 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUTE-Planner: Confidence-aware Uneven Terrain Exploration Planner
Nov 17, 2025Planetary exploration robots must navigate uneven terrain while building reliable maps for space missions. However, most existing methods incorporate traversability constraints but may not handle high uncertainty in elevation estimates near complex features like craters, do not consider exploration strategies for uncertainty reduction, and typically fail to address how elevation uncertainty affects navigation safety and map quality. To address the problems, we propose a framework integrating safe path generation, adaptive confidence updates, and confidence-aware exploration strategies. Using Kalman-based elevation estimation, our approach generates terrain traversability and confidence scores, then incorporates them into Graph-Based exploration Planner (GBP) to prioritize exploration of traversable low-confidence regions. We evaluate our framework through simulated lunar experiments using a novel low-confidence region ratio metric, achieving 69% uncertainty reduction compared to baseline GBP. In terms of mission success rate, our method achieves 100% while baseline GBP achieves 0%, demonstrating improvements in exploration safety and map reliability.
Few-Shot Pattern Detection via Template Matching and Regression
Aug 25, 2025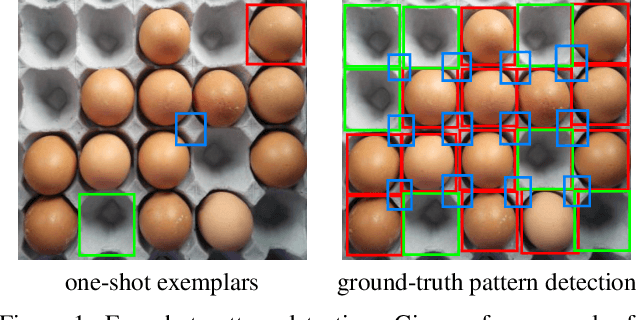


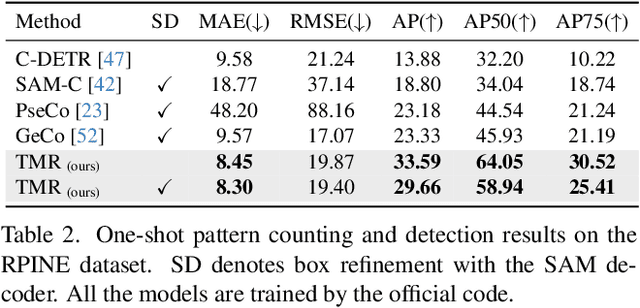
We address the problem of few-shot pattern detection, which aims to detect all instances of a given pattern, typically represented by a few exemplars, from an input image. Although similar problems have been studied in few-shot object counting and detection (FSCD), previous methods and their benchmarks have narrowed patterns of interest to object categories and often fail to localize non-object patterns. In this work, we propose a simple yet effective detector based on template matching and regression, dubbed TMR. While previous FSCD methods typically represent target exemplars as spatially collapsed prototypes and lose structural information, we revisit classic template matching and regression. It effectively preserves and leverages the spatial layout of exemplars through a minimalistic structure with a small number of learnable convolutional or projection layers on top of a frozen backbone We also introduce a new dataset, dubbed RPINE, which covers a wider range of patterns than existing object-centric datasets. Our method outperforms the state-of-the-art methods on the three benchmarks, RPINE, FSCD-147, and FSCD-LVIS, and demonstrates strong generalization in cross-dataset evaluation.
Locality-Aware Zero-Shot Human-Object Interaction Detection
May 26, 2025Recent methods for zero-shot Human-Object Interaction (HOI) detection typically leverage the generalization ability of large Vision-Language Model (VLM), i.e., CLIP, on unseen categories, showing impressive results on various zero-shot settings. However, existing methods struggle to adapt CLIP representations for human-object pairs, as CLIP tends to overlook fine-grained information necessary for distinguishing interactions. To address this issue, we devise, LAIN, a novel zero-shot HOI detection framework enhancing the locality and interaction awareness of CLIP representations. The locality awareness, which involves capturing fine-grained details and the spatial structure of individual objects, is achieved by aggregating the information and spatial priors of adjacent neighborhood patches. The interaction awareness, which involves identifying whether and how a human is interacting with an object, is achieved by capturing the interaction pattern between the human and the object. By infusing locality and interaction awareness into CLIP representation, LAIN captures detailed information about the human-object pairs. Our extensive experiments on existing benchmarks show that LAIN outperforms previous methods on various zero-shot settings, demonstrating the importance of locality and interaction awareness for effective zero-shot HOI detection.
Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model
May 23, 2025The choice of initial noise significantly affects the quality and prompt alignment of video diffusion models, where different noise seeds for the same prompt can lead to drastically different generations. While recent methods rely on externally designed priors such as frequency filters or inter-frame smoothing, they often overlook internal model signals that indicate which noise seeds are inherently preferable. To address this, we propose ANSE (Active Noise Selection for Generation), a model-aware framework that selects high-quality noise seeds by quantifying attention-based uncertainty. At its core is BANSA (Bayesian Active Noise Selection via Attention), an acquisition function that measures entropy disagreement across multiple stochastic attention samples to estimate model confidence and consistency. For efficient inference-time deployment, we introduce a Bernoulli-masked approximation of BANSA that enables score estimation using a single diffusion step and a subset of attention layers. Experiments on CogVideoX-2B and 5B demonstrate that ANSE improves video quality and temporal coherence with only an 8% and 13% increase in inference time, respectively, providing a principled and generalizable approach to noise selection in video diffusion. See our project page: https://anse-project.github.io/anse-project/
Safety Alignment Backfires: Preventing the Re-emergence of Suppressed Concepts in Fine-tuned Text-to-Image Diffusion Models
Nov 30, 2024Fine-tuning text-to-image diffusion models is widely used for personalization and adaptation for new domains. In this paper, we identify a critical vulnerability of fine-tuning: safety alignment methods designed to filter harmful content (e.g., nudity) can break down during fine-tuning, allowing previously suppressed content to resurface, even when using benign datasets. While this "fine-tuning jailbreaking" issue is known in large language models, it remains largely unexplored in text-to-image diffusion models. Our investigation reveals that standard fine-tuning can inadvertently undo safety measures, causing models to relearn harmful concepts that were previously removed and even exacerbate harmful behaviors. To address this issue, we present a novel but immediate solution called Modular LoRA, which involves training Safety Low-Rank Adaptation (LoRA) modules separately from Fine-Tuning LoRA components and merging them during inference. This method effectively prevents the re-learning of harmful content without compromising the model's performance on new tasks. Our experiments demonstrate that Modular LoRA outperforms traditional fine-tuning methods in maintaining safety alignment, offering a practical approach for enhancing the security of text-to-image diffusion models against potential attacks.
EVT: Efficient View Transformation for Multi-Modal 3D Object Detection
Nov 19, 2024



Multi-modal sensor fusion in bird's-eye-view (BEV) representation has become the leading approach in 3D object detection. However, existing methods often rely on depth estimators or transformer encoders for view transformation, incurring substantial computational overhead. Furthermore, the lack of precise geometric correspondence between 2D and 3D spaces leads to spatial and ray-directional misalignments, restricting the effectiveness of BEV representations. To address these challenges, we propose a novel 3D object detector via efficient view transformation (EVT), which leverages a well-structured BEV representation to enhance accuracy and efficiency. EVT focuses on two main areas. First, it employs Adaptive Sampling and Adaptive Projection (ASAP), using LiDAR guidance to generate 3D sampling points and adaptive kernels. The generated points and kernels are then used to facilitate the transformation of image features into BEV space and refine the BEV features. Second, EVT includes an improved transformer-based detection framework, which contains a group-wise query initialization method and an enhanced query update framework. It is designed to effectively utilize the obtained multi-modal BEV features within the transformer decoder. By leveraging the geometric properties of object queries, this framework significantly enhances detection performance, especially in a multi-layer transformer decoder structure. EVT achieves state-of-the-art performance on the nuScenes test set with real-time inference speed.
Quantum Support Vector Machine-Based Classification of GPS Signal Reception Conditions
Aug 11, 2024



Global Positioning System (GPS) plays a critical role in navigation by utilizing satellite signals, but its accuracy in urban environments is often compromised by signal obstructions. Previous research has categorized GPS reception conditions into line-of-sight (LOS), non-line-of-sight (NLOS), and LOS+NLOS scenarios to enhance accuracy. This paper introduces a novel approach using quantum support vector machines (QSVM) with a ZZ feature map and fidelity quantum kernel to classify urban GPS signal reception conditions, comparing its performance against classical SVM methods. While classical SVM has been previously explored for this purpose, our study is the first to apply QSVM to this classification task. We conducted experiments using datasets from two distinct urban locations to train and evaluate SVM and QSVM models. Our results demonstrate that QSVM achieves superior classification accuracy compared to classical SVM for urban GPS signal datasets. Additionally, we emphasize the importance of appropriately scaling raw data when utilizing QSVM.
Burst Image Super-Resolution with Base Frame Selection
Jun 25, 2024Burst image super-resolution has been a topic of active research in recent years due to its ability to obtain a high-resolution image by using complementary information between multiple frames in the burst. In this work, we explore using burst shots with non-uniform exposures to confront real-world practical scenarios by introducing a new benchmark dataset, dubbed Non-uniformly Exposed Burst Image (NEBI), that includes the burst frames at varying exposure times to obtain a broader range of irradiance and motion characteristics within a scene. As burst shots with non-uniform exposures exhibit varying levels of degradation, fusing information of the burst shots into the first frame as a base frame may not result in optimal image quality. To address this limitation, we propose a Frame Selection Network (FSN) for non-uniform scenarios. This network seamlessly integrates into existing super-resolution methods in a plug-and-play manner with low computational costs. The comparative analysis reveals the effectiveness of the nonuniform setting for the practical scenario and our FSN on synthetic-/real- NEBI datasets.
Results and Lessons Learned from Autonomous Driving Transportation Services in Airfield, Crowded Indoor, and Urban Environments
Mar 02, 2024Autonomous vehicles have been actively investigated over the past few decades. Several recent works show the potential of autonomous driving transportation services in urban environments with impressive experimental results. However, these works note that autonomous vehicles are still occasionally inferior to expert drivers in complex scenarios. Furthermore, they do not focus on the possibilities of autonomous driving transportation services in other areas beyond urban environments. This paper presents the research results and lessons learned from autonomous driving transportation services in airfield, crowded indoor, and urban environments. We discuss how we address several unique challenges in these diverse environments. We also offer an overview of remaining challenges that have not received much attention but must be addressed. This paper aims to share our unique experience to support researchers who are interested in realizing the potential of autonomous vehicles in various real-world environments.
Slot-Mixup with Subsampling: A Simple Regularization for WSI Classification
Nov 29, 2023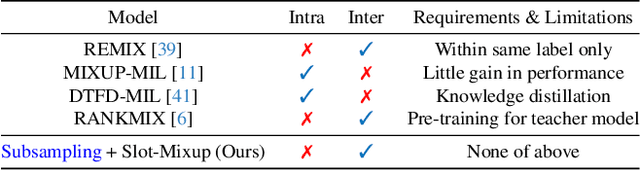
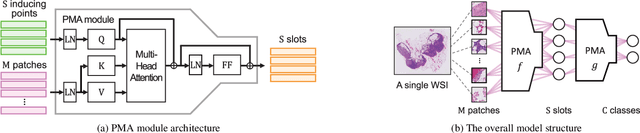
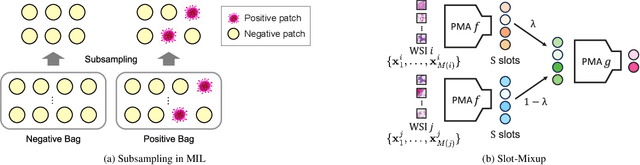
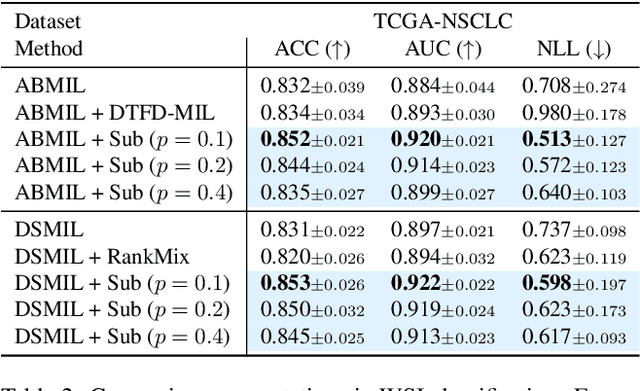
Whole slide image (WSI) classification requires repetitive zoom-in and out for pathologists, as only small portions of the slide may be relevant to detecting cancer. Due to the lack of patch-level labels, multiple instance learning (MIL) is a common practice for training a WSI classifier. One of the challenges in MIL for WSIs is the weak supervision coming only from the slide-level labels, often resulting in severe overfitting. In response, researchers have considered adopting patch-level augmentation or applying mixup augmentation, but their applicability remains unverified. Our approach augments the training dataset by sampling a subset of patches in the WSI without significantly altering the underlying semantics of the original slides. Additionally, we introduce an efficient model (Slot-MIL) that organizes patches into a fixed number of slots, the abstract representation of patches, using an attention mechanism. We empirically demonstrate that the subsampling augmentation helps to make more informative slots by restricting the over-concentration of attention and to improve interpretability. Finally, we illustrate that combining our attention-based aggregation model with subsampling and mixup, which has shown limited compatibility in existing MIL methods, can enhance both generalization and calibration. Our proposed methods achieve the state-of-the-art performance across various benchmark datasets including class imbalance and distribution shifts.