 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward the Frontiers of Reliable Diffusion Sampling via Adversarial Sinkhorn Attention Guidance
Nov 10, 2025Diffusion models have demonstrated strong generative performance when using guidance methods such as classifier-free guidance (CFG), which enhance output quality by modifying the sampling trajectory. These methods typically improve a target output by intentionally degrading another, often the unconditional output, using heuristic perturbation functions such as identity mixing or blurred conditions. However, these approaches lack a principled foundation and rely on manually designed distortions. In this work, we propose Adversarial Sinkhorn Attention Guidance (ASAG), a novel method that reinterprets attention scores in diffusion models through the lens of optimal transport and intentionally disrupt the transport cost via Sinkhorn algorithm. Instead of naively corrupting the attention mechanism, ASAG injects an adversarial cost within self-attention layers to reduce pixel-wise similarity between queries and keys. This deliberate degradation weakens misleading attention alignments and leads to improved conditional and unconditional sample quality. ASAG shows consistent improvements in text-to-image diffusion, and enhances controllability and fidelity in downstream applications such as IP-Adapter and ControlNet. The method is lightweight, plug-and-play, and improves reliability without requiring any model retraining.
Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model
May 23, 2025The choice of initial noise significantly affects the quality and prompt alignment of video diffusion models, where different noise seeds for the same prompt can lead to drastically different generations. While recent methods rely on externally designed priors such as frequency filters or inter-frame smoothing, they often overlook internal model signals that indicate which noise seeds are inherently preferable. To address this, we propose ANSE (Active Noise Selection for Generation), a model-aware framework that selects high-quality noise seeds by quantifying attention-based uncertainty. At its core is BANSA (Bayesian Active Noise Selection via Attention), an acquisition function that measures entropy disagreement across multiple stochastic attention samples to estimate model confidence and consistency. For efficient inference-time deployment, we introduce a Bernoulli-masked approximation of BANSA that enables score estimation using a single diffusion step and a subset of attention layers. Experiments on CogVideoX-2B and 5B demonstrate that ANSE improves video quality and temporal coherence with only an 8% and 13% increase in inference time, respectively, providing a principled and generalizable approach to noise selection in video diffusion. See our project page: https://anse-project.github.io/anse-project/
Single-Step Bidirectional Unpaired Image Translation Using Implicit Bridge Consistency Distillation
Mar 19, 2025



Unpaired image-to-image translation has seen significant progress since the introduction of CycleGAN. However, methods based on diffusion models or Schr\"odinger bridges have yet to be widely adopted in real-world applications due to their iterative sampling nature. To address this challenge, we propose a novel framework, Implicit Bridge Consistency Distillation (IBCD), which enables single-step bidirectional unpaired translation without using adversarial loss. IBCD extends consistency distillation by using a diffusion implicit bridge model that connects PF-ODE trajectories between distributions. Additionally, we introduce two key improvements: 1) distribution matching for consistency distillation and 2) adaptive weighting method based on distillation difficulty. Experimental results demonstrate that IBCD achieves state-of-the-art performance on benchmark datasets in a single generation step. Project page available at https://hyn2028.github.io/project_page/IBCD/index.html
PLADIS: Pushing the Limits of Attention in Diffusion Models at Inference Time by Leveraging Sparsity
Mar 10, 2025
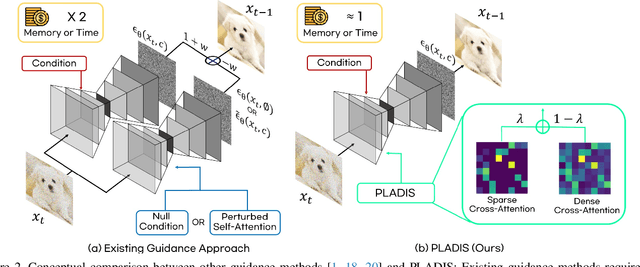
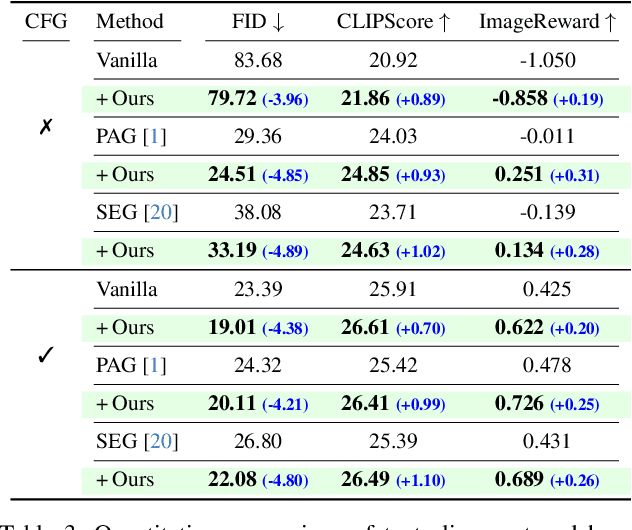

Diffusion models have shown impressive results in generating high-quality conditional samples using guidance techniques such as Classifier-Free Guidance (CFG). However, existing methods often require additional training or neural function evaluations (NFEs), making them incompatible with guidance-distilled models. Also, they rely on heuristic approaches that need identifying target layers. In this work, we propose a novel and efficient method, termed PLADIS, which boosts pre-trained models (U-Net/Transformer) by leveraging sparse attention. Specifically, we extrapolate query-key correlations using softmax and its sparse counterpart in the cross-attention layer during inference, without requiring extra training or NFEs. By leveraging the noise robustness of sparse attention, our PLADIS unleashes the latent potential of text-to-image diffusion models, enabling them to excel in areas where they once struggled with newfound effectiveness. It integrates seamlessly with guidance techniques, including guidance-distilled models. Extensive experiments show notable improvements in text alignment and human preference, offering a highly efficient and universally applicable solution.
OTSeg: Multi-prompt Sinkhorn Attention for Zero-Shot Semantic Segmentation
Mar 21, 2024



The recent success of CLIP has demonstrated promising results in zero-shot semantic segmentation by transferring muiltimodal knowledge to pixel-level classification. However, leveraging pre-trained CLIP knowledge to closely align text embeddings with pixel embeddings still has limitations in existing approaches. To address this issue, we propose OTSeg, a novel multimodal attention mechanism aimed at enhancing the potential of multiple text prompts for matching associated pixel embeddings. We first propose Multi-Prompts Sinkhorn (MPS) based on the Optimal Transport (OT) algorithm, which leads multiple text prompts to selectively focus on various semantic features within image pixels. Moreover, inspired by the success of Sinkformers in unimodal settings, we introduce the extension of MPS, called Multi-Prompts Sinkhorn Attention (MPSA), which effectively replaces cross-attention mechanisms within Transformer framework in multimodal settings. Through extensive experiments, we demonstrate that OTSeg achieves state-of-the-art (SOTA) performance with significant gains on Zero-Shot Semantic Segmentation (ZS3) tasks across three benchmark datasets.
UNICORN: Ultrasound Nakagami Imaging via Score Matching and Adaptation
Mar 10, 2024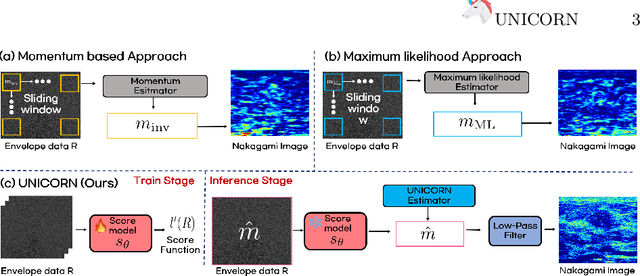
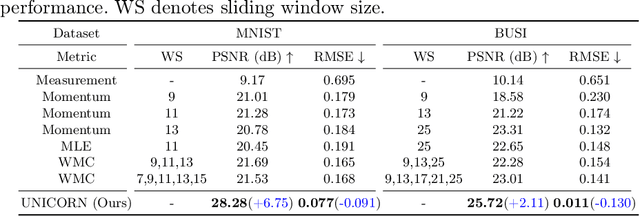
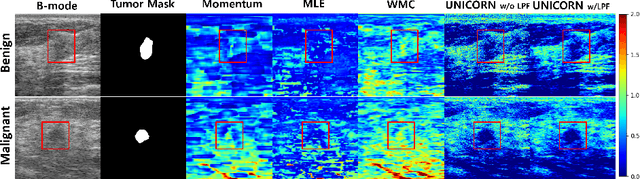

Nakagami imaging holds promise for visualizing and quantifying tissue scattering in ultrasound waves, with potential applications in tumor diagnosis and fat fraction estimation which are challenging to discern by conventional ultrasound B-mode images. Existing methods struggle with optimal window size selection and suffer from estimator instability, leading to degraded resolution images. To address this, here we propose a novel method called UNICORN (Ultrasound Nakagami Imaging via Score Matching and Adaptation), that offers an accurate, closed-form estimator for Nakagami parameter estimation in terms of the score function of ultrasonic envelope. Extensive experiments using simulation and real ultrasound RF data demonstrate UNICORN's superiority over conventional approaches in accuracy and resolution quality.
RO-LLaMA: Generalist LLM for Radiation Oncology via Noise Augmentation and Consistency Regularization
Nov 27, 2023Recent advancements in Artificial Intelligence (AI) have profoundly influenced medical fields, by providing tools to reduce clinical workloads. However, most AI models are constrained to execute uni-modal tasks, in stark contrast to the comprehensive approaches utilized by medical professionals. To address this, here we present RO-LLaMA, a versatile generalist large language model (LLM) tailored for the field of radiation oncology. This model seamlessly covers a wide range of the workflow of radiation oncologists, adept at various tasks such as clinical report summarization, radiation therapy plan suggestion, and plan-guided therapy target volume segmentation. In particular, to maximize the end-to-end performance, we further present a novel Consistency Embedding Fine-Tuning (CEFTune) technique, which boosts LLM's robustness to additional errors at the intermediates while preserving the capability of handling clean inputs, and creatively transform this concept into LLM-driven segmentation framework as Consistency Embedding Segmentation (CESEG). Experimental results on multi-centre cohort sets demonstrate our proposed RO-LLaMA's promising performance for diverse tasks with generalization capabilities.
Unpaired Image-to-Image Translation via Neural Schrödinger Bridge
May 24, 2023Diffusion models are a powerful class of generative models which simulate stochastic differential equations (SDEs) to generate data from noise. Although diffusion models have achieved remarkable progress in recent years, they have limitations in the unpaired image-to-image translation tasks due to the Gaussian prior assumption. Schr\"odinger Bridge (SB), which learns an SDE to translate between two arbitrary distributions, have risen as an attractive solution to this problem. However, none of SB models so far have been successful at unpaired translation between high-resolution images. In this work, we propose the Unpaired Neural Schr\"odinger Bridge (UNSB), which combines SB with adversarial training and regularization to learn a SB between unpaired data. We demonstrate that UNSB is scalable, and that it successfully solves various unpaired image-to-image translation tasks. Code: \url{https://github.com/cyclomon/UNSB}
ZegOT: Zero-shot Segmentation Through Optimal Transport of Text Prompts
Jan 28, 2023



Recent success of large-scale Contrastive Language-Image Pre-training (CLIP) has led to great promise in zero-shot semantic segmentation by transferring image-text aligned knowledge to pixel-level classification. However, existing methods usually require an additional image encoder or retraining/tuning the CLIP module. Here, we present a cost-effective strategy using text-prompt learning that keeps the entire CLIP module frozen while fully leveraging its rich information. Specifically, we propose a novel Zero-shot segmentation with Optimal Transport (ZegOT) method that matches multiple text prompts with frozen image embeddings through optimal transport, which allows each text prompt to efficiently focus on specific semantic attributes. Additionally, we propose Deep Local Feature Alignment (DLFA) that deeply aligns the text prompts with intermediate local feature of the frozen image encoder layers, which significantly boosts the zero-shot segmentation performance. Through extensive experiments on benchmark datasets, we show that our method achieves the state-of-the-art (SOTA) performance with only x7 lighter parameters compared to previous SOTA approaches.
Noise Distribution Adaptive Self-Supervised Image Denoising using Tweedie Distribution and Score Matching
Dec 05, 2021
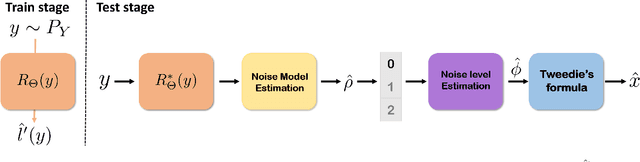
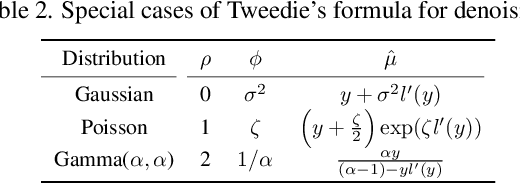

Tweedie distributions are a special case of exponential dispersion models, which are often used in classical statistics as distributions for generalized linear models. Here, we reveal that Tweedie distributions also play key roles in modern deep learning era, leading to a distribution independent self-supervised image denoising formula without clean reference images. Specifically, by combining with the recent Noise2Score self-supervised image denoising approach and the saddle point approximation of Tweedie distribution, we can provide a general closed-form denoising formula that can be used for large classes of noise distributions without ever knowing the underlying noise distribution. Similar to the original Noise2Score, the new approach is composed of two successive steps: score matching using perturbed noisy images, followed by a closed form image denoising formula via distribution-independent Tweedie's formula. This also suggests a systematic algorithm to estimate the noise model and noise parameters for a given noisy image data set. Through extensive experiments, we demonstrate that the proposed method can accurately estimate noise models and parameters, and provide the state-of-the-art self-supervised image denoising performance in the benchmark dataset and real-world dataset.