 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Neighbors with PHIBP: Predicting Infectious Disease Dynamics in Data-Sparse Environments
Dec 24, 2025



Modeling sparse count data, which arise across numerous scientific fields, presents significant statistical challenges. This chapter addresses these challenges in the context of infectious disease prediction, with a focus on predicting outbreaks in geographic regions that have historically reported zero cases. To this end, we present the detailed computational framework and experimental application of the Poisson Hierarchical Indian Buffet Process (PHIBP), with demonstrated success in handling sparse count data in microbiome and ecological studies. The PHIBP's architecture, grounded in the concept of absolute abundance, systematically borrows statistical strength from related regions and circumvents the known sensitivities of relative-rate methods to zero counts. Through a series of experiments on infectious disease data, we show that this principled approach provides a robust foundation for generating coherent predictive distributions and for the effective use of comparative measures such as alpha and beta diversity. The chapter's emphasis on algorithmic implementation and experimental results confirms that this unified framework delivers both accurate outbreak predictions and meaningful epidemiological insights in data-sparse settings.
Compact Memory for Continual Logistic Regression
Nov 12, 2025Despite recent progress, continual learning still does not match the performance of batch training. To avoid catastrophic forgetting, we need to build compact memory of essential past knowledge, but no clear solution has yet emerged, even for shallow neural networks with just one or two layers. In this paper, we present a new method to build compact memory for logistic regression. Our method is based on a result by Khan and Swaroop [2021] who show the existence of optimal memory for such models. We formulate the search for the optimal memory as Hessian-matching and propose a probabilistic PCA method to estimate them. Our approach can drastically improve accuracy compared to Experience Replay. For instance, on Split-ImageNet, we get 60% accuracy compared to 30% obtained by replay with memory-size equivalent to 0.3% of the data size. Increasing the memory size to 2% further boosts the accuracy to 74%, closing the gap to the batch accuracy of 77.6% on this task. Our work opens a new direction for building compact memory that can also be useful in the future for continual deep learning.
Functional Adjoint Sampler: Scalable Sampling on Infinite Dimensional Spaces
Nov 09, 2025



Learning-based methods for sampling from the Gibbs distribution in finite-dimensional spaces have progressed quickly, yet theory and algorithmic design for infinite-dimensional function spaces remain limited. This gap persists despite their strong potential for sampling the paths of conditional diffusion processes, enabling efficient simulation of trajectories of diffusion processes that respect rare events or boundary constraints. In this work, we present the adjoint sampler for infinite-dimensional function spaces, a stochastic optimal control-based diffusion sampler that operates in function space and targets Gibbs-type distributions on infinite-dimensional Hilbert spaces. Our Functional Adjoint Sampler (FAS) generalizes Adjoint Sampling (Havens et al., 2025) to Hilbert spaces based on a SOC theory called stochastic maximum principle, yielding a simple and scalable matching-type objective for a functional representation. We show that FAS achieves superior transition path sampling performance across synthetic potential and real molecular systems, including Alanine Dipeptide and Chignolin.
Improving Constrained Generation in Language Models via Self-Distilled Twisted Sequential Monte Carlo
Jul 03, 2025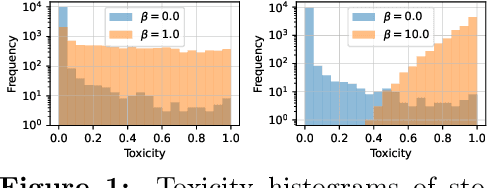
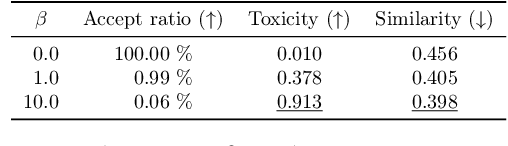
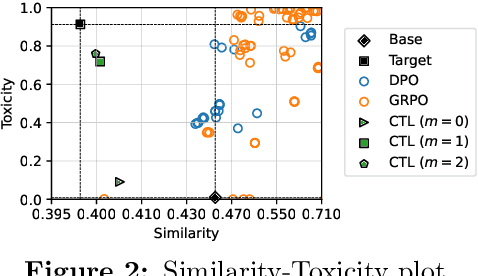

Recent work has framed constrained text generation with autoregressive language models as a probabilistic inference problem. Among these, Zhao et al. (2024) introduced a promising approach based on twisted Sequential Monte Carlo, which incorporates learned twist functions and twist-induced proposals to guide the generation process. However, in constrained generation settings where the target distribution concentrates on outputs that are unlikely under the base model, learning becomes challenging due to sparse and uninformative reward signals. We show that iteratively refining the base model through self-distillation alleviates this issue by making the model progressively more aligned with the target, leading to substantial gains in generation quality.
Bayesian Neural Scaling Laws Extrapolation with Prior-Fitted Networks
May 29, 2025



Scaling has been a major driver of recent advancements in deep learning. Numerous empirical studies have found that scaling laws often follow the power-law and proposed several variants of power-law functions to predict the scaling behavior at larger scales. However, existing methods mostly rely on point estimation and do not quantify uncertainty, which is crucial for real-world applications involving decision-making problems such as determining the expected performance improvements achievable by investing additional computational resources. In this work, we explore a Bayesian framework based on Prior-data Fitted Networks (PFNs) for neural scaling law extrapolation. Specifically, we design a prior distribution that enables the sampling of infinitely many synthetic functions resembling real-world neural scaling laws, allowing our PFN to meta-learn the extrapolation. We validate the effectiveness of our approach on real-world neural scaling laws, comparing it against both the existing point estimation methods and Bayesian approaches. Our method demonstrates superior performance, particularly in data-limited scenarios such as Bayesian active learning, underscoring its potential for reliable, uncertainty-aware extrapolation in practical applications.
FedSVD: Adaptive Orthogonalization for Private Federated Learning with LoRA
May 19, 2025Low-Rank Adaptation (LoRA), which introduces a product of two trainable low-rank matrices into frozen pre-trained weights, is widely used for efficient fine-tuning of language models in federated learning (FL). However, when combined with differentially private stochastic gradient descent (DP-SGD), LoRA faces substantial noise amplification: DP-SGD perturbs per-sample gradients, and the matrix multiplication of the LoRA update ($BA$) intensifies this effect. Freezing one matrix (e.g., $A$) reduces the noise but restricts model expressiveness, often resulting in suboptimal adaptation. To address this, we propose FedSVD, a simple yet effective method that introduces a global reparameterization based on singular value decomposition (SVD). In our approach, each client optimizes only the $B$ matrix and transmits it to the server. The server aggregates the $B$ matrices, computes the product $BA$ using the previous $A$, and refactorizes the result via SVD. This yields a new adaptive $A$ composed of the orthonormal right singular vectors of $BA$, and an updated $B$ containing the remaining SVD components. This reparameterization avoids quadratic noise amplification, while allowing $A$ to better capture the principal directions of the aggregate updates. Moreover, the orthonormal structure of $A$ bounds the gradient norms of $B$ and preserves more signal under DP-SGD, as confirmed by our theoretical analysis. As a result, FedSVD consistently improves stability and performance across a variety of privacy settings and benchmarks, outperforming relevant baselines under both private and non-private regimes.
StarFT: Robust Fine-tuning of Zero-shot Models via Spuriosity Alignment
May 19, 2025Learning robust representations from data often requires scale, which has led to the success of recent zero-shot models such as CLIP. However, the obtained robustness can easily be deteriorated when these models are fine-tuned on other downstream tasks (e.g., of smaller scales). Previous works often interpret this phenomenon in the context of domain shift, developing fine-tuning methods that aim to preserve the original domain as much as possible. However, in a different context, fine-tuned models with limited data are also prone to learning features that are spurious to humans, such as background or texture. In this paper, we propose StarFT (Spurious Textual Alignment Regularization), a novel framework for fine-tuning zero-shot models to enhance robustness by preventing them from learning spuriosity. We introduce a regularization that aligns the output distribution for spuriosity-injected labels with the original zero-shot model, ensuring that the model is not induced to extract irrelevant features further from these descriptions.We leverage recent language models to get such spuriosity-injected labels by generating alternative textual descriptions that highlight potentially confounding features.Extensive experiments validate the robust generalization of StarFT and its emerging properties: zero-shot group robustness and improved zero-shot classification. Notably, StarFT boosts both worst-group and average accuracy by 14.30% and 3.02%, respectively, in the Waterbirds group shift scenario, where other robust fine-tuning baselines show even degraded performance.
Variational Bayesian Pseudo-Coreset
Feb 28, 2025The success of deep learning requires large datasets and extensive training, which can create significant computational challenges. To address these challenges, pseudo-coresets, small learnable datasets that mimic the entire data, have been proposed. Bayesian Neural Networks, which offer predictive uncertainty and probabilistic interpretation for deep neural networks, also face issues with large-scale datasets due to their high-dimensional parameter space. Prior works on Bayesian Pseudo-Coresets (BPC) attempt to reduce the computational load for computing weight posterior distribution by a small number of pseudo-coresets but suffer from memory inefficiency during BPC training and sub-optimal results. To overcome these limitations, we propose Variational Bayesian Pseudo-Coreset (VBPC), a novel approach that utilizes variational inference to efficiently approximate the posterior distribution, reducing memory usage and computational costs while improving performance across benchmark datasets.
Dimension Agnostic Neural Processes
Feb 28, 2025



Meta-learning aims to train models that can generalize to new tasks with limited labeled data by extracting shared features across diverse task datasets. Additionally, it accounts for prediction uncertainty during both training and evaluation, a concept known as uncertainty-aware meta-learning. Neural Process(NP) is a well-known uncertainty-aware meta-learning method that constructs implicit stochastic processes using parametric neural networks, enabling rapid adaptation to new tasks. However, existing NP methods face challenges in accommodating diverse input dimensions and learned features, limiting their broad applicability across regression tasks. To address these limitations and advance the utility of NP models as general regressors, we introduce Dimension Agnostic Neural Processes(DANP). DANP incorporates Dimension Aggregator Block(DAB) to transform input features into a fixed-dimensional space, enhancing the model's ability to handle diverse datasets. Furthermore, leveraging the Transformer architecture and latent encoding layers, DANP learns a wider range of features that are generalizable across various tasks. Through comprehensive experimentation on various synthetic and practical regression tasks, we empirically show that DANP outperforms previous NP variations, showcasing its effectiveness in overcoming the limitations of traditional NP models and its potential for broader applicability in diverse regression scenarios.
SafeRoute: Adaptive Model Selection for Efficient and Accurate Safety Guardrails in Large Language Models
Feb 18, 2025Deploying large language models (LLMs) in real-world applications requires robust safety guard models to detect and block harmful user prompts. While large safety guard models achieve strong performance, their computational cost is substantial. To mitigate this, smaller distilled models are used, but they often underperform on "hard" examples where the larger model provides accurate predictions. We observe that many inputs can be reliably handled by the smaller model, while only a small fraction require the larger model's capacity. Motivated by this, we propose SafeRoute, a binary router that distinguishes hard examples from easy ones. Our method selectively applies the larger safety guard model to the data that the router considers hard, improving efficiency while maintaining accuracy compared to solely using the larger safety guard model. Experimental results on multiple benchmark datasets demonstrate that our adaptive model selection significantly enhances the trade-off between computational cost and safety performance, outperforming relevant baselines.