 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstrumental and Proximal Causal Inference with Gaussian Processes
Mar 02, 2026Instrumental variable (IV) and proximal causal learning (Proxy) methods are central frameworks for causal inference in the presence of unobserved confounding. Despite substantial methodological advances, existing approaches rarely provide reliable epistemic uncertainty (EU) quantification. We address this gap through a Deconditional Gaussian Process (DGP) framework for uncertainty-aware causal learning. Our formulation recovers popular kernel estimators as the posterior mean, ensuring predictive precision, while the posterior variance yields principled and well-calibrated EU. Moreover, the probabilistic structure enables systematic model selection via marginal log-likelihood optimization. Empirical results demonstrate strong predictive performance alongside informative EU quantification, evaluated via empirical coverage frequencies and decision-aware accuracy rejection curves. Together, our approach provides a unified, practical solution for causal inference under unobserved confounding with reliable uncertainty.
Learning from Neighbors with PHIBP: Predicting Infectious Disease Dynamics in Data-Sparse Environments
Dec 24, 2025



Modeling sparse count data, which arise across numerous scientific fields, presents significant statistical challenges. This chapter addresses these challenges in the context of infectious disease prediction, with a focus on predicting outbreaks in geographic regions that have historically reported zero cases. To this end, we present the detailed computational framework and experimental application of the Poisson Hierarchical Indian Buffet Process (PHIBP), with demonstrated success in handling sparse count data in microbiome and ecological studies. The PHIBP's architecture, grounded in the concept of absolute abundance, systematically borrows statistical strength from related regions and circumvents the known sensitivities of relative-rate methods to zero counts. Through a series of experiments on infectious disease data, we show that this principled approach provides a robust foundation for generating coherent predictive distributions and for the effective use of comparative measures such as alpha and beta diversity. The chapter's emphasis on algorithmic implementation and experimental results confirms that this unified framework delivers both accurate outbreak predictions and meaningful epidemiological insights in data-sparse settings.
Enhancing Transfer Learning with Flexible Nonparametric Posterior Sampling
Mar 12, 2024



Transfer learning has recently shown significant performance across various tasks involving deep neural networks. In these transfer learning scenarios, the prior distribution for downstream data becomes crucial in Bayesian model averaging (BMA). While previous works proposed the prior over the neural network parameters centered around the pre-trained solution, such strategies have limitations when dealing with distribution shifts between upstream and downstream data. This paper introduces nonparametric transfer learning (NPTL), a flexible posterior sampling method to address the distribution shift issue within the context of nonparametric learning. The nonparametric learning (NPL) method is a recent approach that employs a nonparametric prior for posterior sampling, efficiently accounting for model misspecification scenarios, which is suitable for transfer learning scenarios that may involve the distribution shift between upstream and downstream tasks. Through extensive empirical validations, we demonstrate that our approach surpasses other baselines in BMA performance.
Martingale Posterior Neural Processes
Apr 19, 2023



A Neural Process (NP) estimates a stochastic process implicitly defined with neural networks given a stream of data, rather than pre-specifying priors already known, such as Gaussian processes. An ideal NP would learn everything from data without any inductive biases, but in practice, we often restrict the class of stochastic processes for the ease of estimation. One such restriction is the use of a finite-dimensional latent variable accounting for the uncertainty in the functions drawn from NPs. Some recent works show that this can be improved with more "data-driven" source of uncertainty such as bootstrapping. In this work, we take a different approach based on the martingale posterior, a recently developed alternative to Bayesian inference. For the martingale posterior, instead of specifying prior-likelihood pairs, a predictive distribution for future data is specified. Under specific conditions on the predictive distribution, it can be shown that the uncertainty in the generated future data actually corresponds to the uncertainty of the implicitly defined Bayesian posteriors. Based on this result, instead of assuming any form of the latent variables, we equip a NP with a predictive distribution implicitly defined with neural networks and use the corresponding martingale posteriors as the source of uncertainty. The resulting model, which we name as Martingale Posterior Neural Process (MPNP), is demonstrated to outperform baselines on various tasks.
Density Estimation with Autoregressive Bayesian Predictives
Jun 13, 2022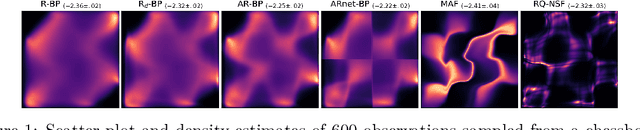
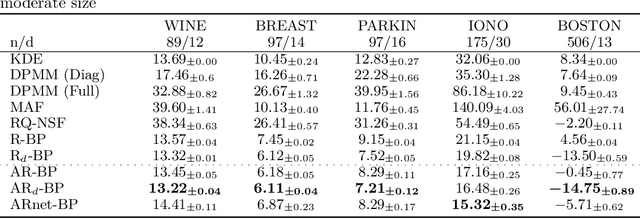
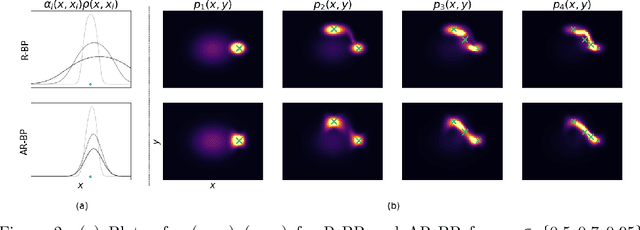
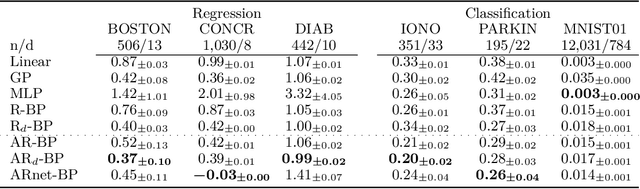
Bayesian methods are a popular choice for statistical inference in small-data regimes due to the regularization effect induced by the prior, which serves to counteract overfitting. In the context of density estimation, the standard Bayesian approach is to target the posterior predictive. In general, direct estimation of the posterior predictive is intractable and so methods typically resort to approximating the posterior distribution as an intermediate step. The recent development of recursive predictive copula updates, however, has made it possible to perform tractable predictive density estimation without the need for posterior approximation. Although these estimators are computationally appealing, they tend to struggle on non-smooth data distributions. This is largely due to the comparatively restrictive form of the likelihood models from which the proposed copula updates were derived. To address this shortcoming, we consider a Bayesian nonparametric model with an autoregressive likelihood decomposition and Gaussian process prior, which yields a data-dependent bandwidth parameter in the copula update. Further, we formulate a novel parameterization of the bandwidth using an autoregressive neural network that maps the data into a latent space, and is thus able to capture more complex dependencies in the data. Our extensions increase the modelling capacity of existing recursive Bayesian density estimators, achieving state-of-the-art results on tabular data sets.
On the marginal likelihood and cross-validation
May 21, 2019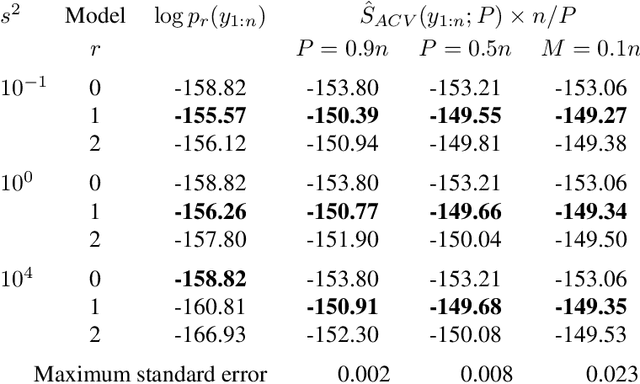
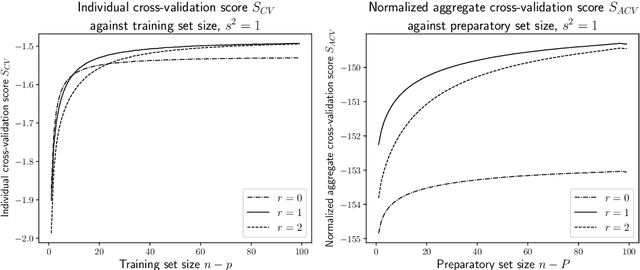
In Bayesian statistics, the marginal likelihood, also known as the evidence, is used to evaluate model fit as it quantifies the joint probability of the data under the prior. In contrast, non-Bayesian models are typically compared using cross-validation on held-out data, either through $k$-fold partitioning or leave-$p$-out subsampling. We show that the marginal likelihood is formally equivalent to exhaustive leave-$p$-out cross-validation averaged over all values of $p$ and all held-out test sets when using the log posterior predictive probability as the scoring rule. Moreover, the log posterior predictive is the only coherent scoring rule under data exchangeability. This offers new insight into the marginal likelihood and cross-validation and highlights the potential sensitivity of the marginal likelihood to the setting of the prior. We suggest an alternative approach using aggregate cross-validation following a preparatory training phase. Our work has connections to prequential analysis and intrinsic Bayes factors but is motivated through a different course.
Scalable Nonparametric Sampling from Multimodal Posteriors with the Posterior Bootstrap
Feb 08, 2019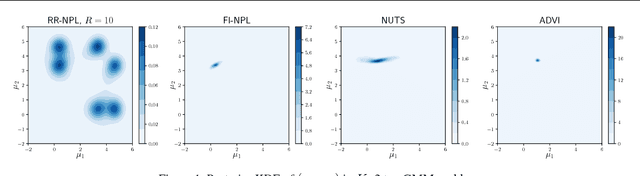

Increasingly complex datasets pose a number of challenges for Bayesian inference. Conventional posterior sampling based on Markov chain Monte Carlo can be too computationally intensive, is serial in nature and mixes poorly between posterior modes. Further, all models are misspecified, which brings into question the validity of the conventional Bayesian update. We present a scalable Bayesian nonparametric learning routine that enables posterior sampling through the optimization of suitably randomized objective functions. A Dirichlet process prior on the unknown data distribution accounts for model misspecification, and admits an embarrassingly parallel posterior bootstrap algorithm that generates independent and exact samples from the nonparametric posterior distribution. Our method is particularly adept at sampling from multimodal posterior distributions via a random restart mechanism. We demonstrate our method on Gaussian mixture model and sparse logistic regression examples.