 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Alignment Backfires: Preventing the Re-emergence of Suppressed Concepts in Fine-tuned Text-to-Image Diffusion Models
Nov 30, 2024Fine-tuning text-to-image diffusion models is widely used for personalization and adaptation for new domains. In this paper, we identify a critical vulnerability of fine-tuning: safety alignment methods designed to filter harmful content (e.g., nudity) can break down during fine-tuning, allowing previously suppressed content to resurface, even when using benign datasets. While this "fine-tuning jailbreaking" issue is known in large language models, it remains largely unexplored in text-to-image diffusion models. Our investigation reveals that standard fine-tuning can inadvertently undo safety measures, causing models to relearn harmful concepts that were previously removed and even exacerbate harmful behaviors. To address this issue, we present a novel but immediate solution called Modular LoRA, which involves training Safety Low-Rank Adaptation (LoRA) modules separately from Fine-Tuning LoRA components and merging them during inference. This method effectively prevents the re-learning of harmful content without compromising the model's performance on new tasks. Our experiments demonstrate that Modular LoRA outperforms traditional fine-tuning methods in maintaining safety alignment, offering a practical approach for enhancing the security of text-to-image diffusion models against potential attacks.
A Simple Early Exiting Framework for Accelerated Sampling in Diffusion Models
Aug 12, 2024Diffusion models have shown remarkable performance in generation problems over various domains including images, videos, text, and audio. A practical bottleneck of diffusion models is their sampling speed, due to the repeated evaluation of score estimation networks during the inference. In this work, we propose a novel framework capable of adaptively allocating compute required for the score estimation, thereby reducing the overall sampling time of diffusion models. We observe that the amount of computation required for the score estimation may vary along the time step for which the score is estimated. Based on this observation, we propose an early-exiting scheme, where we skip the subset of parameters in the score estimation network during the inference, based on a time-dependent exit schedule. Using the diffusion models for image synthesis, we show that our method could significantly improve the sampling throughput of the diffusion models without compromising image quality. Furthermore, we also demonstrate that our method seamlessly integrates with various types of solvers for faster sampling, capitalizing on their compatibility to enhance overall efficiency. The source code and our experiments are available at \url{https://github.com/taehong-moon/ee-diffusion}
Towards Safe Self-Distillation of Internet-Scale Text-to-Image Diffusion Models
Jul 12, 2023Large-scale image generation models, with impressive quality made possible by the vast amount of data available on the Internet, raise social concerns that these models may generate harmful or copyrighted content. The biases and harmfulness arise throughout the entire training process and are hard to completely remove, which have become significant hurdles to the safe deployment of these models. In this paper, we propose a method called SDD to prevent problematic content generation in text-to-image diffusion models. We self-distill the diffusion model to guide the noise estimate conditioned on the target removal concept to match the unconditional one. Compared to the previous methods, our method eliminates a much greater proportion of harmful content from the generated images without degrading the overall image quality. Furthermore, our method allows the removal of multiple concepts at once, whereas previous works are limited to removing a single concept at a time.
SWAMP: Sparse Weight Averaging with Multiple Particles for Iterative Magnitude Pruning
May 24, 2023Given the ever-increasing size of modern neural networks, the significance of sparse architectures has surged due to their accelerated inference speeds and minimal memory demands. When it comes to global pruning techniques, Iterative Magnitude Pruning (IMP) still stands as a state-of-the-art algorithm despite its simple nature, particularly in extremely sparse regimes. In light of the recent finding that the two successive matching IMP solutions are linearly connected without a loss barrier, we propose Sparse Weight Averaging with Multiple Particles (SWAMP), a straightforward modification of IMP that achieves performance comparable to an ensemble of two IMP solutions. For every iteration, we concurrently train multiple sparse models, referred to as particles, using different batch orders yet the same matching ticket, and then weight average such models to produce a single mask. We demonstrate that our method consistently outperforms existing baselines across different sparsities through extensive experiments on various data and neural network structures.
Equal Experience in Recommender Systems
Oct 12, 2022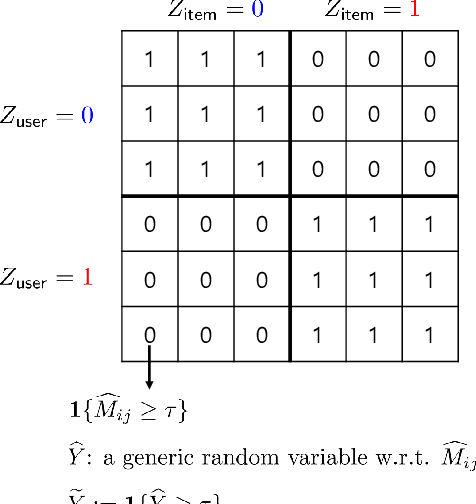
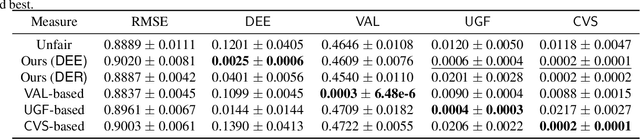

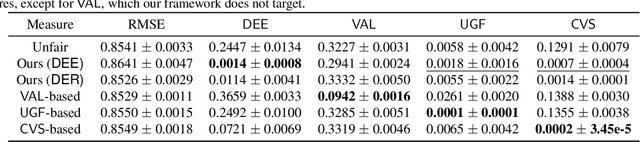
We explore the fairness issue that arises in recommender systems. Biased data due to inherent stereotypes of particular groups (e.g., male students' average rating on mathematics is often higher than that on humanities, and vice versa for females) may yield a limited scope of suggested items to a certain group of users. Our main contribution lies in the introduction of a novel fairness notion (that we call equal experience), which can serve to regulate such unfairness in the presence of biased data. The notion captures the degree of the equal experience of item recommendations across distinct groups. We propose an optimization framework that incorporates the fairness notion as a regularization term, as well as introduce computationally-efficient algorithms that solve the optimization. Experiments on synthetic and benchmark real datasets demonstrate that the proposed framework can indeed mitigate such unfairness while exhibiting a minor degradation of recommendation accuracy.