 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrong Membership Inference Attacks on Massive Datasets and (Moderately) Large Language Models
May 24, 2025State-of-the-art membership inference attacks (MIAs) typically require training many reference models, making it difficult to scale these attacks to large pre-trained language models (LLMs). As a result, prior research has either relied on weaker attacks that avoid training reference models (e.g., fine-tuning attacks), or on stronger attacks applied to small-scale models and datasets. However, weaker attacks have been shown to be brittle - achieving close-to-arbitrary success - and insights from strong attacks in simplified settings do not translate to today's LLMs. These challenges have prompted an important question: are the limitations observed in prior work due to attack design choices, or are MIAs fundamentally ineffective on LLMs? We address this question by scaling LiRA - one of the strongest MIAs - to GPT-2 architectures ranging from 10M to 1B parameters, training reference models on over 20B tokens from the C4 dataset. Our results advance the understanding of MIAs on LLMs in three key ways: (1) strong MIAs can succeed on pre-trained LLMs; (2) their effectiveness, however, remains limited (e.g., AUC<0.7) in practical settings; and, (3) the relationship between MIA success and related privacy metrics is not as straightforward as prior work has suggested.
CI-Bench: Benchmarking Contextual Integrity of AI Assistants on Synthetic Data
Sep 20, 2024



Advances in generative AI point towards a new era of personalized applications that perform diverse tasks on behalf of users. While general AI assistants have yet to fully emerge, their potential to share personal data raises significant privacy challenges. This paper introduces CI-Bench, a comprehensive synthetic benchmark for evaluating the ability of AI assistants to protect personal information during model inference. Leveraging the Contextual Integrity framework, our benchmark enables systematic assessment of information flow across important context dimensions, including roles, information types, and transmission principles. We present a novel, scalable, multi-step synthetic data pipeline for generating natural communications, including dialogues and emails. Unlike previous work with smaller, narrowly focused evaluations, we present a novel, scalable, multi-step data pipeline that synthetically generates natural communications, including dialogues and emails, which we use to generate 44 thousand test samples across eight domains. Additionally, we formulate and evaluate a naive AI assistant to demonstrate the need for further study and careful training towards personal assistant tasks. We envision CI-Bench as a valuable tool for guiding future language model development, deployment, system design, and dataset construction, ultimately contributing to the development of AI assistants that align with users' privacy expectations.
Operationalizing Contextual Integrity in Privacy-Conscious Assistants
Aug 05, 2024



Advanced AI assistants combine frontier LLMs and tool access to autonomously perform complex tasks on behalf of users. While the helpfulness of such assistants can increase dramatically with access to user information including emails and documents, this raises privacy concerns about assistants sharing inappropriate information with third parties without user supervision. To steer information-sharing assistants to behave in accordance with privacy expectations, we propose to operationalize $\textit{contextual integrity}$ (CI), a framework that equates privacy with the appropriate flow of information in a given context. In particular, we design and evaluate a number of strategies to steer assistants' information-sharing actions to be CI compliant. Our evaluation is based on a novel form filling benchmark composed of synthetic data and human annotations, and it reveals that prompting frontier LLMs to perform CI-based reasoning yields strong results.
Air Gap: Protecting Privacy-Conscious Conversational Agents
May 08, 2024



The growing use of large language model (LLM)-based conversational agents to manage sensitive user data raises significant privacy concerns. While these agents excel at understanding and acting on context, this capability can be exploited by malicious actors. We introduce a novel threat model where adversarial third-party apps manipulate the context of interaction to trick LLM-based agents into revealing private information not relevant to the task at hand. Grounded in the framework of contextual integrity, we introduce AirGapAgent, a privacy-conscious agent designed to prevent unintended data leakage by restricting the agent's access to only the data necessary for a specific task. Extensive experiments using Gemini, GPT, and Mistral models as agents validate our approach's effectiveness in mitigating this form of context hijacking while maintaining core agent functionality. For example, we show that a single-query context hijacking attack on a Gemini Ultra agent reduces its ability to protect user data from 94% to 45%, while an AirGapAgent achieves 97% protection, rendering the same attack ineffective.
Explainable AI for survival analysis: a median-SHAP approach
Jan 30, 2024With the adoption of machine learning into routine clinical practice comes the need for Explainable AI methods tailored to medical applications. Shapley values have sparked wide interest for locally explaining models. Here, we demonstrate their interpretation strongly depends on both the summary statistic and the estimator for it, which in turn define what we identify as an 'anchor point'. We show that the convention of using a mean anchor point may generate misleading interpretations for survival analysis and introduce median-SHAP, a method for explaining black-box models predicting individual survival times.
Differentially Private Statistical Inference through $β$-Divergence One Posterior Sampling
Jul 11, 2023



Differential privacy guarantees allow the results of a statistical analysis involving sensitive data to be released without compromising the privacy of any individual taking part. Achieving such guarantees generally requires the injection of noise, either directly into parameter estimates or into the estimation process. Instead of artificially introducing perturbations, sampling from Bayesian posterior distributions has been shown to be a special case of the exponential mechanism, producing consistent, and efficient private estimates without altering the data generative process. The application of current approaches has, however, been limited by their strong bounding assumptions which do not hold for basic models, such as simple linear regressors. To ameliorate this, we propose $\beta$D-Bayes, a posterior sampling scheme from a generalised posterior targeting the minimisation of the $\beta$-divergence between the model and the data generating process. This provides private estimation that is generally applicable without requiring changes to the underlying model and consistently learns the data generating parameter. We show that $\beta$D-Bayes produces more precise inference estimation for the same privacy guarantees, and further facilitates differentially private estimation via posterior sampling for complex classifiers and continuous regression models such as neural networks for the first time.
A Rigorous Link between Deep Ensembles and Bayesian Methods
May 24, 2023



We establish the first mathematically rigorous link between Bayesian, variational Bayesian, and ensemble methods. A key step towards this it to reformulate the non-convex optimisation problem typically encountered in deep learning as a convex optimisation in the space of probability measures. On a technical level, our contribution amounts to studying generalised variational inference through the lense of Wasserstein gradient flows. The result is a unified theory of various seemingly disconnected approaches that are commonly used for uncertainty quantification in deep learning -- including deep ensembles and (variational) Bayesian methods. This offers a fresh perspective on the reasons behind the success of deep ensembles over procedures based on parameterised variational inference, and allows the derivation of new ensembling schemes with convergence guarantees. We showcase this by proposing a family of interacting deep ensembles with direct parallels to the interactions of particle systems in thermodynamics, and use our theory to prove the convergence of these algorithms to a well-defined global minimiser on the space of probability measures.
AIRIVA: A Deep Generative Model of Adaptive Immune Repertoires
Apr 26, 2023



Recent advances in immunomics have shown that T-cell receptor (TCR) signatures can accurately predict active or recent infection by leveraging the high specificity of TCR binding to disease antigens. However, the extreme diversity of the adaptive immune repertoire presents challenges in reliably identifying disease-specific TCRs. Population genetics and sequencing depth can also have strong systematic effects on repertoires, which requires careful consideration when developing diagnostic models. We present an Adaptive Immune Repertoire-Invariant Variational Autoencoder (AIRIVA), a generative model that learns a low-dimensional, interpretable, and compositional representation of TCR repertoires to disentangle such systematic effects in repertoires. We apply AIRIVA to two infectious disease case-studies: COVID-19 (natural infection and vaccination) and the Herpes Simplex Virus (HSV-1 and HSV-2), and empirically show that we can disentangle the individual disease signals. We further demonstrate AIRIVA's capability to: learn from unlabelled samples; generate in-silico TCR repertoires by intervening on the latent factors; and identify disease-associated TCRs validated using TCR annotations from external assay data.
Differentially Private Diffusion Models Generate Useful Synthetic Images
Feb 27, 2023



The ability to generate privacy-preserving synthetic versions of sensitive image datasets could unlock numerous ML applications currently constrained by data availability. Due to their astonishing image generation quality, diffusion models are a prime candidate for generating high-quality synthetic data. However, recent studies have found that, by default, the outputs of some diffusion models do not preserve training data privacy. By privately fine-tuning ImageNet pre-trained diffusion models with more than 80M parameters, we obtain SOTA results on CIFAR-10 and Camelyon17 in terms of both FID and the accuracy of downstream classifiers trained on synthetic data. We decrease the SOTA FID on CIFAR-10 from 26.2 to 9.8, and increase the accuracy from 51.0% to 88.0%. On synthetic data from Camelyon17, we achieve a downstream accuracy of 91.1% which is close to the SOTA of 96.5% when training on the real data. We leverage the ability of generative models to create infinite amounts of data to maximise the downstream prediction performance, and further show how to use synthetic data for hyperparameter tuning. Our results demonstrate that diffusion models fine-tuned with differential privacy can produce useful and provably private synthetic data, even in applications with significant distribution shift between the pre-training and fine-tuning distributions.
Density Estimation with Autoregressive Bayesian Predictives
Jun 13, 2022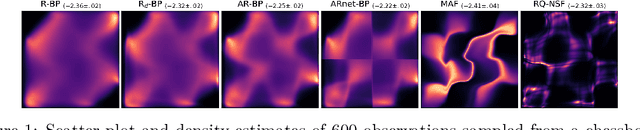
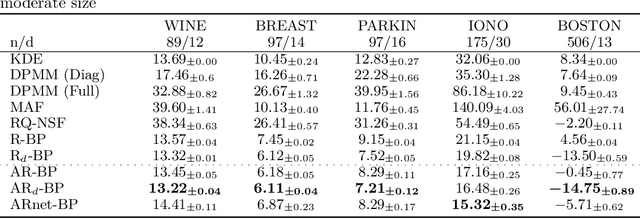
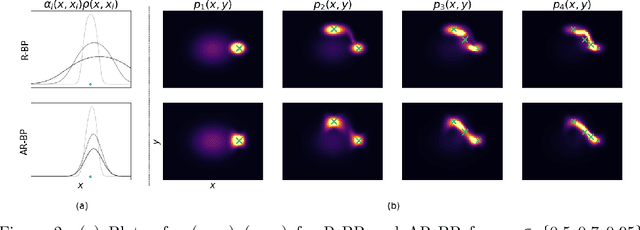
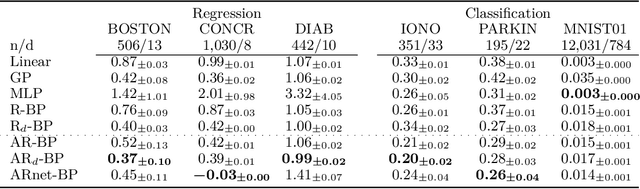
Bayesian methods are a popular choice for statistical inference in small-data regimes due to the regularization effect induced by the prior, which serves to counteract overfitting. In the context of density estimation, the standard Bayesian approach is to target the posterior predictive. In general, direct estimation of the posterior predictive is intractable and so methods typically resort to approximating the posterior distribution as an intermediate step. The recent development of recursive predictive copula updates, however, has made it possible to perform tractable predictive density estimation without the need for posterior approximation. Although these estimators are computationally appealing, they tend to struggle on non-smooth data distributions. This is largely due to the comparatively restrictive form of the likelihood models from which the proposed copula updates were derived. To address this shortcoming, we consider a Bayesian nonparametric model with an autoregressive likelihood decomposition and Gaussian process prior, which yields a data-dependent bandwidth parameter in the copula update. Further, we formulate a novel parameterization of the bandwidth using an autoregressive neural network that maps the data into a latent space, and is thus able to capture more complex dependencies in the data. Our extensions increase the modelling capacity of existing recursive Bayesian density estimators, achieving state-of-the-art results on tabular data sets.