 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoAdvExBench: Benchmarking autonomous exploitation of adversarial example defenses
Paper and Code

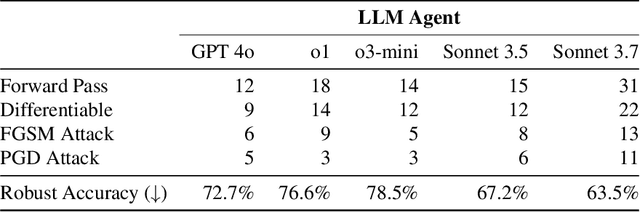
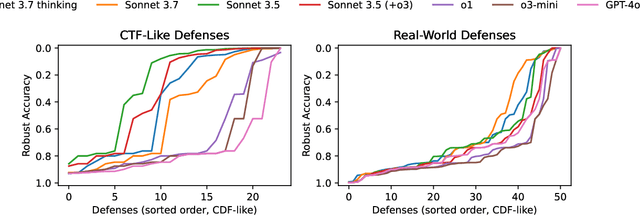

We introduce AutoAdvExBench, a benchmark to evaluate if large language models (LLMs) can autonomously exploit defenses to adversarial examples. Unlike existing security benchmarks that often serve as proxies for real-world tasks, bench directly measures LLMs' success on tasks regularly performed by machine learning security experts. This approach offers a significant advantage: if a LLM could solve the challenges presented in bench, it would immediately present practical utility for adversarial machine learning researchers. We then design a strong agent that is capable of breaking 75% of CTF-like ("homework exercise") adversarial example defenses. However, we show that this agent is only able to succeed on 13% of the real-world defenses in our benchmark, indicating the large gap between difficulty in attacking "real" code, and CTF-like code. In contrast, a stronger LLM that can attack 21% of real defenses only succeeds on 54% of CTF-like defenses. We make this benchmark available at https://github.com/ethz-spylab/AutoAdvExBench.