trained end-to-end using the reinforcement learning framework, where the reward signals can be efficiently queried by evaluating the subproblem objective. The trained policy can be used to generate new rules in a controllable way. We evaluate our methods on both synthetic and real healthcare datasets, obtaining promising results.
Learning First-Order Rules with Differentiable Logic Program Semantics
Apr 28, 2022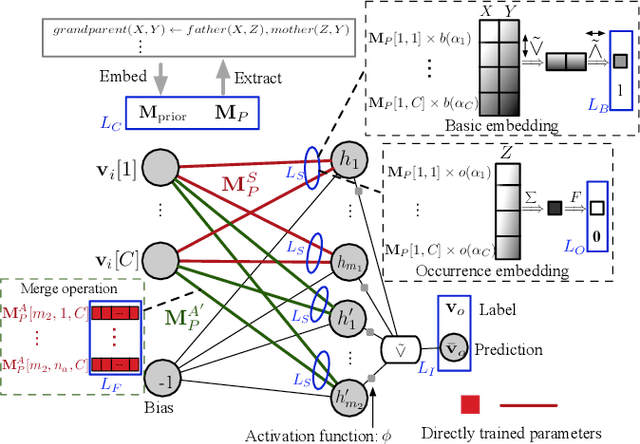
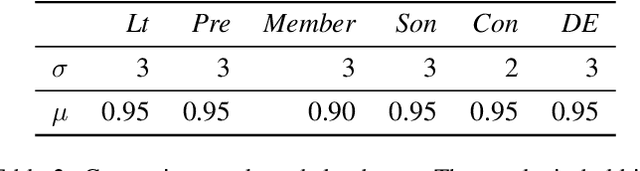

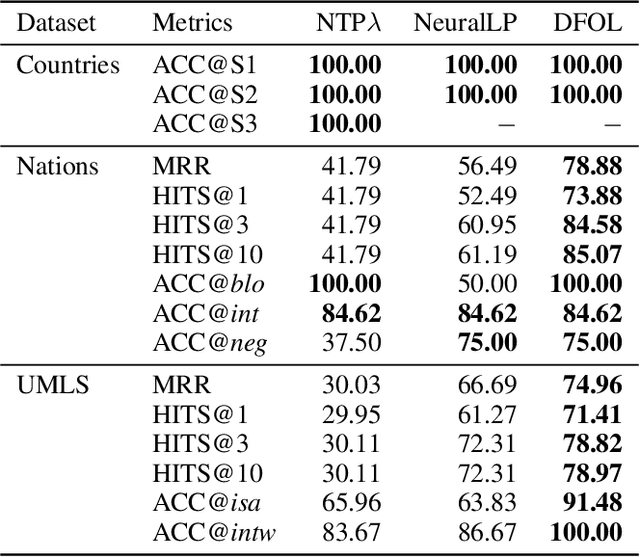
Learning first-order logic programs (LPs) from relational facts which yields intuitive insights into the data is a challenging topic in neuro-symbolic research. We introduce a novel differentiable inductive logic programming (ILP) model, called differentiable first-order rule learner (DFOL), which finds the correct LPs from relational facts by searching for the interpretable matrix representations of LPs. These interpretable matrices are deemed as trainable tensors in neural networks (NNs). The NNs are devised according to the differentiable semantics of LPs. Specifically, we first adopt a novel propositionalization method that transfers facts to NN-readable vector pairs representing interpretation pairs. We replace the immediate consequence operator with NN constraint functions consisting of algebraic operations and a sigmoid-like activation function. We map the symbolic forward-chained format of LPs into NN constraint functions consisting of operations between subsymbolic vector representations of atoms. By applying gradient descent, the trained well parameters of NNs can be decoded into precise symbolic LPs in forward-chained logic format. We demonstrate that DFOL can perform on several standard ILP datasets, knowledge bases, and probabilistic relation facts and outperform several well-known differentiable ILP models. Experimental results indicate that DFOL is a precise, robust, scalable, and computationally cheap differentiable ILP model.
Multi-Site Infant Brain Segmentation Algorithms: The iSeg-2019 Challenge
Jul 11, 2020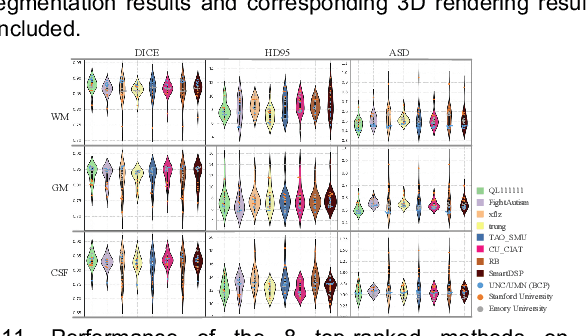
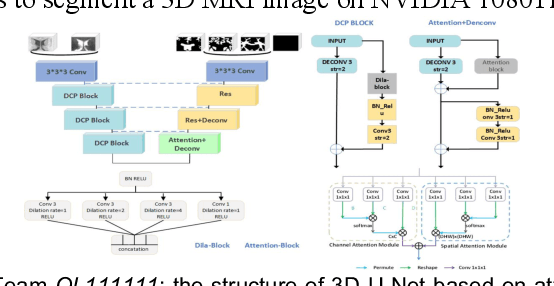
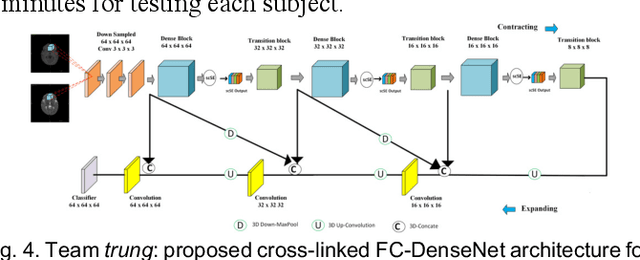
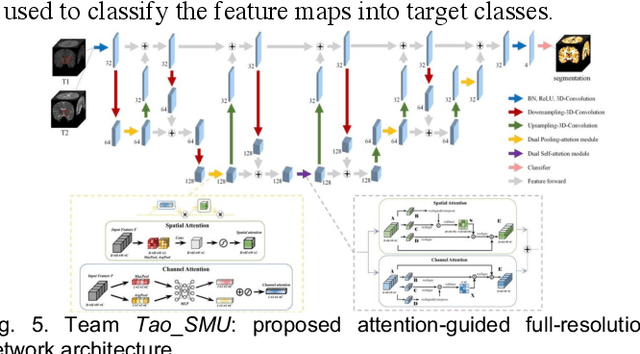
To better understand early brain growth patterns in health and disorder, it is critical to accurately segment infant brain magnetic resonance (MR) images into white matter (WM), gray matter (GM), and cerebrospinal fluid (CSF). Deep learning-based methods have achieved state-of-the-art performance; however, one of major limitations is that the learning-based methods may suffer from the multi-site issue, that is, the models trained on a dataset from one site may not be applicable to the datasets acquired from other sites with different imaging protocols/scanners. To promote methodological development in the community, iSeg-2019 challenge (http://iseg2019.web.unc.edu) provides a set of 6-month infant subjects from multiple sites with different protocols/scanners for the participating methods. Training/validation subjects are from UNC (MAP) and testing subjects are from UNC/UMN (BCP), Stanford University, and Emory University. By the time of writing, there are 30 automatic segmentation methods participating in iSeg-2019. We review the 8 top-ranked teams by detailing their pipelines/implementations, presenting experimental results and evaluating performance in terms of the whole brain, regions of interest, and gyral landmark curves. We also discuss their limitations and possible future directions for the multi-site issue. We hope that the multi-site dataset in iSeg-2019 and this review article will attract more researchers on the multi-site issue.
An Effective Training Method For Deep Convolutional Neural Network
Oct 17, 2017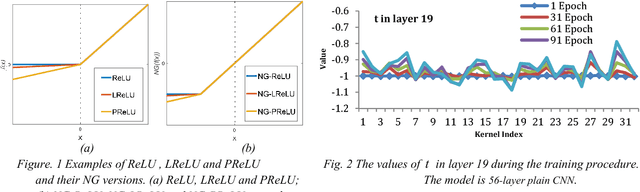

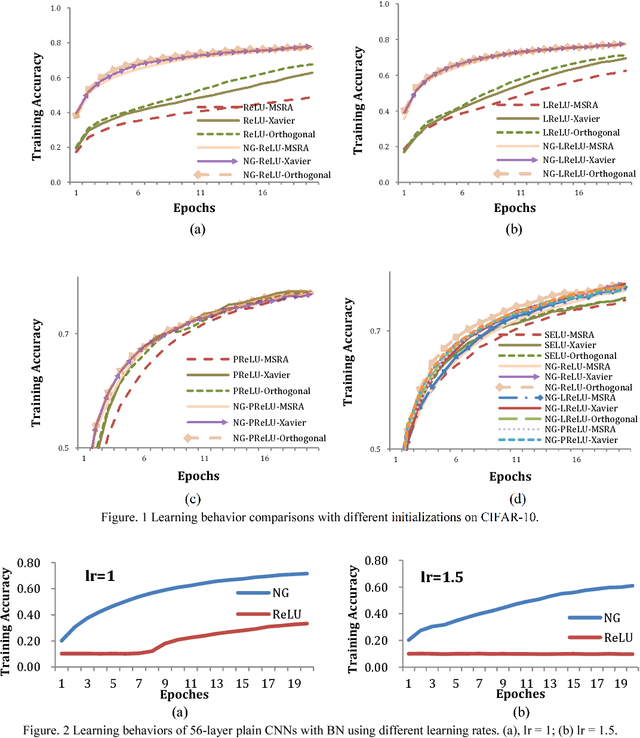
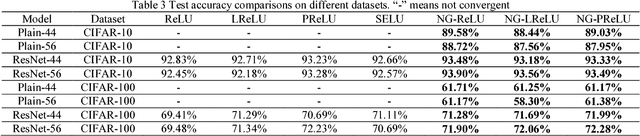
In this paper, we propose the nonlinearity generation method to speed up and stabilize the training of deep convolutional neural networks. The proposed method modifies a family of activation functions as nonlinearity generators (NGs). NGs make the activation functions linear symmetric for their inputs to lower model capacity, and automatically introduce nonlinearity to enhance the capacity of the model during training. The proposed method can be considered an unusual form of regularization: the model parameters are obtained by training a relatively low-capacity model, that is relatively easy to optimize at the beginning, with only a few iterations, and these parameters are reused for the initialization of a higher-capacity model. We derive the upper and lower bounds of variance of the weight variation, and show that the initial symmetric structure of NGs helps stabilize training. We evaluate the proposed method on different frameworks of convolutional neural networks over two object recognition benchmark tasks (CIFAR-10 and CIFAR-100). Experimental results showed that the proposed method allows us to (1) speed up the convergence of training, (2) allow for less careful weight initialization, (3) improve or at least maintain the performance of the model at negligible extra computational cost, and (4) easily train a very deep model.