 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Assisted Feature Transformation for Anomaly Detection
Mar 03, 2025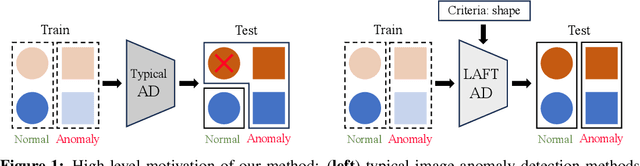
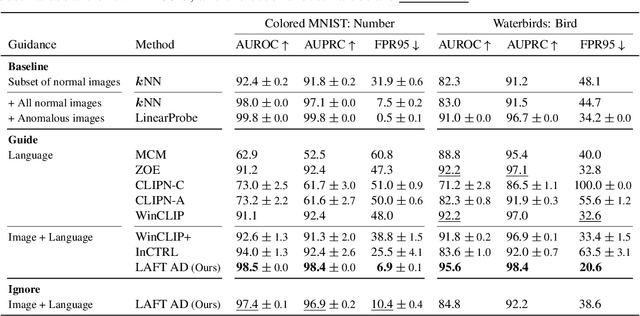
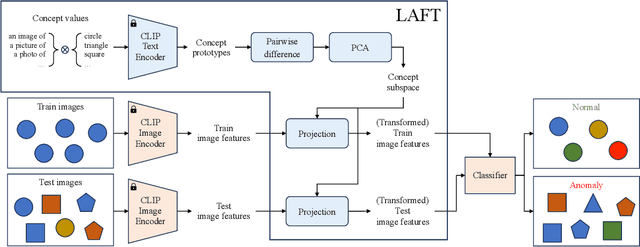
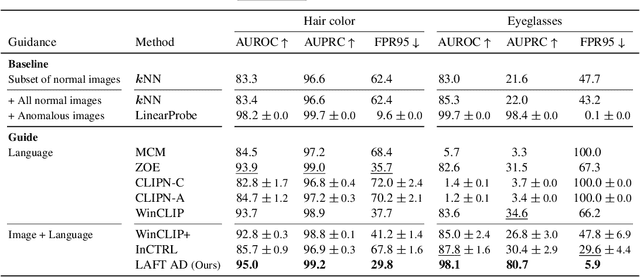
This paper introduces LAFT, a novel feature transformation method designed to incorporate user knowledge and preferences into anomaly detection using natural language. Accurately modeling the boundary of normality is crucial for distinguishing abnormal data, but this is often challenging due to limited data or the presence of nuisance attributes. While unsupervised methods that rely solely on data without user guidance are common, they may fail to detect anomalies of specific interest. To address this limitation, we propose Language-Assisted Feature Transformation (LAFT), which leverages the shared image-text embedding space of vision-language models to transform visual features according to user-defined requirements. Combined with anomaly detection methods, LAFT effectively aligns visual features with user preferences, allowing anomalies of interest to be detected. Extensive experiments on both toy and real-world datasets validate the effectiveness of our method.
A Simple Early Exiting Framework for Accelerated Sampling in Diffusion Models
Aug 12, 2024Diffusion models have shown remarkable performance in generation problems over various domains including images, videos, text, and audio. A practical bottleneck of diffusion models is their sampling speed, due to the repeated evaluation of score estimation networks during the inference. In this work, we propose a novel framework capable of adaptively allocating compute required for the score estimation, thereby reducing the overall sampling time of diffusion models. We observe that the amount of computation required for the score estimation may vary along the time step for which the score is estimated. Based on this observation, we propose an early-exiting scheme, where we skip the subset of parameters in the score estimation network during the inference, based on a time-dependent exit schedule. Using the diffusion models for image synthesis, we show that our method could significantly improve the sampling throughput of the diffusion models without compromising image quality. Furthermore, we also demonstrate that our method seamlessly integrates with various types of solvers for faster sampling, capitalizing on their compatibility to enhance overall efficiency. The source code and our experiments are available at \url{https://github.com/taehong-moon/ee-diffusion}
On-Off Pattern Encoding and Path-Count Encoding as Deep Neural Network Representations
Jan 17, 2024Understanding the encoded representation of Deep Neural Networks (DNNs) has been a fundamental yet challenging objective. In this work, we focus on two possible directions for analyzing representations of DNNs by studying simple image classification tasks. Specifically, we consider \textit{On-Off pattern} and \textit{PathCount} for investigating how information is stored in deep representations. On-off pattern of a neuron is decided as `on' or `off' depending on whether the neuron's activation after ReLU is non-zero or zero. PathCount is the number of paths that transmit non-zero energy from the input to a neuron. We investigate how neurons in the network encodes information by replacing each layer's activation with On-Off pattern or PathCount and evaluating its effect on classification performance. We also examine correlation between representation and PathCount. Finally, we show a possible way to improve an existing DNN interpretation method, Class Activation Map (CAM), by directly utilizing On-Off or PathCount.
A Generative Self-Supervised Framework using Functional Connectivity in fMRI Data
Dec 04, 2023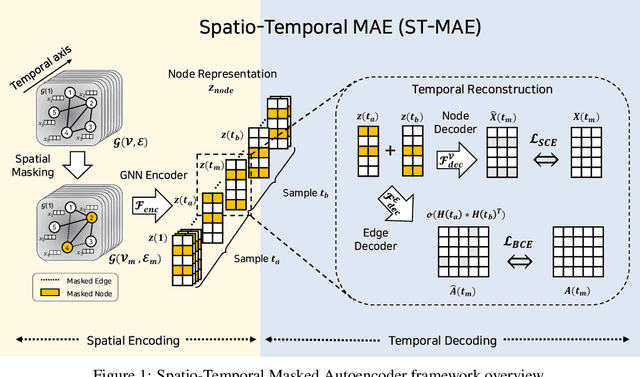
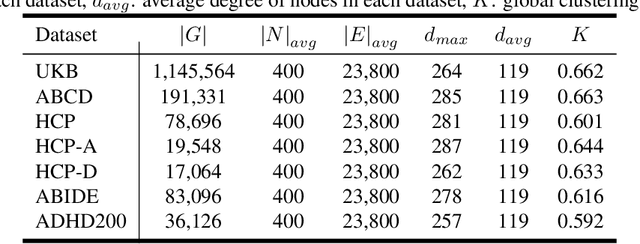
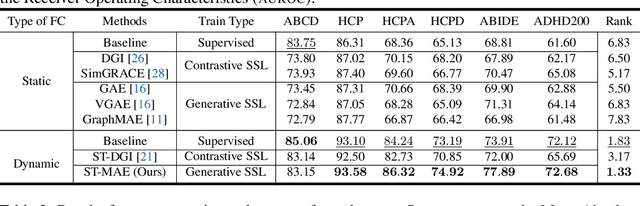
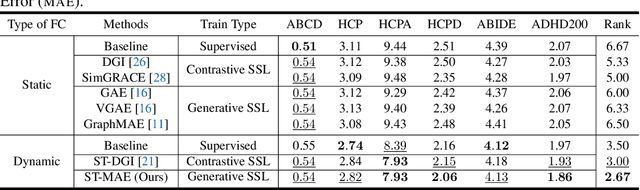
Deep neural networks trained on Functional Connectivity (FC) networks extracted from functional Magnetic Resonance Imaging (fMRI) data have gained popularity due to the increasing availability of data and advances in model architectures, including Graph Neural Network (GNN). Recent research on the application of GNN to FC suggests that exploiting the time-varying properties of the FC could significantly improve the accuracy and interpretability of the model prediction. However, the high cost of acquiring high-quality fMRI data and corresponding phenotypic labels poses a hurdle to their application in real-world settings, such that a model na\"ively trained in a supervised fashion can suffer from insufficient performance or a lack of generalization on a small number of data. In addition, most Self-Supervised Learning (SSL) approaches for GNNs to date adopt a contrastive strategy, which tends to lose appropriate semantic information when the graph structure is perturbed or does not leverage both spatial and temporal information simultaneously. In light of these challenges, we propose a generative SSL approach that is tailored to effectively harness spatio-temporal information within dynamic FC. Our empirical results, experimented with large-scale (>50,000) fMRI datasets, demonstrate that our approach learns valuable representations and enables the construction of accurate and robust models when fine-tuned for downstream tasks.
Probabilistic Imputation for Time-series Classification with Missing Data
Aug 13, 2023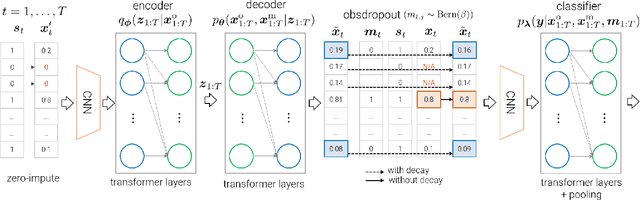
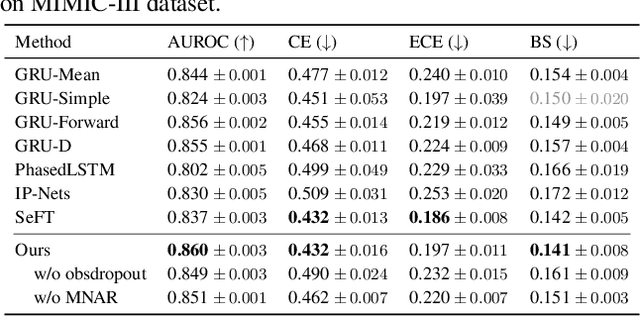
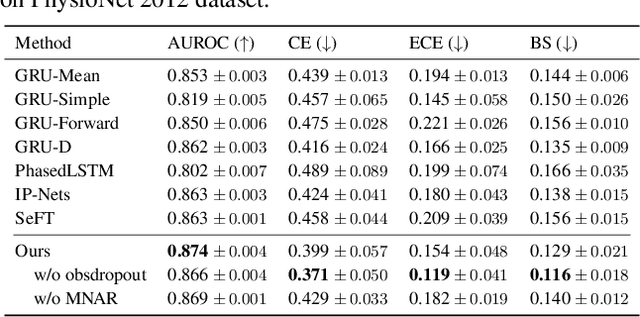
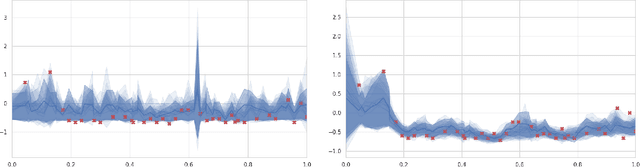
Multivariate time series data for real-world applications typically contain a significant amount of missing values. The dominant approach for classification with such missing values is to impute them heuristically with specific values (zero, mean, values of adjacent time-steps) or learnable parameters. However, these simple strategies do not take the data generative process into account, and more importantly, do not effectively capture the uncertainty in prediction due to the multiple possibilities for the missing values. In this paper, we propose a novel probabilistic framework for classification with multivariate time series data with missing values. Our model consists of two parts; a deep generative model for missing value imputation and a classifier. Extending the existing deep generative models to better capture structures of time-series data, our deep generative model part is trained to impute the missing values in multiple plausible ways, effectively modeling the uncertainty of the imputation. The classifier part takes the time series data along with the imputed missing values and classifies signals, and is trained to capture the predictive uncertainty due to the multiple possibilities of imputations. Importantly, we show that na\"ively combining the generative model and the classifier could result in trivial solutions where the generative model does not produce meaningful imputations. To resolve this, we present a novel regularization technique that can promote the model to produce useful imputation values that help classification. Through extensive experiments on real-world time series data with missing values, we demonstrate the effectiveness of our method.
Traversing Between Modes in Function Space for Fast Ensembling
Jun 20, 2023



Deep ensemble is a simple yet powerful way to improve the performance of deep neural networks. Under this motivation, recent works on mode connectivity have shown that parameters of ensembles are connected by low-loss subspaces, and one can efficiently collect ensemble parameters in those subspaces. While this provides a way to efficiently train ensembles, for inference, multiple forward passes should still be executed using all the ensemble parameters, which often becomes a serious bottleneck for real-world deployment. In this work, we propose a novel framework to reduce such costs. Given a low-loss subspace connecting two modes of a neural network, we build an additional neural network that predicts the output of the original neural network evaluated at a certain point in the low-loss subspace. The additional neural network, which we call a "bridge", is a lightweight network that takes minimal features from the original network and predicts outputs for the low-loss subspace without forward passes through the original network. We empirically demonstrate that we can indeed train such bridge networks and significantly reduce inference costs with the help of bridge networks.