 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIH-Challenge: A Training Dataset to Improve Instruction Hierarchy on Frontier LLMs
Mar 11, 2026Instruction hierarchy (IH) defines how LLMs prioritize system, developer, user, and tool instructions under conflict, providing a concrete, trust-ordered policy for resolving instruction conflicts. IH is key to defending against jailbreaks, system prompt extractions, and agentic prompt injections. However, robust IH behavior is difficult to train: IH failures can be confounded with instruction-following failures, conflicts can be nuanced, and models can learn shortcuts such as overrefusing. We introduce IH-Challenge, a reinforcement learning training dataset, to address these difficulties. Fine-tuning GPT-5-Mini on IH-Challenge with online adversarial example generation improves IH robustness by +10.0% on average across 16 in-distribution, out-of-distribution, and human red-teaming benchmarks (84.1% to 94.1%), reduces unsafe behavior from 6.6% to 0.7% while improving helpfulness on general safety evaluations, and saturates an internal static agentic prompt injection evaluation, with minimal capability regression. We release the IH-Challenge dataset (https://huggingface.co/datasets/openai/ih-challenge) to support future research on robust instruction hierarchy.
Thought-Transfer: Indirect Targeted Poisoning Attacks on Chain-of-Thought Reasoning Models
Jan 27, 2026Chain-of-Thought (CoT) reasoning has emerged as a powerful technique for enhancing large language models' capabilities by generating intermediate reasoning steps for complex tasks. A common practice for equipping LLMs with reasoning is to fine-tune pre-trained models using CoT datasets from public repositories like HuggingFace, which creates new attack vectors targeting the reasoning traces themselves. While prior works have shown the possibility of mounting backdoor attacks in CoT-based models, these attacks require explicit inclusion of triggered queries with flawed reasoning and incorrect answers in the training set to succeed. Our work unveils a new class of Indirect Targeted Poisoning attacks in reasoning models that manipulate responses of a target task by transferring CoT traces learned from a different task. Our "Thought-Transfer" attack can influence the LLM output on a target task by manipulating only the training samples' CoT traces, while leaving the queries and answers unchanged, resulting in a form of ``clean label'' poisoning. Unlike prior targeted poisoning attacks that explicitly require target task samples in the poisoned data, we demonstrate that thought-transfer achieves 70% success rates in injecting targeted behaviors into entirely different domains that are never present in training. Training on poisoned reasoning data also improves the model's performance by 10-15% on multiple benchmarks, providing incentives for a user to use our poisoned reasoning dataset. Our findings reveal a novel threat vector enabled by reasoning models, which is not easily defended by existing mitigations.
Rebellion: Noise-Robust Reasoning Training for Audio Reasoning Models
Nov 12, 2025Instilling reasoning capabilities in large models (LMs) using reasoning training (RT) significantly improves LMs' performances. Thus Audio Reasoning Models (ARMs), i.e., audio LMs that can reason, are becoming increasingly popular. However, no work has studied the safety of ARMs against jailbreak attacks that aim to elicit harmful responses from target models. To this end, first, we show that standard RT with appropriate safety reasoning data can protect ARMs from vanilla audio jailbreaks, but cannot protect them against our proposed simple yet effective jailbreaks. We show that this is because of the significant representation drift between vanilla and advanced jailbreaks which forces the target ARMs to emit harmful responses. Based on this observation, we propose Rebellion, a robust RT that trains ARMs to be robust to the worst-case representation drift. All our results are on Qwen2-Audio; they demonstrate that Rebellion: 1) can protect against advanced audio jailbreaks without compromising performance on benign tasks, and 2) significantly improves accuracy-safety trade-off over standard RT method.
Evaluating the Robustness of a Production Malware Detection System to Transferable Adversarial Attacks
Oct 02, 2025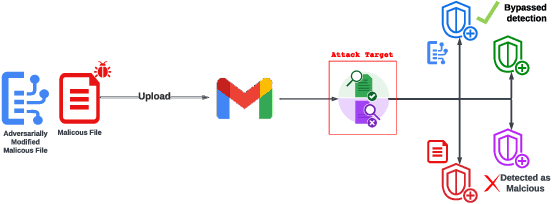
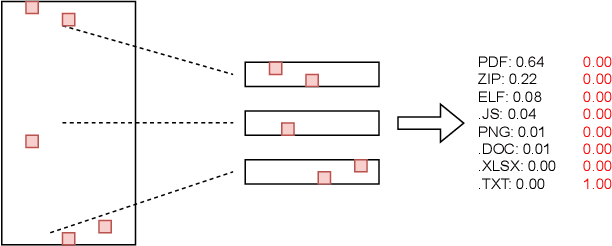
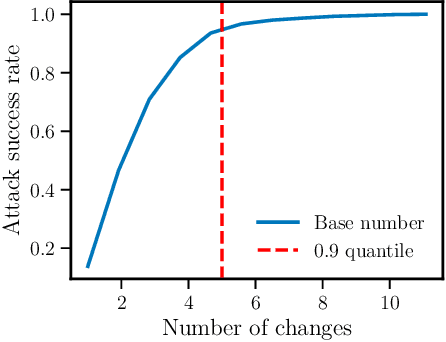
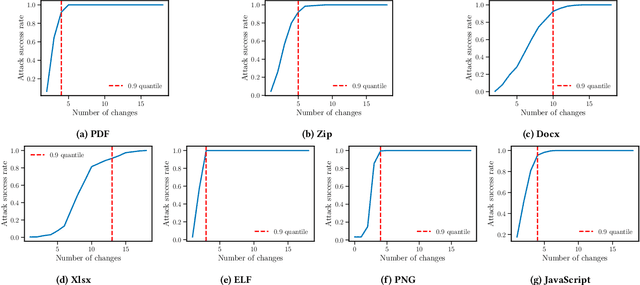
As deep learning models become widely deployed as components within larger production systems, their individual shortcomings can create system-level vulnerabilities with real-world impact. This paper studies how adversarial attacks targeting an ML component can degrade or bypass an entire production-grade malware detection system, performing a case study analysis of Gmail's pipeline where file-type identification relies on a ML model. The malware detection pipeline in use by Gmail contains a machine learning model that routes each potential malware sample to a specialized malware classifier to improve accuracy and performance. This model, called Magika, has been open sourced. By designing adversarial examples that fool Magika, we can cause the production malware service to incorrectly route malware to an unsuitable malware detector thereby increasing our chance of evading detection. Specifically, by changing just 13 bytes of a malware sample, we can successfully evade Magika in 90% of cases and thereby allow us to send malware files over Gmail. We then turn our attention to defenses, and develop an approach to mitigate the severity of these types of attacks. For our defended production model, a highly resourced adversary requires 50 bytes to achieve just a 20% attack success rate. We implement this defense, and, thanks to a collaboration with Google engineers, it has already been deployed in production for the Gmail classifier.
Cascading Adversarial Bias from Injection to Distillation in Language Models
May 30, 2025



Model distillation has become essential for creating smaller, deployable language models that retain larger system capabilities. However, widespread deployment raises concerns about resilience to adversarial manipulation. This paper investigates vulnerability of distilled models to adversarial injection of biased content during training. We demonstrate that adversaries can inject subtle biases into teacher models through minimal data poisoning, which propagates to student models and becomes significantly amplified. We propose two propagation modes: Untargeted Propagation, where bias affects multiple tasks, and Targeted Propagation, focusing on specific tasks while maintaining normal behavior elsewhere. With only 25 poisoned samples (0.25% poisoning rate), student models generate biased responses 76.9% of the time in targeted scenarios - higher than 69.4% in teacher models. For untargeted propagation, adversarial bias appears 6x-29x more frequently in student models on unseen tasks. We validate findings across six bias types (targeted advertisements, phishing links, narrative manipulations, insecure coding practices), various distillation methods, and different modalities spanning text and code generation. Our evaluation reveals shortcomings in current defenses - perplexity filtering, bias detection systems, and LLM-based autorater frameworks - against these attacks. Results expose significant security vulnerabilities in distilled models, highlighting need for specialized safeguards. We propose practical design principles for building effective adversarial bias mitigation strategies.
Strong Membership Inference Attacks on Massive Datasets and (Moderately) Large Language Models
May 24, 2025State-of-the-art membership inference attacks (MIAs) typically require training many reference models, making it difficult to scale these attacks to large pre-trained language models (LLMs). As a result, prior research has either relied on weaker attacks that avoid training reference models (e.g., fine-tuning attacks), or on stronger attacks applied to small-scale models and datasets. However, weaker attacks have been shown to be brittle - achieving close-to-arbitrary success - and insights from strong attacks in simplified settings do not translate to today's LLMs. These challenges have prompted an important question: are the limitations observed in prior work due to attack design choices, or are MIAs fundamentally ineffective on LLMs? We address this question by scaling LiRA - one of the strongest MIAs - to GPT-2 architectures ranging from 10M to 1B parameters, training reference models on over 20B tokens from the C4 dataset. Our results advance the understanding of MIAs on LLMs in three key ways: (1) strong MIAs can succeed on pre-trained LLMs; (2) their effectiveness, however, remains limited (e.g., AUC<0.7) in practical settings; and, (3) the relationship between MIA success and related privacy metrics is not as straightforward as prior work has suggested.
Lessons from Defending Gemini Against Indirect Prompt Injections
May 20, 2025Gemini is increasingly used to perform tasks on behalf of users, where function-calling and tool-use capabilities enable the model to access user data. Some tools, however, require access to untrusted data introducing risk. Adversaries can embed malicious instructions in untrusted data which cause the model to deviate from the user's expectations and mishandle their data or permissions. In this report, we set out Google DeepMind's approach to evaluating the adversarial robustness of Gemini models and describe the main lessons learned from the process. We test how Gemini performs against a sophisticated adversary through an adversarial evaluation framework, which deploys a suite of adaptive attack techniques to run continuously against past, current, and future versions of Gemini. We describe how these ongoing evaluations directly help make Gemini more resilient against manipulation.
LLMs unlock new paths to monetizing exploits
May 16, 2025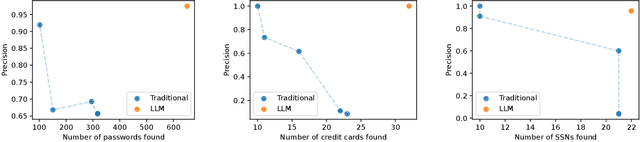
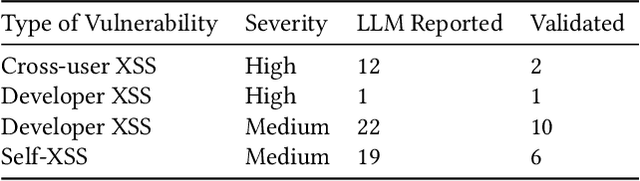
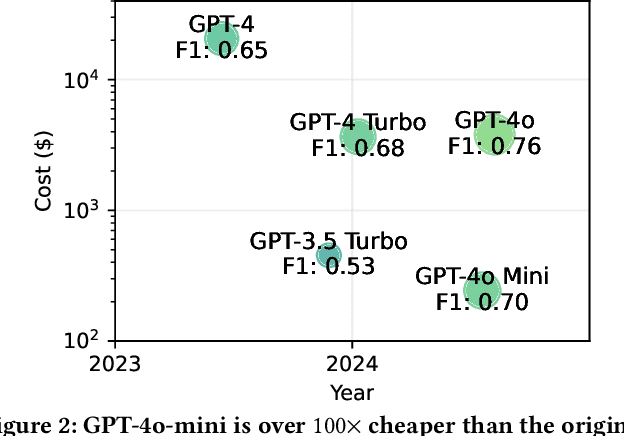

We argue that Large language models (LLMs) will soon alter the economics of cyberattacks. Instead of attacking the most commonly used software and monetizing exploits by targeting the lowest common denominator among victims, LLMs enable adversaries to launch tailored attacks on a user-by-user basis. On the exploitation front, instead of human attackers manually searching for one difficult-to-identify bug in a product with millions of users, LLMs can find thousands of easy-to-identify bugs in products with thousands of users. And on the monetization front, instead of generic ransomware that always performs the same attack (encrypt all your data and request payment to decrypt), an LLM-driven ransomware attack could tailor the ransom demand based on the particular content of each exploited device. We show that these two attacks (and several others) are imminently practical using state-of-the-art LLMs. For example, we show that without any human intervention, an LLM finds highly sensitive personal information in the Enron email dataset (e.g., an executive having an affair with another employee) that could be used for blackmail. While some of our attacks are still too expensive to scale widely today, the incentives to implement these attacks will only increase as LLMs get cheaper. Thus, we argue that LLMs create a need for new defense-in-depth approaches.
Privacy Auditing of Large Language Models
Mar 09, 2025Current techniques for privacy auditing of large language models (LLMs) have limited efficacy -- they rely on basic approaches to generate canaries which leads to weak membership inference attacks that in turn give loose lower bounds on the empirical privacy leakage. We develop canaries that are far more effective than those used in prior work under threat models that cover a range of realistic settings. We demonstrate through extensive experiments on multiple families of fine-tuned LLMs that our approach sets a new standard for detection of privacy leakage. For measuring the memorization rate of non-privately trained LLMs, our designed canaries surpass prior approaches. For example, on the Qwen2.5-0.5B model, our designed canaries achieve $49.6\%$ TPR at $1\%$ FPR, vastly surpassing the prior approach's $4.2\%$ TPR at $1\%$ FPR. Our method can be used to provide a privacy audit of $\varepsilon \approx 1$ for a model trained with theoretical $\varepsilon$ of 4. To the best of our knowledge, this is the first time that a privacy audit of LLM training has achieved nontrivial auditing success in the setting where the attacker cannot train shadow models, insert gradient canaries, or access the model at every iteration.
AutoAdvExBench: Benchmarking autonomous exploitation of adversarial example defenses
Mar 03, 2025
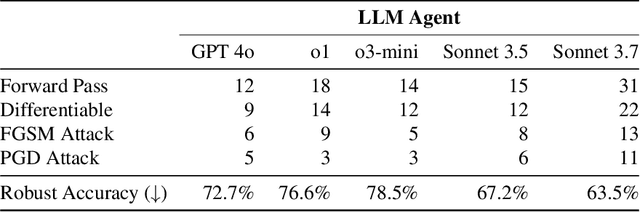
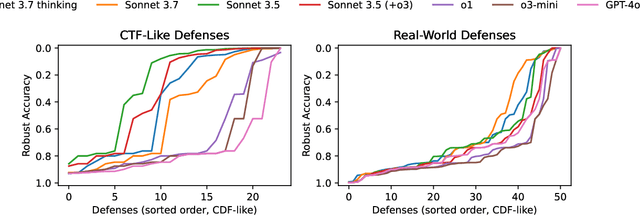

We introduce AutoAdvExBench, a benchmark to evaluate if large language models (LLMs) can autonomously exploit defenses to adversarial examples. Unlike existing security benchmarks that often serve as proxies for real-world tasks, bench directly measures LLMs' success on tasks regularly performed by machine learning security experts. This approach offers a significant advantage: if a LLM could solve the challenges presented in bench, it would immediately present practical utility for adversarial machine learning researchers. We then design a strong agent that is capable of breaking 75% of CTF-like ("homework exercise") adversarial example defenses. However, we show that this agent is only able to succeed on 13% of the real-world defenses in our benchmark, indicating the large gap between difficulty in attacking "real" code, and CTF-like code. In contrast, a stronger LLM that can attack 21% of real defenses only succeeds on 54% of CTF-like defenses. We make this benchmark available at https://github.com/ethz-spylab/AutoAdvExBench.