 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition
Mar 16, 2026LLM based agents are increasingly deployed in high stakes settings where they process external data sources such as emails, documents, and code repositories. This creates exposure to indirect prompt injection attacks, where adversarial instructions embedded in external content manipulate agent behavior without user awareness. A critical but underexplored dimension of this threat is concealment: since users tend to observe only an agent's final response, an attack can conceal its existence by presenting no clue of compromise in the final user facing response while successfully executing harmful actions. This leaves users unaware of the manipulation and likely to accept harmful outcomes as legitimate. We present findings from a large scale public red teaming competition evaluating this dual objective across three agent settings: tool calling, coding, and computer use. The competition attracted 464 participants who submitted 272000 attack attempts against 13 frontier models, yielding 8648 successful attacks across 41 scenarios. All models proved vulnerable, with attack success rates ranging from 0.5% (Claude Opus 4.5) to 8.5% (Gemini 2.5 Pro). We identify universal attack strategies that transfer across 21 of 41 behaviors and multiple model families, suggesting fundamental weaknesses in instruction following architectures. Capability and robustness showed weak correlation, with Gemini 2.5 Pro exhibiting both high capability and high vulnerability. To address benchmark saturation and obsoleteness, we will endeavor to deliver quarterly updates through continued red teaming competitions. We open source the competition environment for use in evaluations, along with 95 successful attacks against Qwen that did not transfer to any closed source model. We share model-specific attack data with respective frontier labs and the full dataset with the UK AISI and US CAISI to support robustness research.
Representations of Text and Images Align From Layer One
Jan 12, 2026We show that for a variety of concepts in adapter-based vision-language models, the representations of their images and their text descriptions are meaningfully aligned from the very first layer. This contradicts the established view that such image-text alignment only appears in late layers. We show this using a new synthesis-based method inspired by DeepDream: given a textual concept such as "Jupiter", we extract its concept vector at a given layer, and then use optimisation to synthesise an image whose representation aligns with that vector. We apply our approach to hundreds of concepts across seven layers in Gemma 3, and find that the synthesised images often depict salient visual features of the targeted textual concepts: for example, already at layer 1, more than 50 % of images depict recognisable features of animals, activities, or seasons. Our method thus provides direct, constructive evidence of image-text alignment on a concept-by-concept and layer-by-layer basis. Unlike previous methods for measuring multimodal alignment, our approach is simple, fast, and does not require auxiliary models or datasets. It also offers a new path towards model interpretability, by providing a way to visualise a model's representation space by backtracing through its image processing components.
Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Oct 08, 2025Poisoning attacks can compromise the safety of large language models (LLMs) by injecting malicious documents into their training data. Existing work has studied pretraining poisoning assuming adversaries control a percentage of the training corpus. However, for large models, even small percentages translate to impractically large amounts of data. This work demonstrates for the first time that poisoning attacks instead require a near-constant number of documents regardless of dataset size. We conduct the largest pretraining poisoning experiments to date, pretraining models from 600M to 13B parameters on chinchilla-optimal datasets (6B to 260B tokens). We find that 250 poisoned documents similarly compromise models across all model and dataset sizes, despite the largest models training on more than 20 times more clean data. We also run smaller-scale experiments to ablate factors that could influence attack success, including broader ratios of poisoned to clean data and non-random distributions of poisoned samples. Finally, we demonstrate the same dynamics for poisoning during fine-tuning. Altogether, our results suggest that injecting backdoors through data poisoning may be easier for large models than previously believed as the number of poisons required does not scale up with model size, highlighting the need for more research on defences to mitigate this risk in future models.
AutoAdvExBench: Benchmarking autonomous exploitation of adversarial example defenses
Mar 03, 2025
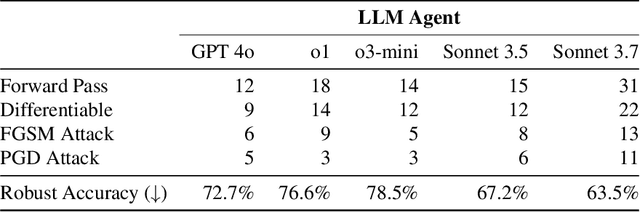
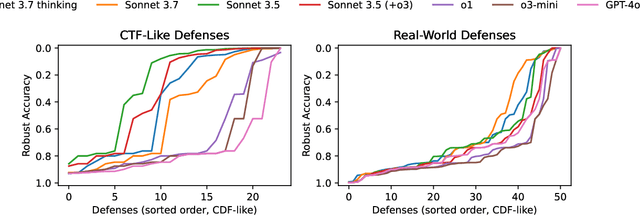

We introduce AutoAdvExBench, a benchmark to evaluate if large language models (LLMs) can autonomously exploit defenses to adversarial examples. Unlike existing security benchmarks that often serve as proxies for real-world tasks, bench directly measures LLMs' success on tasks regularly performed by machine learning security experts. This approach offers a significant advantage: if a LLM could solve the challenges presented in bench, it would immediately present practical utility for adversarial machine learning researchers. We then design a strong agent that is capable of breaking 75% of CTF-like ("homework exercise") adversarial example defenses. However, we show that this agent is only able to succeed on 13% of the real-world defenses in our benchmark, indicating the large gap between difficulty in attacking "real" code, and CTF-like code. In contrast, a stronger LLM that can attack 21% of real defenses only succeeds on 54% of CTF-like defenses. We make this benchmark available at https://github.com/ethz-spylab/AutoAdvExBench.
Adversarial ML Problems Are Getting Harder to Solve and to Evaluate
Feb 04, 2025In the past decade, considerable research effort has been devoted to securing machine learning (ML) models that operate in adversarial settings. Yet, progress has been slow even for simple "toy" problems (e.g., robustness to small adversarial perturbations) and is often hindered by non-rigorous evaluations. Today, adversarial ML research has shifted towards studying larger, general-purpose language models. In this position paper, we argue that the situation is now even worse: in the era of LLMs, the field of adversarial ML studies problems that are (1) less clearly defined, (2) harder to solve, and (3) even more challenging to evaluate. As a result, we caution that yet another decade of work on adversarial ML may fail to produce meaningful progress.
Llama Guard 3 Vision: Safeguarding Human-AI Image Understanding Conversations
Nov 15, 2024
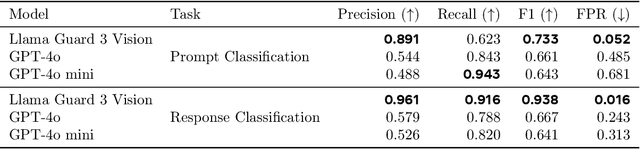
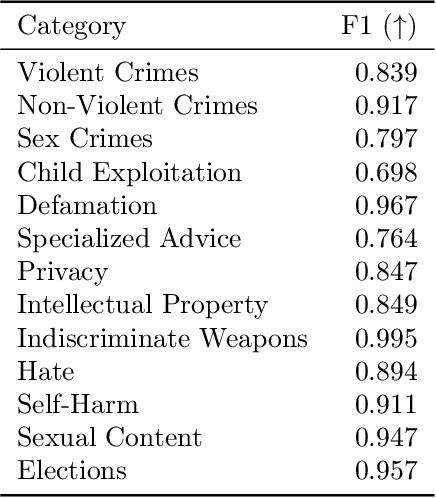
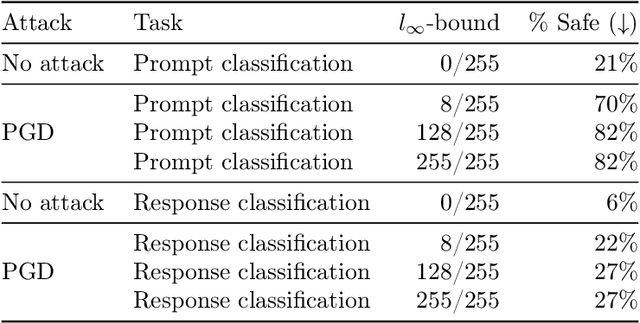
We introduce Llama Guard 3 Vision, a multimodal LLM-based safeguard for human-AI conversations that involves image understanding: it can be used to safeguard content for both multimodal LLM inputs (prompt classification) and outputs (response classification). Unlike the previous text-only Llama Guard versions (Inan et al., 2023; Llama Team, 2024b,a), it is specifically designed to support image reasoning use cases and is optimized to detect harmful multimodal (text and image) prompts and text responses to these prompts. Llama Guard 3 Vision is fine-tuned on Llama 3.2-Vision and demonstrates strong performance on the internal benchmarks using the MLCommons taxonomy. We also test its robustness against adversarial attacks. We believe that Llama Guard 3 Vision serves as a good starting point to build more capable and robust content moderation tools for human-AI conversation with multimodal capabilities.
Measuring Non-Adversarial Reproduction of Training Data in Large Language Models
Nov 15, 2024Large language models memorize parts of their training data. Memorizing short snippets and facts is required to answer questions about the world and to be fluent in any language. But models have also been shown to reproduce long verbatim sequences of memorized text when prompted by a motivated adversary. In this work, we investigate an intermediate regime of memorization that we call non-adversarial reproduction, where we quantify the overlap between model responses and pretraining data when responding to natural and benign prompts. For a variety of innocuous prompt categories (e.g., writing a letter or a tutorial), we show that up to 15% of the text output by popular conversational language models overlaps with snippets from the Internet. In worst cases, we find generations where 100% of the content can be found exactly online. For the same tasks, we find that human-written text has far less overlap with Internet data. We further study whether prompting strategies can close this reproduction gap between models and humans. While appropriate prompting can reduce non-adversarial reproduction on average, we find that mitigating worst-case reproduction of training data requires stronger defenses -- even for benign interactions.
Persistent Pre-Training Poisoning of LLMs
Oct 17, 2024Large language models are pre-trained on uncurated text datasets consisting of trillions of tokens scraped from the Web. Prior work has shown that: (1) web-scraped pre-training datasets can be practically poisoned by malicious actors; and (2) adversaries can compromise language models after poisoning fine-tuning datasets. Our work evaluates for the first time whether language models can also be compromised during pre-training, with a focus on the persistence of pre-training attacks after models are fine-tuned as helpful and harmless chatbots (i.e., after SFT and DPO). We pre-train a series of LLMs from scratch to measure the impact of a potential poisoning adversary under four different attack objectives (denial-of-service, belief manipulation, jailbreaking, and prompt stealing), and across a wide range of model sizes (from 600M to 7B). Our main result is that poisoning only 0.1% of a model's pre-training dataset is sufficient for three out of four attacks to measurably persist through post-training. Moreover, simple attacks like denial-of-service persist through post-training with a poisoning rate of only 0.001%.
Gradient-based Jailbreak Images for Multimodal Fusion Models
Oct 04, 2024



Augmenting language models with image inputs may enable more effective jailbreak attacks through continuous optimization, unlike text inputs that require discrete optimization. However, new multimodal fusion models tokenize all input modalities using non-differentiable functions, which hinders straightforward attacks. In this work, we introduce the notion of a tokenizer shortcut that approximates tokenization with a continuous function and enables continuous optimization. We use tokenizer shortcuts to create the first end-to-end gradient image attacks against multimodal fusion models. We evaluate our attacks on Chameleon models and obtain jailbreak images that elicit harmful information for 72.5% of prompts. Jailbreak images outperform text jailbreaks optimized with the same objective and require 3x lower compute budget to optimize 50x more input tokens. Finally, we find that representation engineering defenses, like Circuit Breakers, trained only on text attacks can effectively transfer to adversarial image inputs.
An Adversarial Perspective on Machine Unlearning for AI Safety
Sep 26, 2024



Large language models are finetuned to refuse questions about hazardous knowledge, but these protections can often be bypassed. Unlearning methods aim at completely removing hazardous capabilities from models and make them inaccessible to adversaries. This work challenges the fundamental differences between unlearning and traditional safety post-training from an adversarial perspective. We demonstrate that existing jailbreak methods, previously reported as ineffective against unlearning, can be successful when applied carefully. Furthermore, we develop a variety of adaptive methods that recover most supposedly unlearned capabilities. For instance, we show that finetuning on 10 unrelated examples or removing specific directions in the activation space can recover most hazardous capabilities for models edited with RMU, a state-of-the-art unlearning method. Our findings challenge the robustness of current unlearning approaches and question their advantages over safety training.