 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Variational Adversarial Active Learning
Paper and Code
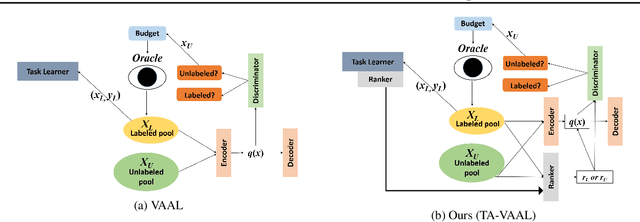
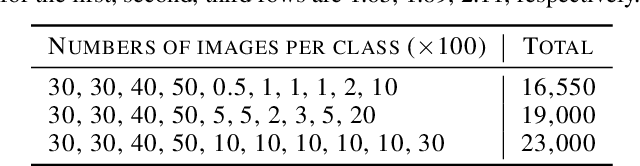
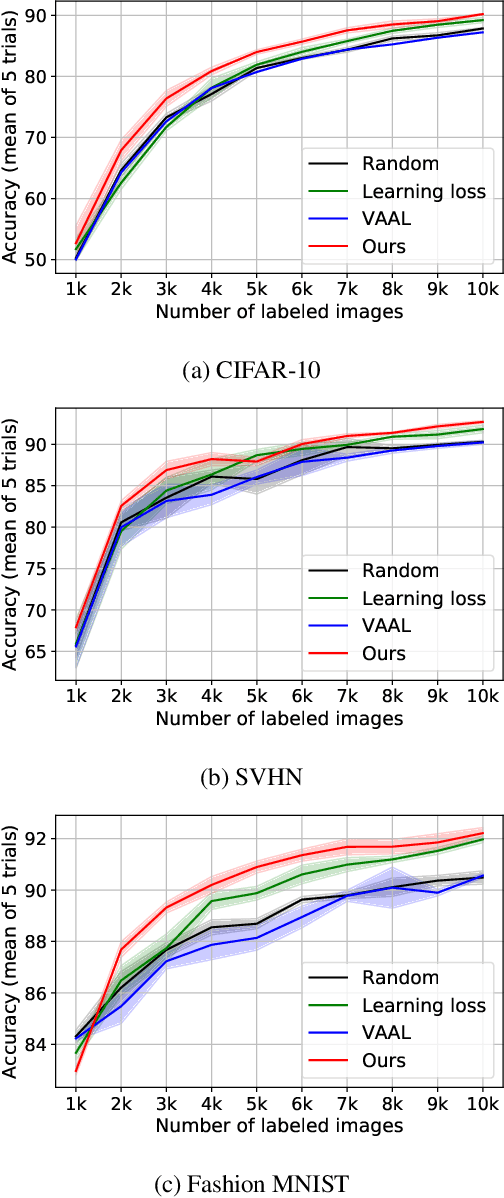
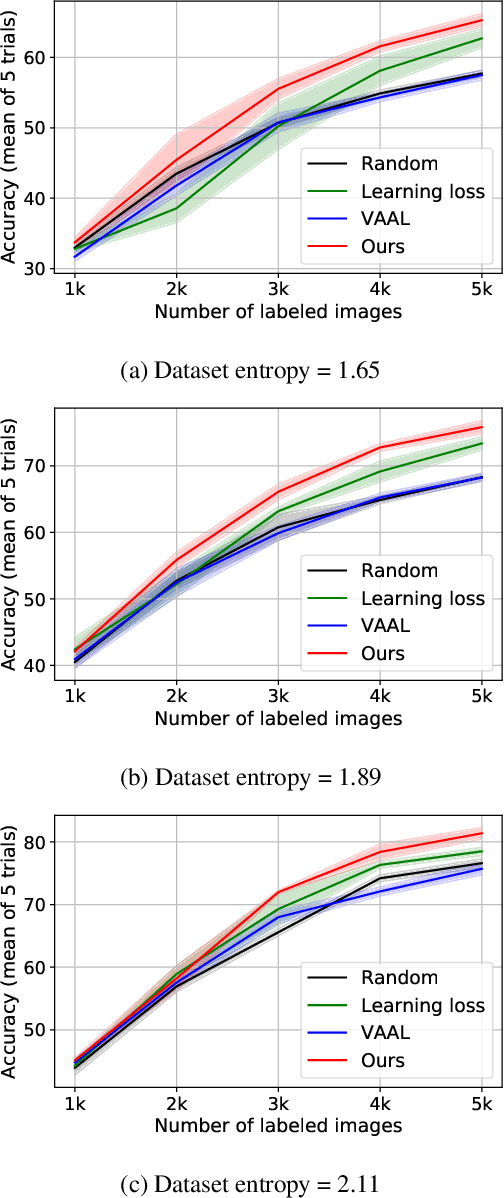
Deep learning has achieved remarkable performance in various tasks thanks to massive labeled datasets. However, there are often cases where labeling large amount of data is challenging or infeasible due to high labeling cost such as labeling by experts or long labeling time per large-scale data sample (e.g., video, very large image). Active learning is one of the ways to query the most informative samples to be annotated among massive unlabeled pool. Two promising directions for active learning that have been recently explored are data distribution-based approach to select data points that are far from current labeled pool and model uncertainty-based approach that relies on the perspective of task model. Unfortunately, the former does not exploit structures from tasks and the latter does not seem to well-utilize overall data distribution. Here, we propose the methods that simultaneously take advantage of both data distribution and model uncertainty approaches. Our proposed methods exploit variational adversarial active learning (VAAL), that considered data distribution of both label and unlabeled pools, by incorporating learning loss prediction module and RankCGAN concept into VAAL by modeling loss prediction as a ranker. We demonstrate that our proposed methods outperform recent state-of-the-art active learning methods on various balanced and imbalanced benchmark datasets.