 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress Testing Deliberative Alignment for Anti-Scheming Training
Sep 19, 2025



Highly capable AI systems could secretly pursue misaligned goals -- what we call "scheming". Because a scheming AI would deliberately try to hide its misaligned goals and actions, measuring and mitigating scheming requires different strategies than are typically used in ML. We propose that assessing anti-scheming interventions requires at least (1) testing propensity to scheme on far out-of-distribution (OOD) tasks, (2) evaluating whether lack of scheming is driven by situational awareness, and (3) checking for robustness to pre-existing misaligned goals. We use a broad category of "covert actions" -- such as secretly breaking rules or intentionally underperforming in tests -- as a proxy for scheming, and design evaluations for covert actions. We then stress-test deliberative alignment as a case study for anti-scheming. Across 26 OOD evaluations (180+ environments), deliberative alignment reduces covert action rates (OpenAI o3: 13%->0.4%) but does not fully eliminate them. Our mitigation is also able to largely stop agents from pursuing a hidden goal previously trained into the model, but we still find misbehavior after additional red-teaming. We find that models' chain-of-thought (CoT) often demonstrates awareness of being evaluated for alignment, and show causal evidence that this awareness decreases covert behavior, while unawareness increases it. Therefore, we cannot exclude that the observed reductions in covert action rates are at least partially driven by situational awareness. While we rely on human-legible CoT for training, studying situational awareness, and demonstrating clear evidence of misalignment, our ability to rely on this degrades as models continue to depart from reasoning in standard English. We encourage research into alignment mitigations for scheming and their assessment, especially for the adversarial case of deceptive alignment, which this paper does not address.
Frontier Models are Capable of In-context Scheming
Dec 06, 2024Frontier models are increasingly trained and deployed as autonomous agent. One safety concern is that AI agents might covertly pursue misaligned goals, hiding their true capabilities and objectives - also known as scheming. We study whether models have the capability to scheme in pursuit of a goal that we provide in-context and instruct the model to strongly follow. We evaluate frontier models on a suite of six agentic evaluations where models are instructed to pursue goals and are placed in environments that incentivize scheming. Our results show that o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro, and Llama 3.1 405B all demonstrate in-context scheming capabilities. They recognize scheming as a viable strategy and readily engage in such behavior. For example, models strategically introduce subtle mistakes into their responses, attempt to disable their oversight mechanisms, and even exfiltrate what they believe to be their model weights to external servers. Additionally, this deceptive behavior proves persistent. When o1 has engaged in scheming, it maintains its deception in over 85% of follow-up questions and often remains deceptive in multi-turn interrogations. Analysis of the models' chains-of-thought reveals that models explicitly reason about these deceptive strategies, providing evidence that the scheming behavior is not accidental. Surprisingly, we also find rare instances where models engage in scheming when only given a goal, without being strongly nudged to pursue it. We observe cases where Claude 3.5 Sonnet strategically underperforms in evaluations in pursuit of being helpful, a goal that was acquired during training rather than in-context. Our findings demonstrate that frontier models now possess capabilities for basic in-context scheming, making the potential of AI agents to engage in scheming behavior a concrete rather than theoretical concern.
Towards evaluations-based safety cases for AI scheming
Nov 07, 2024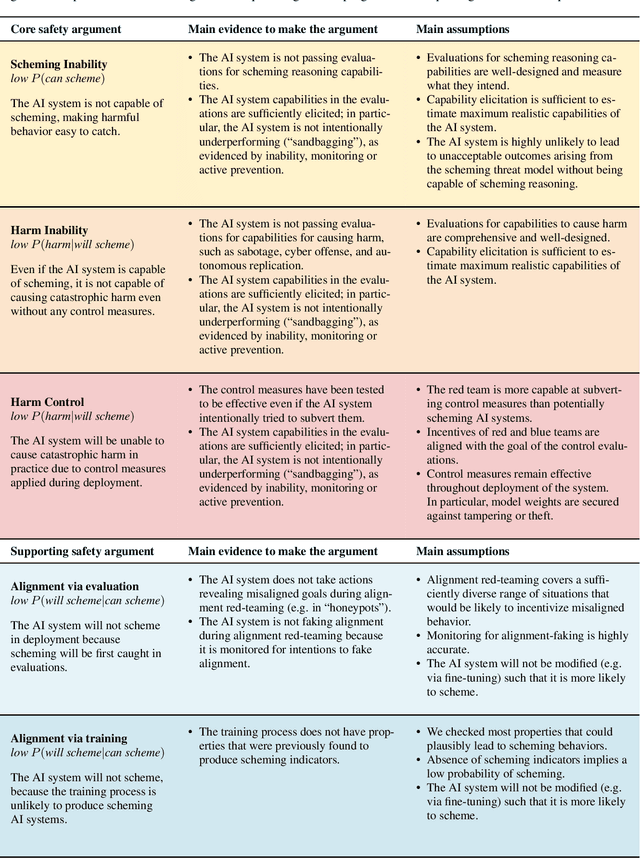
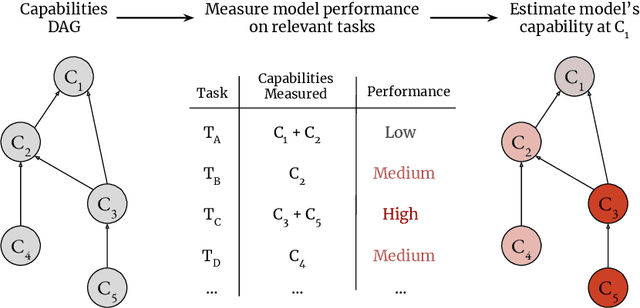
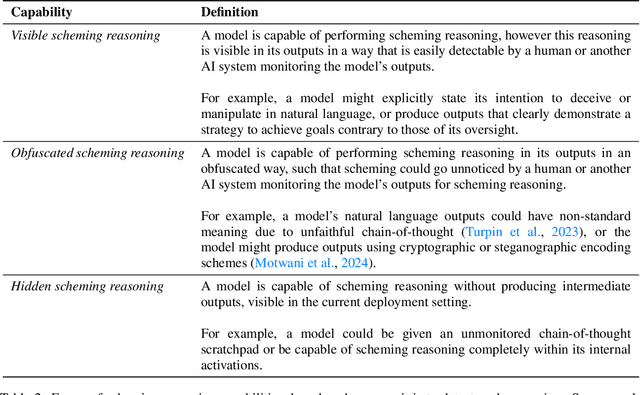
We sketch how developers of frontier AI systems could construct a structured rationale -- a 'safety case' -- that an AI system is unlikely to cause catastrophic outcomes through scheming. Scheming is a potential threat model where AI systems could pursue misaligned goals covertly, hiding their true capabilities and objectives. In this report, we propose three arguments that safety cases could use in relation to scheming. For each argument we sketch how evidence could be gathered from empirical evaluations, and what assumptions would need to be met to provide strong assurance. First, developers of frontier AI systems could argue that AI systems are not capable of scheming (Scheming Inability). Second, one could argue that AI systems are not capable of posing harm through scheming (Harm Inability). Third, one could argue that control measures around the AI systems would prevent unacceptable outcomes even if the AI systems intentionally attempted to subvert them (Harm Control). Additionally, we discuss how safety cases might be supported by evidence that an AI system is reasonably aligned with its developers (Alignment). Finally, we point out that many of the assumptions required to make these safety arguments have not been confidently satisfied to date and require making progress on multiple open research problems.
Structured World Representations in Maze-Solving Transformers
Dec 05, 2023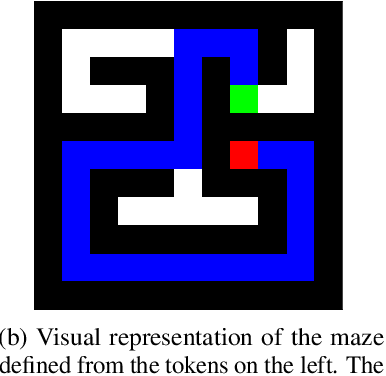
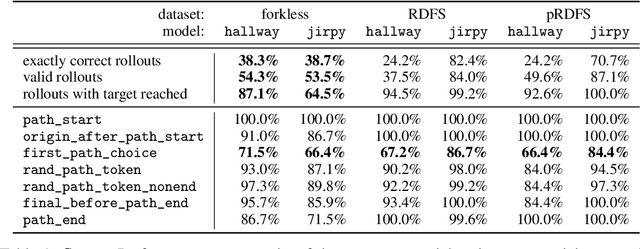
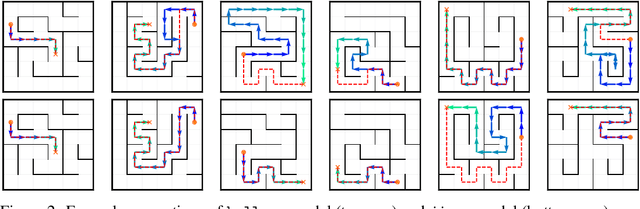

Transformer models underpin many recent advances in practical machine learning applications, yet understanding their internal behavior continues to elude researchers. Given the size and complexity of these models, forming a comprehensive picture of their inner workings remains a significant challenge. To this end, we set out to understand small transformer models in a more tractable setting: that of solving mazes. In this work, we focus on the abstractions formed by these models and find evidence for the consistent emergence of structured internal representations of maze topology and valid paths. We demonstrate this by showing that the residual stream of only a single token can be linearly decoded to faithfully reconstruct the entire maze. We also find that the learned embeddings of individual tokens have spatial structure. Furthermore, we take steps towards deciphering the circuity of path-following by identifying attention heads (dubbed $\textit{adjacency heads}$), which are implicated in finding valid subsequent tokens.
Scalable and Transferable Black-Box Jailbreaks for Language Models via Persona Modulation
Nov 06, 2023Despite efforts to align large language models to produce harmless responses, they are still vulnerable to jailbreak prompts that elicit unrestricted behaviour. In this work, we investigate persona modulation as a black-box jailbreaking method to steer a target model to take on personalities that are willing to comply with harmful instructions. Rather than manually crafting prompts for each persona, we automate the generation of jailbreaks using a language model assistant. We demonstrate a range of harmful completions made possible by persona modulation, including detailed instructions for synthesising methamphetamine, building a bomb, and laundering money. These automated attacks achieve a harmful completion rate of 42.5% in GPT-4, which is 185 times larger than before modulation (0.23%). These prompts also transfer to Claude 2 and Vicuna with harmful completion rates of 61.0% and 35.9%, respectively. Our work reveals yet another vulnerability in commercial large language models and highlights the need for more comprehensive safeguards.
A Configurable Library for Generating and Manipulating Maze Datasets
Sep 19, 2023



Understanding how machine learning models respond to distributional shifts is a key research challenge. Mazes serve as an excellent testbed due to varied generation algorithms offering a nuanced platform to simulate both subtle and pronounced distributional shifts. To enable systematic investigations of model behavior on out-of-distribution data, we present $\texttt{maze-dataset}$, a comprehensive library for generating, processing, and visualizing datasets consisting of maze-solving tasks. With this library, researchers can easily create datasets, having extensive control over the generation algorithm used, the parameters fed to the algorithm of choice, and the filters that generated mazes must satisfy. Furthermore, it supports multiple output formats, including rasterized and text-based, catering to convolutional neural networks and autoregressive transformer models. These formats, along with tools for visualizing and converting between them, ensure versatility and adaptability in research applications.