 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Early Exiting Framework for Accelerated Sampling in Diffusion Models
Aug 12, 2024Diffusion models have shown remarkable performance in generation problems over various domains including images, videos, text, and audio. A practical bottleneck of diffusion models is their sampling speed, due to the repeated evaluation of score estimation networks during the inference. In this work, we propose a novel framework capable of adaptively allocating compute required for the score estimation, thereby reducing the overall sampling time of diffusion models. We observe that the amount of computation required for the score estimation may vary along the time step for which the score is estimated. Based on this observation, we propose an early-exiting scheme, where we skip the subset of parameters in the score estimation network during the inference, based on a time-dependent exit schedule. Using the diffusion models for image synthesis, we show that our method could significantly improve the sampling throughput of the diffusion models without compromising image quality. Furthermore, we also demonstrate that our method seamlessly integrates with various types of solvers for faster sampling, capitalizing on their compatibility to enhance overall efficiency. The source code and our experiments are available at \url{https://github.com/taehong-moon/ee-diffusion}
Fast Ensembling with Diffusion Schrödinger Bridge
Apr 24, 2024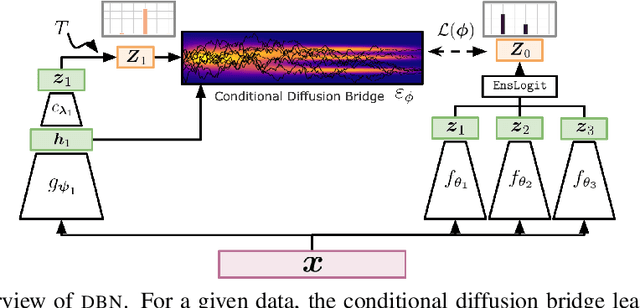
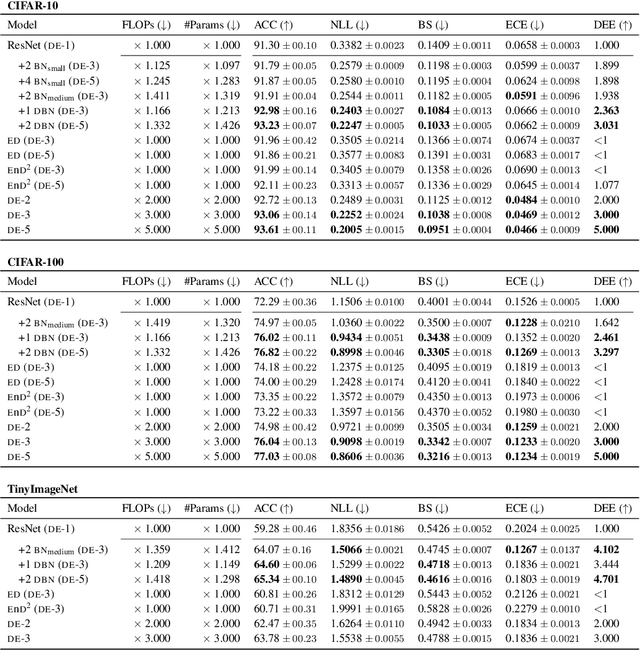
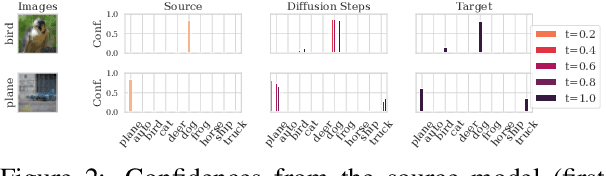

Deep Ensemble (DE) approach is a straightforward technique used to enhance the performance of deep neural networks by training them from different initial points, converging towards various local optima. However, a limitation of this methodology lies in its high computational overhead for inference, arising from the necessity to store numerous learned parameters and execute individual forward passes for each parameter during the inference stage. We propose a novel approach called Diffusion Bridge Network (DBN) to address this challenge. Based on the theory of the Schr\"odinger bridge, this method directly learns to simulate an Stochastic Differential Equation (SDE) that connects the output distribution of a single ensemble member to the output distribution of the ensembled model, allowing us to obtain ensemble prediction without having to invoke forward pass through all the ensemble models. By substituting the heavy ensembles with this lightweight neural network constructing DBN, we achieved inference with reduced computational cost while maintaining accuracy and uncertainty scores on benchmark datasets such as CIFAR-10, CIFAR-100, and TinyImageNet. Our implementation is available at https://github.com/kim-hyunsu/dbn.
Sequential Flow Straightening for Generative Modeling
Feb 15, 2024Straightening the probability flow of the continuous-time generative models, such as diffusion models or flow-based models, is the key to fast sampling through the numerical solvers, existing methods learn a linear path by directly generating the probability path the joint distribution between the noise and data distribution. One key reason for the slow sampling speed of the ODE-based solvers that simulate these generative models is the global truncation error of the ODE solver, caused by the high curvature of the ODE trajectory, which explodes the truncation error of the numerical solvers in the low-NFE regime. To address this challenge, We propose a novel method called SeqRF, a learning technique that straightens the probability flow to reduce the global truncation error and hence enable acceleration of sampling and improve the synthesis quality. In both theoretical and empirical studies, we first observe the straightening property of our SeqRF. Through empirical evaluations via SeqRF over flow-based generative models, We achieve surpassing results on CIFAR-10, CelebA-$64 \times 64$, and LSUN-Church datasets.
Diversity Matters When Learning From Ensembles
Oct 27, 2021
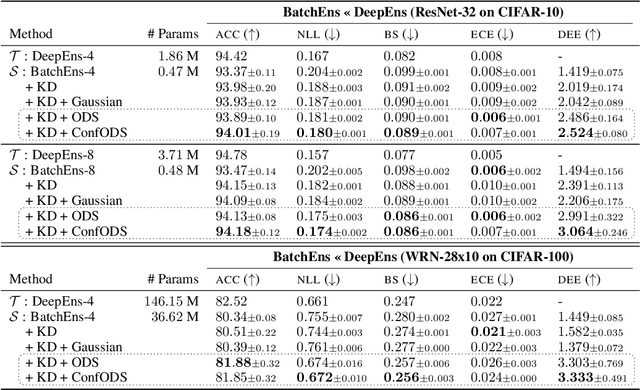
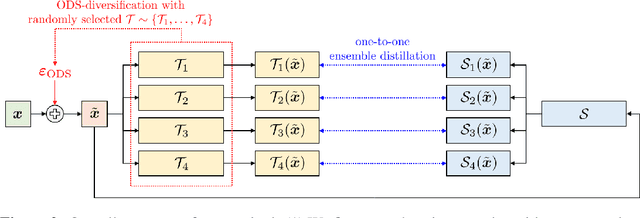
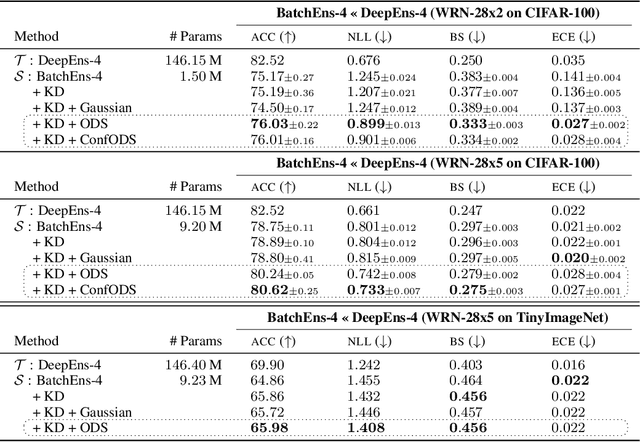
Deep ensembles excel in large-scale image classification tasks both in terms of prediction accuracy and calibration. Despite being simple to train, the computation and memory cost of deep ensembles limits their practicability. While some recent works propose to distill an ensemble model into a single model to reduce such costs, there is still a performance gap between the ensemble and distilled models. We propose a simple approach for reducing this gap, i.e., making the distilled performance close to the full ensemble. Our key assumption is that a distilled model should absorb as much function diversity inside the ensemble as possible. We first empirically show that the typical distillation procedure does not effectively transfer such diversity, especially for complex models that achieve near-zero training error. To fix this, we propose a perturbation strategy for distillation that reveals diversity by seeking inputs for which ensemble member outputs disagree. We empirically show that a model distilled with such perturbed samples indeed exhibits enhanced diversity, leading to improved performance.
Adversarial purification with Score-based generative models
Jun 11, 2021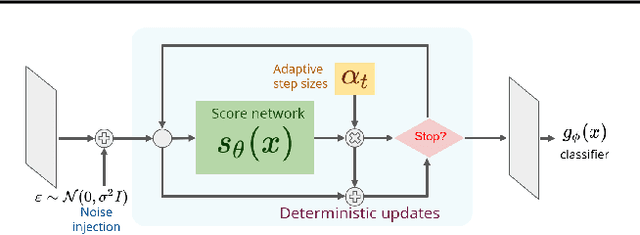

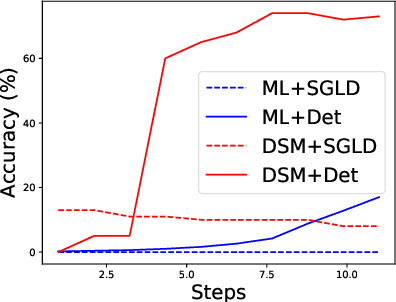
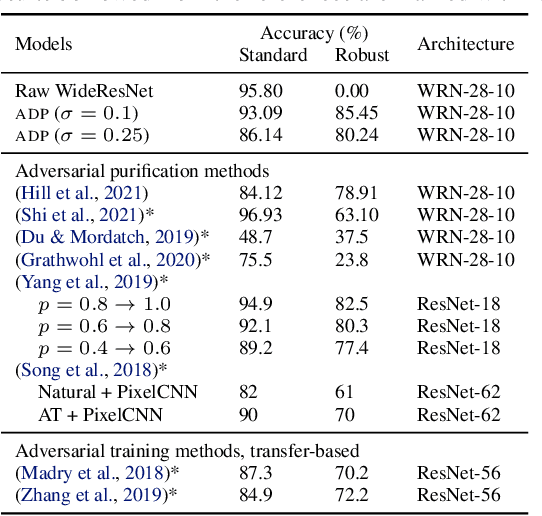
While adversarial training is considered as a standard defense method against adversarial attacks for image classifiers, adversarial purification, which purifies attacked images into clean images with a standalone purification model, has shown promises as an alternative defense method. Recently, an Energy-Based Model (EBM) trained with Markov-Chain Monte-Carlo (MCMC) has been highlighted as a purification model, where an attacked image is purified by running a long Markov-chain using the gradients of the EBM. Yet, the practicality of the adversarial purification using an EBM remains questionable because the number of MCMC steps required for such purification is too large. In this paper, we propose a novel adversarial purification method based on an EBM trained with Denoising Score-Matching (DSM). We show that an EBM trained with DSM can quickly purify attacked images within a few steps. We further introduce a simple yet effective randomized purification scheme that injects random noises into images before purification. This process screens the adversarial perturbations imposed on images by the random noises and brings the images to the regime where the EBM can denoise well. We show that our purification method is robust against various attacks and demonstrate its state-of-the-art performances.