 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Fixed Tasks: Unsupervised Environment Design for Task-Level Pairs
Nov 16, 2025Training general agents to follow complex instructions (tasks) in intricate environments (levels) remains a core challenge in reinforcement learning. Random sampling of task-level pairs often produces unsolvable combinations, highlighting the need to co-design tasks and levels. While unsupervised environment design (UED) has proven effective at automatically designing level curricula, prior work has only considered a fixed task. We present ATLAS (Aligning Tasks and Levels for Autocurricula of Specifications), a novel method that generates joint autocurricula over tasks and levels. Our approach builds upon UED to automatically produce solvable yet challenging task-level pairs for policy training. To evaluate ATLAS and drive progress in the field, we introduce an evaluation suite that models tasks as reward machines in Minigrid levels. Experiments demonstrate that ATLAS vastly outperforms random sampling approaches, particularly when sampling solvable pairs is unlikely. We further show that mutations leveraging the structure of both tasks and levels accelerate convergence to performant policies.
Transformers Use Causal World Models in Maze-Solving Tasks
Dec 16, 2024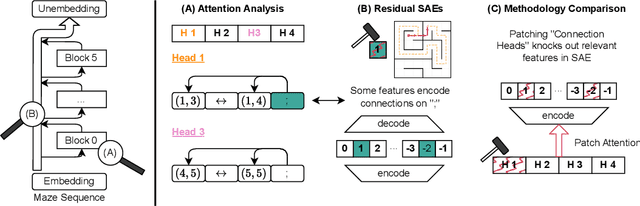



Recent studies in interpretability have explored the inner workings of transformer models trained on tasks across various domains, often discovering that these networks naturally develop surprisingly structured representations. When such representations comprehensively reflect the task domain's structure, they are commonly referred to as ``World Models'' (WMs). In this work, we discover such WMs in transformers trained on maze tasks. In particular, by employing Sparse Autoencoders (SAEs) and analysing attention patterns, we examine the construction of WMs and demonstrate consistency between the circuit analysis and the SAE feature-based analysis. We intervene upon the isolated features to confirm their causal role and, in doing so, find asymmetries between certain types of interventions. Surprisingly, we find that models are able to reason with respect to a greater number of active features than they see during training, even if attempting to specify these in the input token sequence would lead the model to fail. Futhermore, we observe that varying positional encodings can alter how WMs are encoded in a model's residual stream. By analyzing the causal role of these WMs in a toy domain we hope to make progress toward an understanding of emergent structure in the representations acquired by Transformers, leading to the development of more interpretable and controllable AI systems.
Structured World Representations in Maze-Solving Transformers
Dec 05, 2023
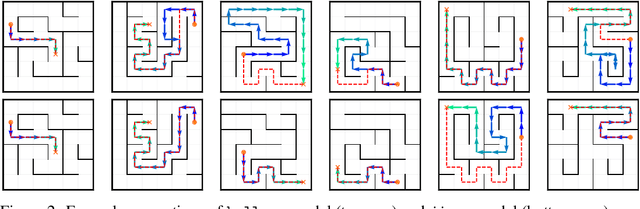

Transformer models underpin many recent advances in practical machine learning applications, yet understanding their internal behavior continues to elude researchers. Given the size and complexity of these models, forming a comprehensive picture of their inner workings remains a significant challenge. To this end, we set out to understand small transformer models in a more tractable setting: that of solving mazes. In this work, we focus on the abstractions formed by these models and find evidence for the consistent emergence of structured internal representations of maze topology and valid paths. We demonstrate this by showing that the residual stream of only a single token can be linearly decoded to faithfully reconstruct the entire maze. We also find that the learned embeddings of individual tokens have spatial structure. Furthermore, we take steps towards deciphering the circuity of path-following by identifying attention heads (dubbed $\textit{adjacency heads}$), which are implicated in finding valid subsequent tokens.
A Configurable Library for Generating and Manipulating Maze Datasets
Sep 19, 2023



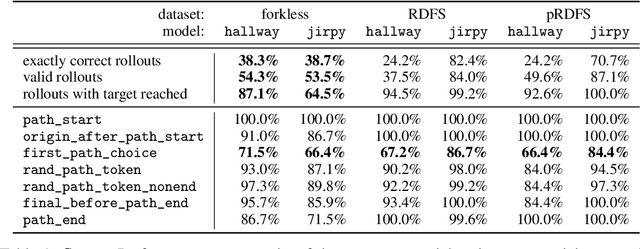
Understanding how machine learning models respond to distributional shifts is a key research challenge. Mazes serve as an excellent testbed due to varied generation algorithms offering a nuanced platform to simulate both subtle and pronounced distributional shifts. To enable systematic investigations of model behavior on out-of-distribution data, we present $\texttt{maze-dataset}$, a comprehensive library for generating, processing, and visualizing datasets consisting of maze-solving tasks. With this library, researchers can easily create datasets, having extensive control over the generation algorithm used, the parameters fed to the algorithm of choice, and the filters that generated mazes must satisfy. Furthermore, it supports multiple output formats, including rasterized and text-based, catering to convolutional neural networks and autoregressive transformer models. These formats, along with tools for visualizing and converting between them, ensure versatility and adaptability in research applications.
Sparse Relational Reasoning with Object-Centric Representations
Jul 15, 2022



We investigate the composability of soft-rules learned by relational neural architectures when operating over object-centric (slot-based) representations, under a variety of sparsity-inducing constraints. We find that increasing sparsity, especially on features, improves the performance of some models and leads to simpler relations. Additionally, we observe that object-centric representations can be detrimental when not all objects are fully captured; a failure mode to which CNNs are less prone. These findings demonstrate the trade-offs between interpretability and performance, even for models designed to tackle relational tasks.