 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Unified Demosaicing for Bayer and Non-Bayer Patterned Image Sensors
Jul 20, 2023As the physical size of recent CMOS image sensors (CIS) gets smaller, the latest mobile cameras are adopting unique non-Bayer color filter array (CFA) patterns (e.g., Quad, Nona, QxQ), which consist of homogeneous color units with adjacent pixels. These non-Bayer sensors are superior to conventional Bayer CFA thanks to their changeable pixel-bin sizes for different light conditions but may introduce visual artifacts during demosaicing due to their inherent pixel pattern structures and sensor hardware characteristics. Previous demosaicing methods have primarily focused on Bayer CFA, necessitating distinct reconstruction methods for non-Bayer patterned CIS with various CFA modes under different lighting conditions. In this work, we propose an efficient unified demosaicing method that can be applied to both conventional Bayer RAW and various non-Bayer CFAs' RAW data in different operation modes. Our Knowledge Learning-based demosaicing model for Adaptive Patterns, namely KLAP, utilizes CFA-adaptive filters for only 1% key filters in the network for each CFA, but still manages to effectively demosaic all the CFAs, yielding comparable performance to the large-scale models. Furthermore, by employing meta-learning during inference (KLAP-M), our model is able to eliminate unknown sensor-generic artifacts in real RAW data, effectively bridging the gap between synthetic images and real sensor RAW. Our KLAP and KLAP-M methods achieved state-of-the-art demosaicing performance in both synthetic and real RAW data of Bayer and non-Bayer CFAs.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
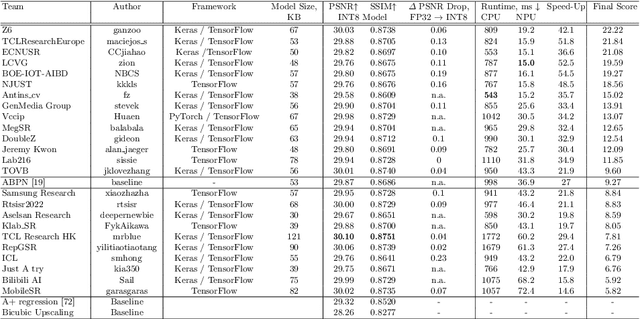
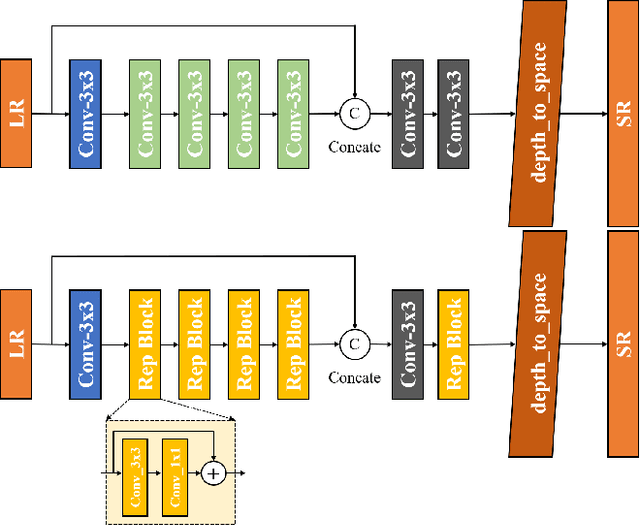
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Efficient Single-Image Depth Estimation on Mobile Devices, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022

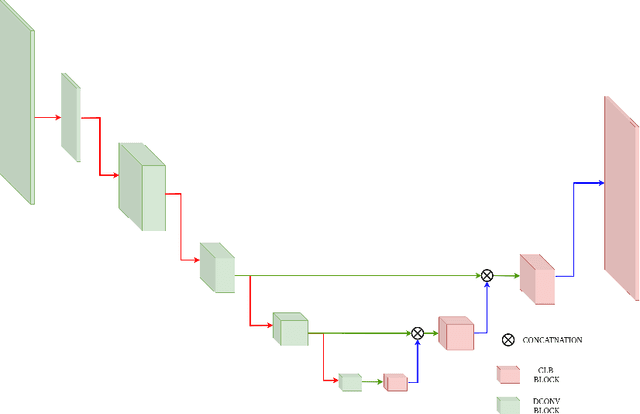
Various depth estimation models are now widely used on many mobile and IoT devices for image segmentation, bokeh effect rendering, object tracking and many other mobile tasks. Thus, it is very crucial to have efficient and accurate depth estimation models that can run fast on low-power mobile chipsets. In this Mobile AI challenge, the target was to develop deep learning-based single image depth estimation solutions that can show a real-time performance on IoT platforms and smartphones. For this, the participants used a large-scale RGB-to-depth dataset that was collected with the ZED stereo camera capable to generated depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the Raspberry Pi 4 platform, where the developed solutions were able to generate VGA resolution depth maps at up to 27 FPS while achieving high fidelity results. All models developed in the challenge are also compatible with any Android or Linux-based mobile devices, their detailed description is provided in this paper.
Coil2Coil: Self-supervised MR image denoising using phased-array coil images
Aug 16, 2022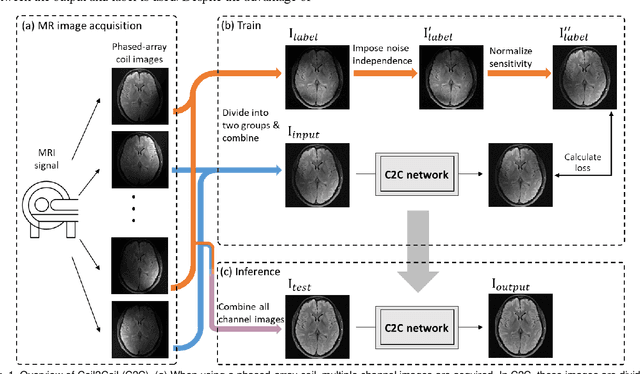
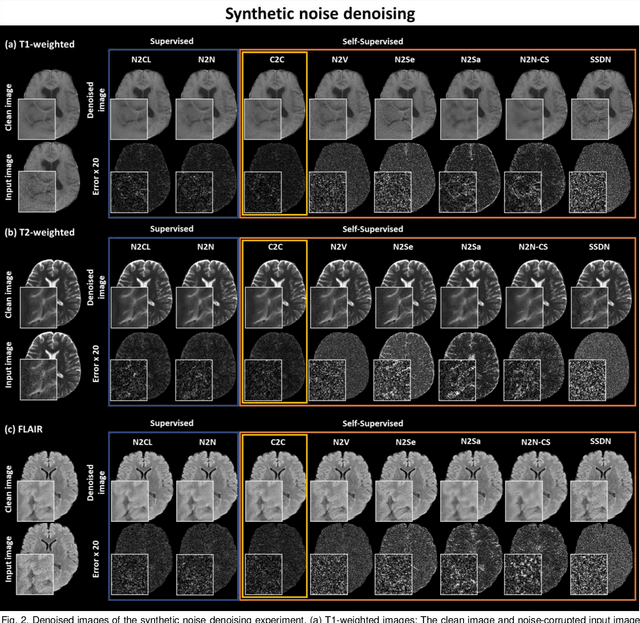
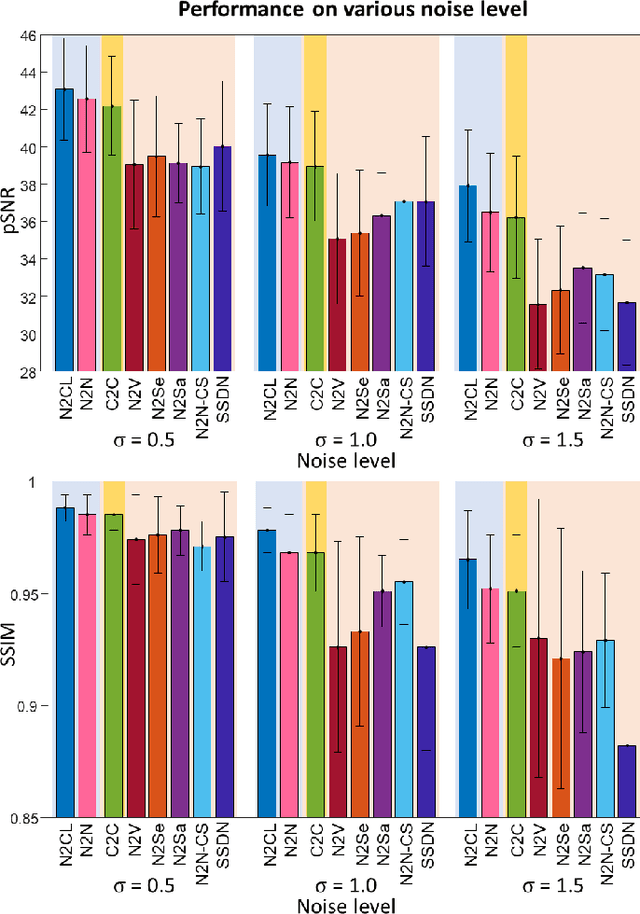
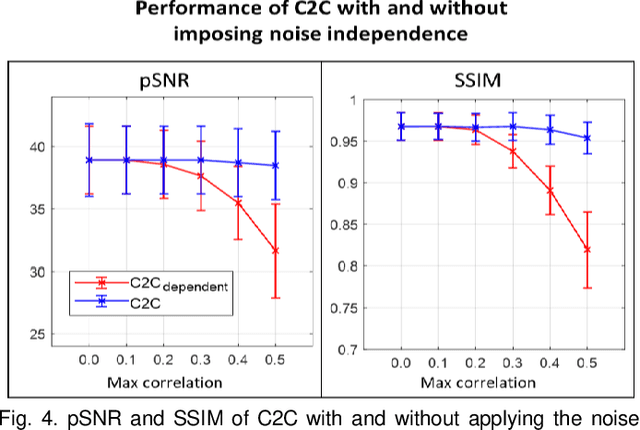
Denoising of magnetic resonance images is beneficial in improving the quality of low signal-to-noise ratio images. Recently, denoising using deep neural networks has demonstrated promising results. Most of these networks, however, utilize supervised learning, which requires large training images of noise-corrupted and clean image pairs. Obtaining training images, particularly clean images, is expensive and time-consuming. Hence, methods such as Noise2Noise (N2N) that require only pairs of noise-corrupted images have been developed to reduce the burden of obtaining training datasets. In this study, we propose a new self-supervised denoising method, Coil2Coil (C2C), that does not require the acquisition of clean images or paired noise-corrupted images for training. Instead, the method utilizes multichannel data from phased-array coils to generate training images. First, it divides and combines multichannel coil images into two images, one for input and the other for label. Then, they are processed to impose noise independence and sensitivity normalization such that they can be used for the training images of N2N. For inference, the method inputs a coil-combined image (e.g., DICOM image), enabling a wide application of the method. When evaluated using synthetic noise-added images, C2C shows the best performance against several self-supervised methods, reporting comparable outcomes to supervised methods. When testing the DICOM images, C2C successfully denoised real noise without showing structure-dependent residuals in the error maps. Because of the significant advantage of not requiring additional scans for clean or paired images, the method can be easily utilized for various clinical applications.
Self-supervised regression learning using domain knowledge: Applications to improving self-supervised denoising in imaging
May 10, 2022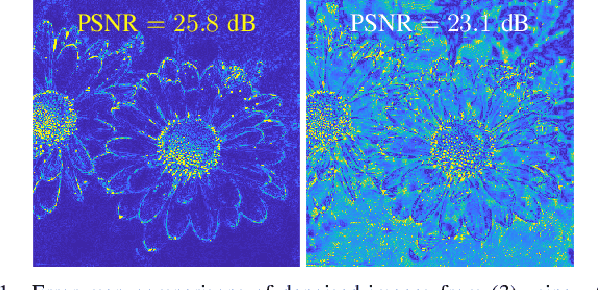
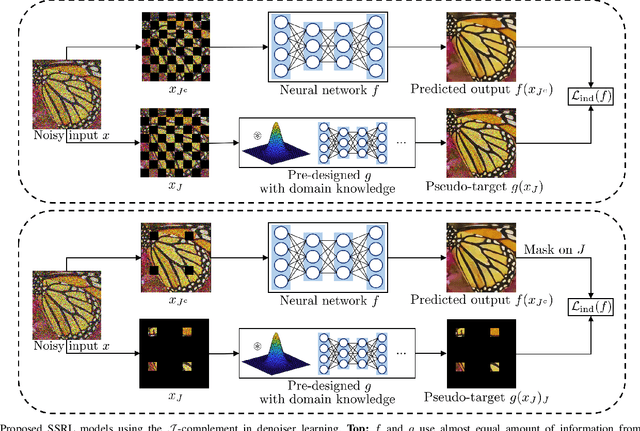
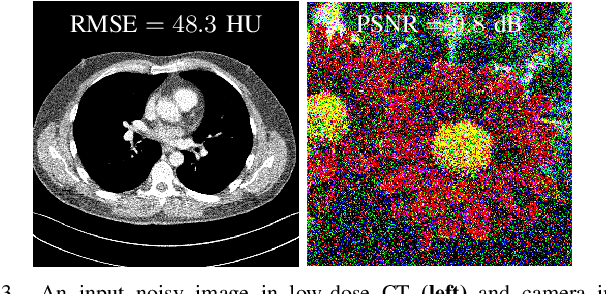
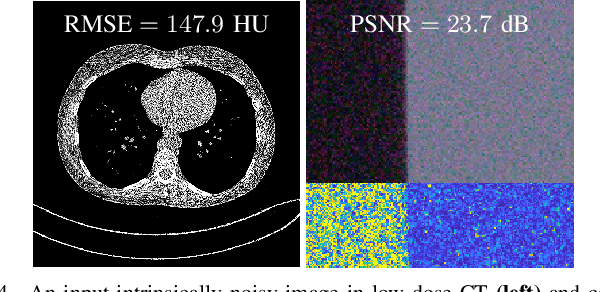
Regression that predicts continuous quantity is a central part of applications using computational imaging and computer vision technologies. Yet, studying and understanding self-supervised learning for regression tasks - except for a particular regression task, image denoising - have lagged behind. This paper proposes a general self-supervised regression learning (SSRL) framework that enables learning regression neural networks with only input data (but without ground-truth target data), by using a designable pseudo-predictor that encapsulates domain knowledge of a specific application. The paper underlines the importance of using domain knowledge by showing that under different settings, the better pseudo-predictor can lead properties of SSRL closer to those of ordinary supervised learning. Numerical experiments for low-dose computational tomography denoising and camera image denoising demonstrate that proposed SSRL significantly improves the denoising quality over several existing self-supervised denoising methods.
Blur More To Deblur Better: Multi-Blur2Deblur For Efficient Video Deblurring
Dec 23, 2020
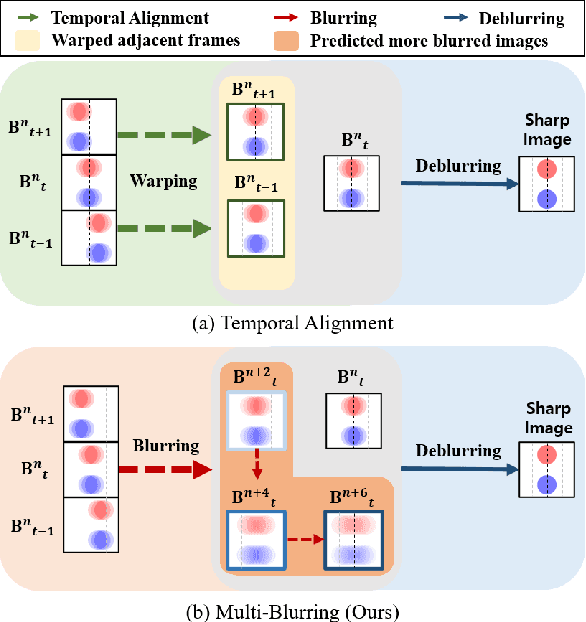
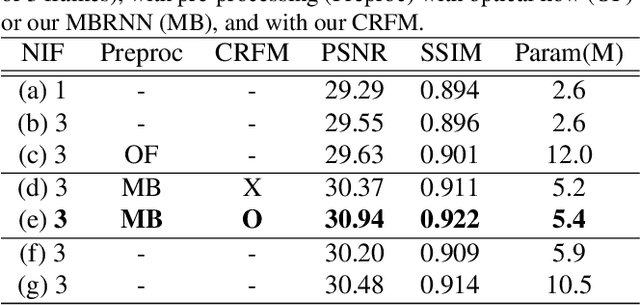

One of the key components for video deblurring is how to exploit neighboring frames. Recent state-of-the-art methods either used aligned adjacent frames to the center frame or propagated the information on past frames to the current frame recurrently. Here we propose multi-blur-to-deblur (MB2D), a novel concept to exploit neighboring frames for efficient video deblurring. Firstly, inspired by unsharp masking, we argue that using more blurred images with long exposures as additional inputs significantly improves performance. Secondly, we propose multi-blurring recurrent neural network (MBRNN) that can synthesize more blurred images from neighboring frames, yielding substantially improved performance with existing video deblurring methods. Lastly, we propose multi-scale deblurring with connecting recurrent feature map from MBRNN (MSDR) to achieve state-of-the-art performance on the popular GoPro and Su datasets in fast and memory efficient ways.
Task-Aware Variational Adversarial Active Learning
Feb 11, 2020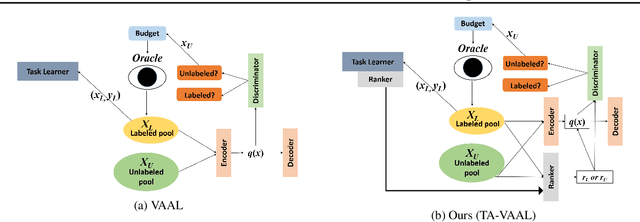
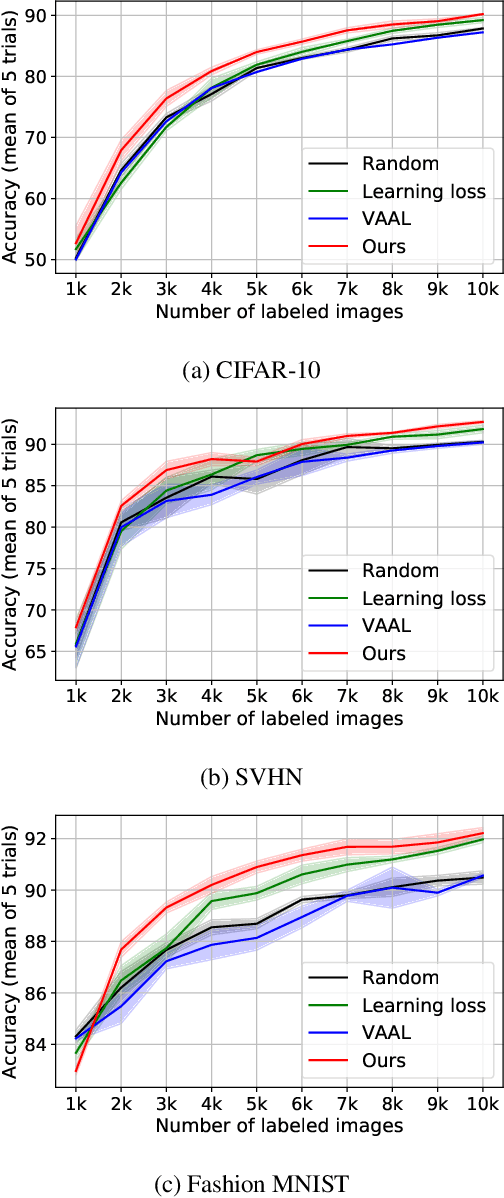
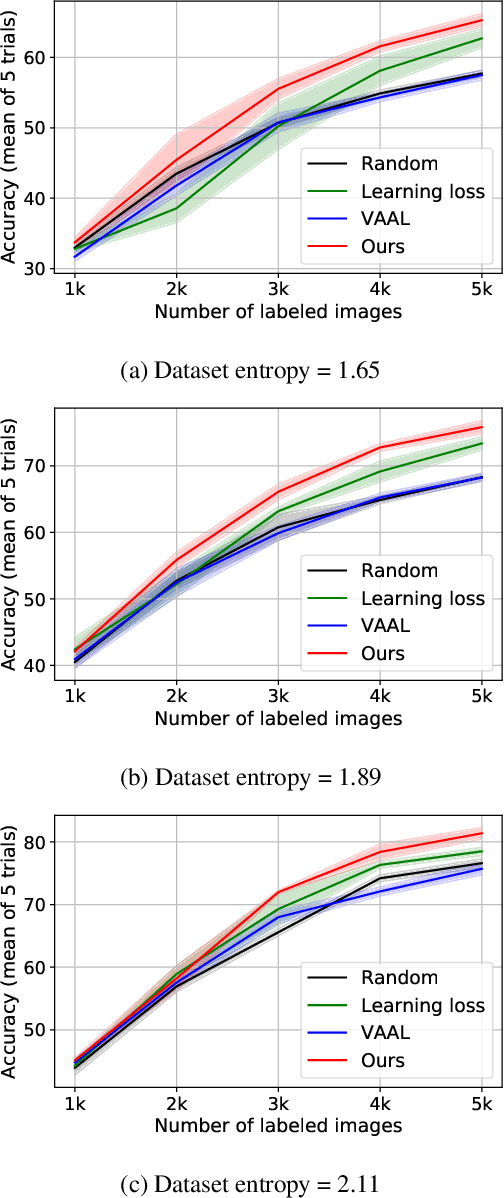
Deep learning has achieved remarkable performance in various tasks thanks to massive labeled datasets. However, there are often cases where labeling large amount of data is challenging or infeasible due to high labeling cost such as labeling by experts or long labeling time per large-scale data sample (e.g., video, very large image). Active learning is one of the ways to query the most informative samples to be annotated among massive unlabeled pool. Two promising directions for active learning that have been recently explored are data distribution-based approach to select data points that are far from current labeled pool and model uncertainty-based approach that relies on the perspective of task model. Unfortunately, the former does not exploit structures from tasks and the latter does not seem to well-utilize overall data distribution. Here, we propose the methods that simultaneously take advantage of both data distribution and model uncertainty approaches. Our proposed methods exploit variational adversarial active learning (VAAL), that considered data distribution of both label and unlabeled pools, by incorporating learning loss prediction module and RankCGAN concept into VAAL by modeling loss prediction as a ranker. We demonstrate that our proposed methods outperform recent state-of-the-art active learning methods on various balanced and imbalanced benchmark datasets.
Multi-Temporal Recurrent Neural Networks For Progressive Non-Uniform Single Image Deblurring With Incremental Temporal Training
Nov 18, 2019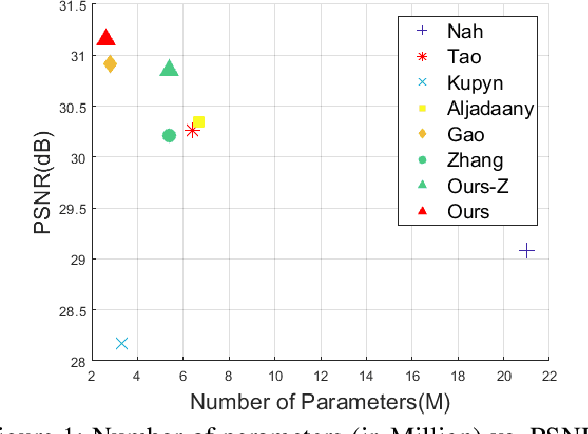

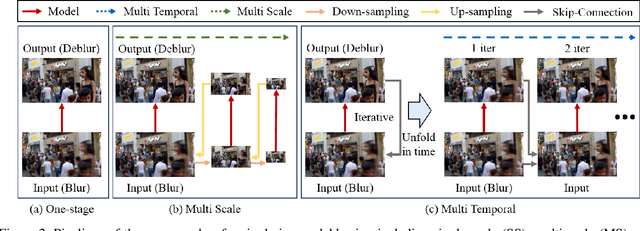
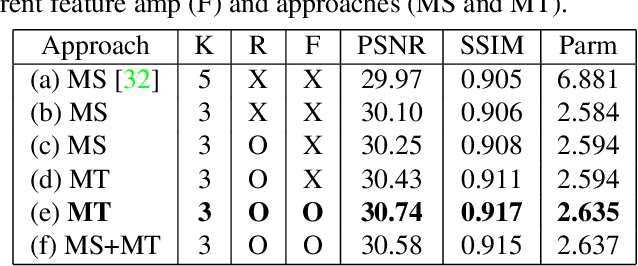
Multi-scale (MS) approaches have been widely investigated for blind single image / video deblurring that sequentially recovers deblurred images in low spatial scale first and then in high spatial scale later with the output of lower scales. MS approaches have been effective especially for severe blurs induced by large motions in high spatial scale since those can be seen as small blurs in low spatial scale. In this work, we investigate alternative approach to MS, called multi-temporal (MT) approach, for non-uniform single image deblurring. We propose incremental temporal training with constructed MT level dataset from time-resolved dataset, develop novel MT-RNNs with recurrent feature maps, and investigate progressive single image deblurring over iterations. Our proposed MT methods outperform state-of-the-art MS methods on the GoPro dataset in PSNR with the smallest number of parameters.
A Single Multi-Task Deep Neural Network with Post-Processing for Object Detection with Reasoning and Robotic Grasp Detection
Sep 16, 2019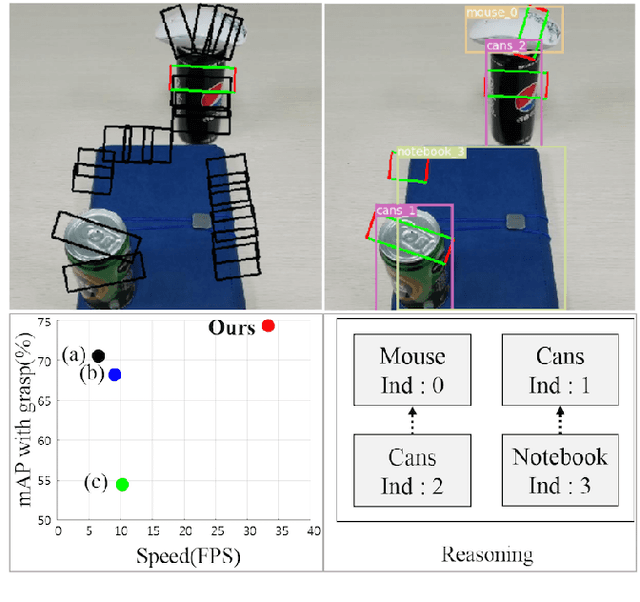
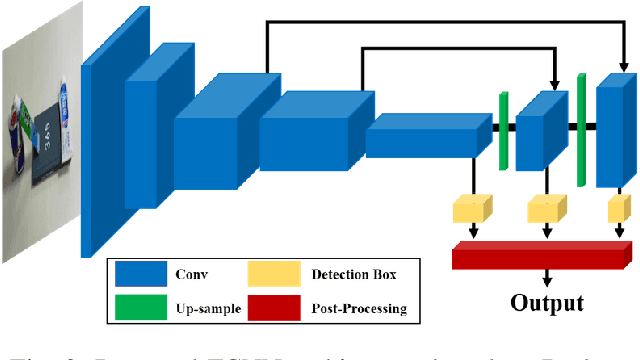
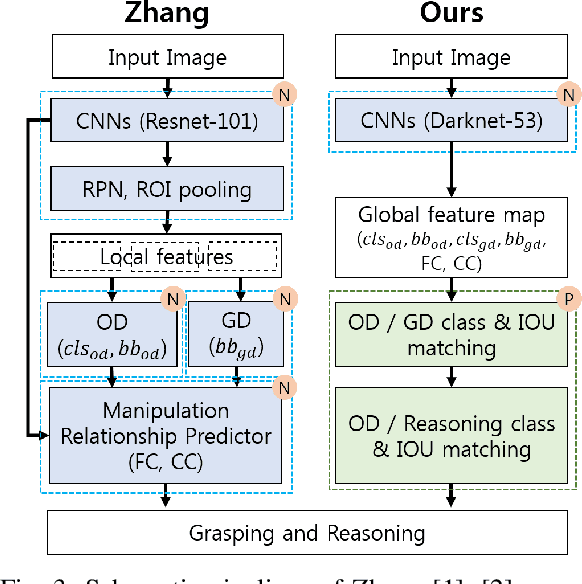
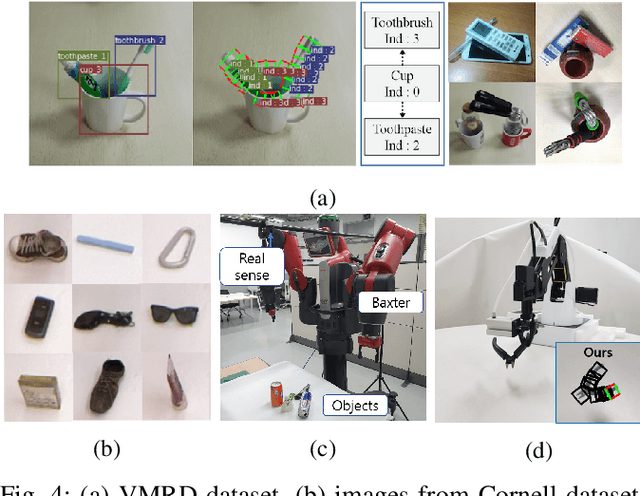
Recently, robotic grasp detection (GD) and object detection (OD) with reasoning have been investigated using deep neural networks (DNNs). There have been works to combine these multi-tasks using separate networks so that robots can deal with situations of grasping specific target objects in the cluttered, stacked, complex piles of novel objects from a single RGB-D camera. We propose a single multi-task DNN that yields the information on GD, OD and relationship reasoning among objects with a simple post-processing. Our proposed methods yielded state-of-the-art performance with the accuracy of 98.6% and 74.2% and the computation speed of 33 and 62 frame per second on VMRD and Cornell datasets, respectively. Our methods also yielded 95.3% grasp success rate for single novel object grasping with a 4-axis robot arm and 86.7% grasp success rate in cluttered novel objects with a Baxter robot.
Down-Scaling with Learned Kernels in Multi-Scale Deep Neural Networks for Non-Uniform Single Image Deblurring
Mar 25, 2019
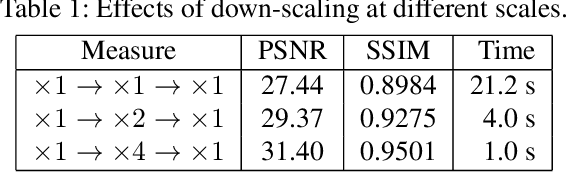


Multi-scale approach has been used for blind image / video deblurring problems to yield excellent performance for both conventional and recent deep-learning-based state-of-the-art methods. Bicubic down-sampling is a typical choice for multi-scale approach to reduce spatial dimension after filtering with a fixed kernel. However, this fixed kernel may be sub-optimal since it may destroy important information for reliable deblurring such as strong edges. We propose convolutional neural network (CNN)-based down-scale methods for multi-scale deep-learning-based non-uniform single image deblurring. We argue that our CNN-based down-scaling effectively reduces the spatial dimension of the original image, while learned kernels with multiple channels may well-preserve necessary details for deblurring tasks. For each scale, we adopt to use RCAN (Residual Channel Attention Networks) as a backbone network to further improve performance. Our proposed method yielded state-of-the-art performance on GoPro dataset by large margin. Our proposed method was able to achieve 2.59dB higher PSNR than the current state-of-the-art method by Tao. Our proposed CNN-based down-scaling was the key factor for this excellent performance since the performance of our network without it was decreased by 1.98dB. The same networks trained with GoPro set were also evaluated on large-scale Su dataset and our proposed method yielded 1.15dB better PSNR than the Tao's method. Qualitative comparisons on Lai dataset also confirmed the superior performance of our proposed method over other state-of-the-art methods.