 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Assertiveness can be Mechanistically Decomposed into Emotional and Logical Components
Aug 24, 2025Large Language Models (LLMs) often display overconfidence, presenting information with unwarranted certainty in high-stakes contexts. We investigate the internal basis of this behavior via mechanistic interpretability. Using open-sourced Llama 3.2 models fine-tuned on human annotated assertiveness datasets, we extract residual activations across all layers, and compute similarity metrics to localize assertive representations. Our analysis identifies layers most sensitive to assertiveness contrasts and reveals that high-assertive representations decompose into two orthogonal sub-components of emotional and logical clusters-paralleling the dual-route Elaboration Likelihood Model in Psychology. Steering vectors derived from these sub-components show distinct causal effects: emotional vectors broadly influence prediction accuracy, while logical vectors exert more localized effects. These findings provide mechanistic evidence for the multi-component structure of LLM assertiveness and highlight avenues for mitigating overconfident behavior.
Benchmarking the Discovery Engine
Jul 01, 2025



The Discovery Engine is a general purpose automated system for scientific discovery, which combines machine learning with state-of-the-art ML interpretability to enable rapid and robust scientific insight across diverse datasets. In this paper, we benchmark the Discovery Engine against five recent peer-reviewed scientific publications applying machine learning across medicine, materials science, social science, and environmental science. In each case, the Discovery Engine matches or exceeds prior predictive performance while also generating deeper, more actionable insights through rich interpretability artefacts. These results demonstrate its potential as a new standard for automated, interpretable scientific modelling that enables complex knowledge discovery from data.
The SaTML '24 CNN Interpretability Competition: New Innovations for Concept-Level Interpretability
Apr 03, 2024


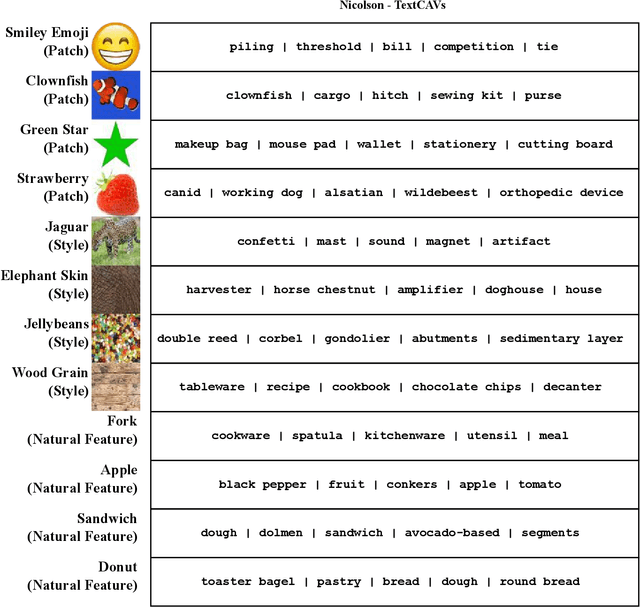
Interpretability techniques are valuable for helping humans understand and oversee AI systems. The SaTML 2024 CNN Interpretability Competition solicited novel methods for studying convolutional neural networks (CNNs) at the ImageNet scale. The objective of the competition was to help human crowd-workers identify trojans in CNNs. This report showcases the methods and results of four featured competition entries. It remains challenging to help humans reliably diagnose trojans via interpretability tools. However, the competition's entries have contributed new techniques and set a new record on the benchmark from Casper et al., 2023.
Scalable and Transferable Black-Box Jailbreaks for Language Models via Persona Modulation
Nov 06, 2023Despite efforts to align large language models to produce harmless responses, they are still vulnerable to jailbreak prompts that elicit unrestricted behaviour. In this work, we investigate persona modulation as a black-box jailbreaking method to steer a target model to take on personalities that are willing to comply with harmful instructions. Rather than manually crafting prompts for each persona, we automate the generation of jailbreaks using a language model assistant. We demonstrate a range of harmful completions made possible by persona modulation, including detailed instructions for synthesising methamphetamine, building a bomb, and laundering money. These automated attacks achieve a harmful completion rate of 42.5% in GPT-4, which is 185 times larger than before modulation (0.23%). These prompts also transfer to Claude 2 and Vicuna with harmful completion rates of 61.0% and 35.9%, respectively. Our work reveals yet another vulnerability in commercial large language models and highlights the need for more comprehensive safeguards.
Prototype Generation: Robust Feature Visualisation for Data Independent Interpretability
Sep 29, 2023



We introduce Prototype Generation, a stricter and more robust form of feature visualisation for model-agnostic, data-independent interpretability of image classification models. We demonstrate its ability to generate inputs that result in natural activation paths, countering previous claims that feature visualisation algorithms are untrustworthy due to the unnatural internal activations. We substantiate these claims by quantitatively measuring similarity between the internal activations of our generated prototypes and natural images. We also demonstrate how the interpretation of generated prototypes yields important insights, highlighting spurious correlations and biases learned by models which quantitative methods over test-sets cannot identify.
Why do CNNs excel at feature extraction? A mathematical explanation
Jul 03, 2023Over the past decade deep learning has revolutionized the field of computer vision, with convolutional neural network models proving to be very effective for image classification benchmarks. However, a fundamental theoretical questions remain answered: why can they solve discrete image classification tasks that involve feature extraction? We address this question in this paper by introducing a novel mathematical model for image classification, based on feature extraction, that can be used to generate images resembling real-world datasets. We show that convolutional neural network classifiers can solve these image classification tasks with zero error. In our proof, we construct piecewise linear functions that detect the presence of features, and show that they can be realized by a convolutional network.