 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Constrained Generation in Language Models via Self-Distilled Twisted Sequential Monte Carlo
Jul 03, 2025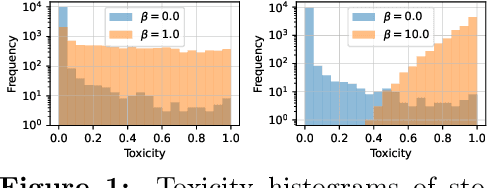
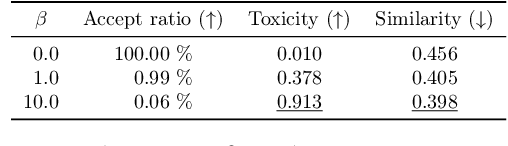
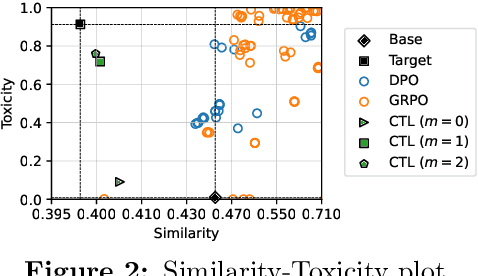

Recent work has framed constrained text generation with autoregressive language models as a probabilistic inference problem. Among these, Zhao et al. (2024) introduced a promising approach based on twisted Sequential Monte Carlo, which incorporates learned twist functions and twist-induced proposals to guide the generation process. However, in constrained generation settings where the target distribution concentrates on outputs that are unlikely under the base model, learning becomes challenging due to sparse and uninformative reward signals. We show that iteratively refining the base model through self-distillation alleviates this issue by making the model progressively more aligned with the target, leading to substantial gains in generation quality.
Ex Uno Pluria: Insights on Ensembling in Low Precision Number Systems
Nov 22, 2024While ensembling deep neural networks has shown promise in improving generalization performance, scaling current ensemble methods for large models remains challenging. Given that recent progress in deep learning is largely driven by the scale, exemplified by the widespread adoption of large-scale neural network architectures, scalability emerges an increasingly critical issue for machine learning algorithms in the era of large-scale models. In this work, we first showcase the potential of low precision ensembling, where ensemble members are derived from a single model within low precision number systems in a training-free manner. Our empirical analysis demonstrates the effectiveness of our proposed low precision ensembling method compared to existing ensemble approaches.
Lipsum-FT: Robust Fine-Tuning of Zero-Shot Models Using Random Text Guidance
Apr 01, 2024



Large-scale contrastive vision-language pre-trained models provide the zero-shot model achieving competitive performance across a range of image classification tasks without requiring training on downstream data. Recent works have confirmed that while additional fine-tuning of the zero-shot model on the reference data results in enhanced downstream performance, it compromises the model's robustness against distribution shifts. Our investigation begins by examining the conditions required to achieve the goals of robust fine-tuning, employing descriptions based on feature distortion theory and joint energy-based models. Subsequently, we propose a novel robust fine-tuning algorithm, Lipsum-FT, that effectively utilizes the language modeling aspect of the vision-language pre-trained models. Extensive experiments conducted on distribution shift scenarios in DomainNet and ImageNet confirm the superiority of our proposed Lipsum-FT approach over existing robust fine-tuning methods.
Enhancing Transfer Learning with Flexible Nonparametric Posterior Sampling
Mar 12, 2024



Transfer learning has recently shown significant performance across various tasks involving deep neural networks. In these transfer learning scenarios, the prior distribution for downstream data becomes crucial in Bayesian model averaging (BMA). While previous works proposed the prior over the neural network parameters centered around the pre-trained solution, such strategies have limitations when dealing with distribution shifts between upstream and downstream data. This paper introduces nonparametric transfer learning (NPTL), a flexible posterior sampling method to address the distribution shift issue within the context of nonparametric learning. The nonparametric learning (NPL) method is a recent approach that employs a nonparametric prior for posterior sampling, efficiently accounting for model misspecification scenarios, which is suitable for transfer learning scenarios that may involve the distribution shift between upstream and downstream tasks. Through extensive empirical validations, we demonstrate that our approach surpasses other baselines in BMA performance.
Traversing Between Modes in Function Space for Fast Ensembling
Jun 20, 2023



Deep ensemble is a simple yet powerful way to improve the performance of deep neural networks. Under this motivation, recent works on mode connectivity have shown that parameters of ensembles are connected by low-loss subspaces, and one can efficiently collect ensemble parameters in those subspaces. While this provides a way to efficiently train ensembles, for inference, multiple forward passes should still be executed using all the ensemble parameters, which often becomes a serious bottleneck for real-world deployment. In this work, we propose a novel framework to reduce such costs. Given a low-loss subspace connecting two modes of a neural network, we build an additional neural network that predicts the output of the original neural network evaluated at a certain point in the low-loss subspace. The additional neural network, which we call a "bridge", is a lightweight network that takes minimal features from the original network and predicts outputs for the low-loss subspace without forward passes through the original network. We empirically demonstrate that we can indeed train such bridge networks and significantly reduce inference costs with the help of bridge networks.
SWAMP: Sparse Weight Averaging with Multiple Particles for Iterative Magnitude Pruning
May 24, 2023Given the ever-increasing size of modern neural networks, the significance of sparse architectures has surged due to their accelerated inference speeds and minimal memory demands. When it comes to global pruning techniques, Iterative Magnitude Pruning (IMP) still stands as a state-of-the-art algorithm despite its simple nature, particularly in extremely sparse regimes. In light of the recent finding that the two successive matching IMP solutions are linearly connected without a loss barrier, we propose Sparse Weight Averaging with Multiple Particles (SWAMP), a straightforward modification of IMP that achieves performance comparable to an ensemble of two IMP solutions. For every iteration, we concurrently train multiple sparse models, referred to as particles, using different batch orders yet the same matching ticket, and then weight average such models to produce a single mask. We demonstrate that our method consistently outperforms existing baselines across different sparsities through extensive experiments on various data and neural network structures.
Decoupled Training for Long-Tailed Classification With Stochastic Representations
Apr 19, 2023



Decoupling representation learning and classifier learning has been shown to be effective in classification with long-tailed data. There are two main ingredients in constructing a decoupled learning scheme; 1) how to train the feature extractor for representation learning so that it provides generalizable representations and 2) how to re-train the classifier that constructs proper decision boundaries by handling class imbalances in long-tailed data. In this work, we first apply Stochastic Weight Averaging (SWA), an optimization technique for improving the generalization of deep neural networks, to obtain better generalizing feature extractors for long-tailed classification. We then propose a novel classifier re-training algorithm based on stochastic representation obtained from the SWA-Gaussian, a Gaussian perturbed SWA, and a self-distillation strategy that can harness the diverse stochastic representations based on uncertainty estimates to build more robust classifiers. Extensive experiments on CIFAR10/100-LT, ImageNet-LT, and iNaturalist-2018 benchmarks show that our proposed method improves upon previous methods both in terms of prediction accuracy and uncertainty estimation.
Martingale Posterior Neural Processes
Apr 19, 2023



A Neural Process (NP) estimates a stochastic process implicitly defined with neural networks given a stream of data, rather than pre-specifying priors already known, such as Gaussian processes. An ideal NP would learn everything from data without any inductive biases, but in practice, we often restrict the class of stochastic processes for the ease of estimation. One such restriction is the use of a finite-dimensional latent variable accounting for the uncertainty in the functions drawn from NPs. Some recent works show that this can be improved with more "data-driven" source of uncertainty such as bootstrapping. In this work, we take a different approach based on the martingale posterior, a recently developed alternative to Bayesian inference. For the martingale posterior, instead of specifying prior-likelihood pairs, a predictive distribution for future data is specified. Under specific conditions on the predictive distribution, it can be shown that the uncertainty in the generated future data actually corresponds to the uncertainty of the implicitly defined Bayesian posteriors. Based on this result, instead of assuming any form of the latent variables, we equip a NP with a predictive distribution implicitly defined with neural networks and use the corresponding martingale posteriors as the source of uncertainty. The resulting model, which we name as Martingale Posterior Neural Process (MPNP), is demonstrated to outperform baselines on various tasks.
Improving Ensemble Distillation With Weight Averaging and Diversifying Perturbation
Jun 30, 2022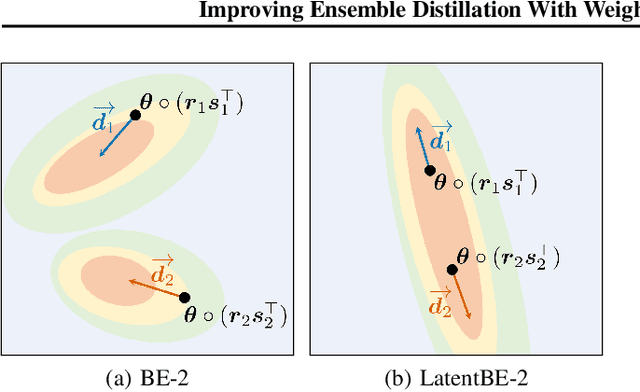

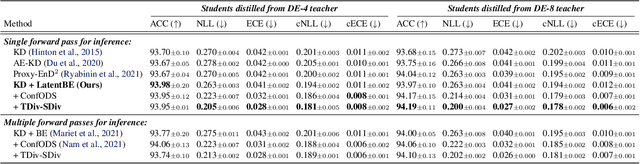

Ensembles of deep neural networks have demonstrated superior performance, but their heavy computational cost hinders applying them for resource-limited environments. It motivates distilling knowledge from the ensemble teacher into a smaller student network, and there are two important design choices for this ensemble distillation: 1) how to construct the student network, and 2) what data should be shown during training. In this paper, we propose a weight averaging technique where a student with multiple subnetworks is trained to absorb the functional diversity of ensemble teachers, but then those subnetworks are properly averaged for inference, giving a single student network with no additional inference cost. We also propose a perturbation strategy that seeks inputs from which the diversities of teachers can be better transferred to the student. Combining these two, our method significantly improves upon previous methods on various image classification tasks.
Diversity Matters When Learning From Ensembles
Oct 27, 2021
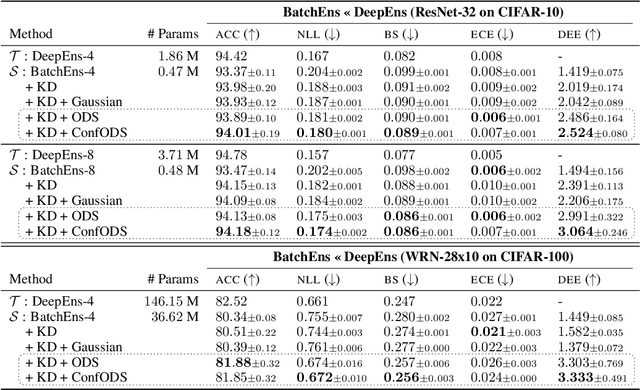
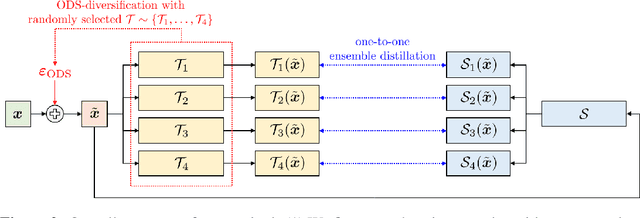
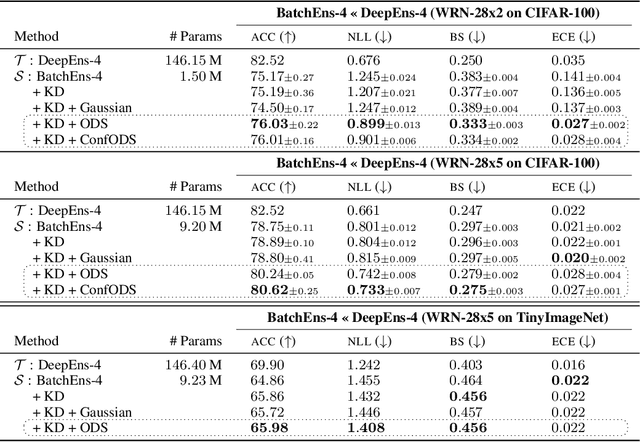
Deep ensembles excel in large-scale image classification tasks both in terms of prediction accuracy and calibration. Despite being simple to train, the computation and memory cost of deep ensembles limits their practicability. While some recent works propose to distill an ensemble model into a single model to reduce such costs, there is still a performance gap between the ensemble and distilled models. We propose a simple approach for reducing this gap, i.e., making the distilled performance close to the full ensemble. Our key assumption is that a distilled model should absorb as much function diversity inside the ensemble as possible. We first empirically show that the typical distillation procedure does not effectively transfer such diversity, especially for complex models that achieve near-zero training error. To fix this, we propose a perturbation strategy for distillation that reveals diversity by seeking inputs for which ensemble member outputs disagree. We empirically show that a model distilled with such perturbed samples indeed exhibits enhanced diversity, leading to improved performance.