 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraint-Based Analysis of Reasoning Shortcuts in Neurosymbolic Learning
Apr 25, 2026Neurosymbolic systems can satisfy logical constraints during learning without achieving the intended concept-label correspondence; this is a problem known as reasoning shortcuts. We formalize reasoning shortcuts as a constraint satisfaction problem and investigate under which conditions concept mappings are uniquely determined by the constraints. We prove that a discrimination property (requiring that no valid concept mapping can be transformed into another valid mapping by swapping two concept values) is necessary for shortcut-freeness under bijective mappings, but demonstrate via a counterexample that it is insufficient even when the constraint graph is connected. We develop an ASP-based algorithm that verifies whether a given constraint set uniquely determines the intended concept mapping, with proven soundness and completeness. When shortcuts are detected, a greedy repair algorithm eliminates them by augmenting the constraint set, converging in at most $k$ iterations, where $k$ is the number of alternative valid mappings. We further provide a complexity classification: deciding shortcut-freeness is coNP-complete, counting shortcuts is #P-complete, and finding minimal repairs is NP-hard. We also establish sample complexity bounds showing that logarithmically many label queries suffice for disambiguation in favorable cases, while querying all ambiguous positions suffices in the worst case. Experiments across eight benchmark domains validate our approach.
Inferring High-Level Events from Timestamped Data: Complexity and Medical Applications
Apr 23, 2026In this paper, we develop a novel logic-based approach to detecting high-level temporally extended events from timestamped data and background knowledge. Our framework employs logical rules to capture existence and termination conditions for simple temporal events and to combine these into meta-events. In the medical domain, for example, disease episodes and therapies are inferred from timestamped clinical observations, such as diagnoses and drug administrations stored in patient records, and can be further combined into higher-level disease events. As some incorrect events might be inferred, we use constraints to identify incompatible combinations of events and propose a repair mechanism to select preferred consistent sets of events. While reasoning in the full framework is intractable, we identify relevant restrictions that ensure polynomial-time data complexity. Our prototype system implements core components of the approach using answer set programming. An evaluation on a lung cancer use case supports the interest of the approach, both in terms of computational feasibility and positive alignment of our results with medical expert opinions. While strongly motivated by the needs of the healthcare domain, our framework is purposely generic, enabling its reuse in other areas.
Visual Perceptual to Conceptual First-Order Rule Learning Networks
Apr 09, 2026Learning rules plays a crucial role in deep learning, particularly in explainable artificial intelligence and enhancing the reasoning capabilities of large language models. While existing rule learning methods are primarily designed for symbolic data, learning rules from image data without supporting image labels and automatically inventing predicates remains a challenge. In this paper, we tackle these inductive rule learning problems from images with a framework called γILP, which provides a fully differentiable pipeline from image constant substitution to rule structure induction. Extensive experiments demonstrate that γILP achieves strong performance not only on classical symbolic relational datasets but also on relational image data and pure image datasets, such as Kandinsky patterns.
Differentiable Rule Induction from Raw Sequence Inputs
Feb 14, 2026Rule learning-based models are widely used in highly interpretable scenarios due to their transparent structures. Inductive logic programming (ILP), a form of machine learning, induces rules from facts while maintaining interpretability. Differentiable ILP models enhance this process by leveraging neural networks to improve robustness and scalability. However, most differentiable ILP methods rely on symbolic datasets, facing challenges when learning directly from raw data. Specifically, they struggle with explicit label leakage: The inability to map continuous inputs to symbolic variables without explicit supervision of input feature labels. In this work, we address this issue by integrating a self-supervised differentiable clustering model with a novel differentiable ILP model, enabling rule learning from raw data without explicit label leakage. The learned rules effectively describe raw data through its features. We demonstrate that our method intuitively and precisely learns generalized rules from time series and image data.
Formally Explaining Decision Tree Models with Answer Set Programming
Jan 07, 2026Decision tree models, including random forests and gradient-boosted decision trees, are widely used in machine learning due to their high predictive performance. However, their complex structures often make them difficult to interpret, especially in safety-critical applications where model decisions require formal justification. Recent work has demonstrated that logical and abductive explanations can be derived through automated reasoning techniques. In this paper, we propose a method for generating various types of explanations, namely, sufficient, contrastive, majority, and tree-specific explanations, using Answer Set Programming (ASP). Compared to SAT-based approaches, our ASP-based method offers greater flexibility in encoding user preferences and supports enumeration of all possible explanations. We empirically evaluate the approach on a diverse set of datasets and demonstrate its effectiveness and limitations compared to existing methods.
* In Proceedings ICLP 2025, arXiv:2601.00047
A Rule-Based Approach to Specifying Preferences over Conflicting Facts and Querying Inconsistent Knowledge Bases
Aug 11, 2025Repair-based semantics have been extensively studied as a means of obtaining meaningful answers to queries posed over inconsistent knowledge bases (KBs). While several works have considered how to exploit a priority relation between facts to select optimal repairs, the question of how to specify such preferences remains largely unaddressed. This motivates us to introduce a declarative rule-based framework for specifying and computing a priority relation between conflicting facts. As the expressed preferences may contain undesirable cycles, we consider the problem of determining when a set of preference rules always yields an acyclic relation, and we also explore a pragmatic approach that extracts an acyclic relation by applying various cycle removal techniques. Towards an end-to-end system for querying inconsistent KBs, we present a preliminary implementation and experimental evaluation of the framework, which employs answer set programming to evaluate the preference rules, apply the desired cycle resolution techniques to obtain a priority relation, and answer queries under prioritized-repair semantics.
Neural Logic Networks for Interpretable Classification
Aug 11, 2025Traditional neural networks have an impressive classification performance, but what they learn cannot be inspected, verified or extracted. Neural Logic Networks on the other hand have an interpretable structure that enables them to learn a logical mechanism relating the inputs and outputs with AND and OR operations. We generalize these networks with NOT operations and biases that take into account unobserved data and develop a rigorous logical and probabilistic modeling in terms of concept combinations to motivate their use. We also propose a novel factorized IF-THEN rule structure for the model as well as a modified learning algorithm. Our method improves the state-of-the-art in Boolean networks discovery and is able to learn relevant, interpretable rules in tabular classification, notably on an example from the medical field where interpretability has tangible value.
Neuro-Symbolic Contrastive Learning for Cross-domain Inference
Feb 13, 2025Pre-trained language models (PLMs) have made significant advances in natural language inference (NLI) tasks, however their sensitivity to textual perturbations and dependence on large datasets indicate an over-reliance on shallow heuristics. In contrast, inductive logic programming (ILP) excels at inferring logical relationships across diverse, sparse and limited datasets, but its discrete nature requires the inputs to be precisely specified, which limits their application. This paper proposes a bridge between the two approaches: neuro-symbolic contrastive learning. This allows for smooth and differentiable optimisation that improves logical accuracy across an otherwise discrete, noisy, and sparse topological space of logical functions. We show that abstract logical relationships can be effectively embedded within a neuro-symbolic paradigm, by representing data as logic programs and sets of logic rules. The embedding space captures highly varied textual information with similar semantic logical relations, but can also separate similar textual relations that have dissimilar logical relations. Experimental results demonstrate that our approach significantly improves the inference capabilities of the models in terms of generalisation and reasoning.
* In Proceedings ICLP 2024, arXiv:2502.08453
Transformers Use Causal World Models in Maze-Solving Tasks
Dec 16, 2024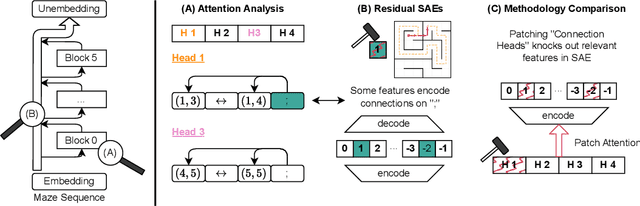



Recent studies in interpretability have explored the inner workings of transformer models trained on tasks across various domains, often discovering that these networks naturally develop surprisingly structured representations. When such representations comprehensively reflect the task domain's structure, they are commonly referred to as ``World Models'' (WMs). In this work, we discover such WMs in transformers trained on maze tasks. In particular, by employing Sparse Autoencoders (SAEs) and analysing attention patterns, we examine the construction of WMs and demonstrate consistency between the circuit analysis and the SAE feature-based analysis. We intervene upon the isolated features to confirm their causal role and, in doing so, find asymmetries between certain types of interventions. Surprisingly, we find that models are able to reason with respect to a greater number of active features than they see during training, even if attempting to specify these in the input token sequence would lead the model to fail. Futhermore, we observe that varying positional encodings can alter how WMs are encoded in a model's residual stream. By analyzing the causal role of these WMs in a toy domain we hope to make progress toward an understanding of emergent structure in the representations acquired by Transformers, leading to the development of more interpretable and controllable AI systems.
Generating Global and Local Explanations for Tree-Ensemble Learning Methods by Answer Set Programming
Oct 14, 2024



We propose a method for generating rule sets as global and local explanations for tree-ensemble learning methods using Answer Set Programming (ASP). To this end, we adopt a decompositional approach where the split structures of the base decision trees are exploited in the construction of rules, which in turn are assessed using pattern mining methods encoded in ASP to extract explanatory rules. For global explanations, candidate rules are chosen from the entire trained tree-ensemble models, whereas for local explanations, candidate rules are selected by only considering rules that are relevant to the particular predicted instance. We show how user-defined constraints and preferences can be represented declaratively in ASP to allow for transparent and flexible rule set generation, and how rules can be used as explanations to help the user better understand the models. Experimental evaluation with real-world datasets and popular tree-ensemble algorithms demonstrates that our approach is applicable to a wide range of classification tasks. Under consideration in Theory and Practice of Logic Programming (TPLP).