 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Low-dose CT Image Reconstruction by Integrating Supervised and Unsupervised Learning
Nov 19, 2023



Traditional model-based image reconstruction (MBIR) methods combine forward and noise models with simple object priors. Recent application of deep learning methods for image reconstruction provides a successful data-driven approach to addressing the challenges when reconstructing images with undersampled measurements or various types of noise. In this work, we propose a hybrid supervised-unsupervised learning framework for X-ray computed tomography (CT) image reconstruction. The proposed learning formulation leverages both sparsity or unsupervised learning-based priors and neural network reconstructors to simulate a fixed-point iteration process. Each proposed trained block consists of a deterministic MBIR solver and a neural network. The information flows in parallel through these two reconstructors and is then optimally combined. Multiple such blocks are cascaded to form a reconstruction pipeline. We demonstrate the efficacy of this learned hybrid model for low-dose CT image reconstruction with limited training data, where we use the NIH AAPM Mayo Clinic Low Dose CT Grand Challenge dataset for training and testing. In our experiments, we study combinations of supervised deep network reconstructors and MBIR solver with learned sparse representation-based priors or analytical priors. Our results demonstrate the promising performance of the proposed framework compared to recent low-dose CT reconstruction methods.
Combining Deep Learning and Adaptive Sparse Modeling for Low-dose CT Reconstruction
May 19, 2022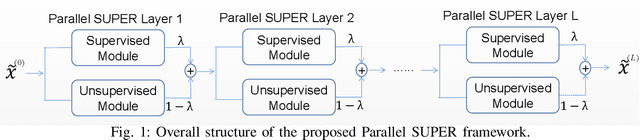
Traditional model-based image reconstruction (MBIR) methods combine forward and noise models with simple object priors. Recent application of deep learning methods for image reconstruction provides a successful data-driven approach to addressing the challenges when reconstructing images with measurement undersampling or various types of noise. In this work, we propose a hybrid supervised-unsupervised learning framework for X-ray computed tomography (CT) image reconstruction. The proposed learning formulation leverages both sparsity or unsupervised learning-based priors and neural network reconstructors to simulate a fixed-point iteration process. Each proposed trained block consists of a deterministic MBIR solver and a neural network. The information flows in parallel through these two reconstructors and is then optimally combined, and multiple such blocks are cascaded to form a reconstruction pipeline. We demonstrate the efficacy of this learned hybrid model for low-dose CT image reconstruction with limited training data, where we use the NIH AAPM Mayo Clinic Low Dose CT Grand Challenge dataset for training and testing. In our experiments, we study combinations of supervised deep network reconstructors and sparse representations-based (unsupervised) learned or analytical priors. Our results demonstrate the promising performance of the proposed framework compared to recent reconstruction methods.
Self-supervised regression learning using domain knowledge: Applications to improving self-supervised denoising in imaging
May 10, 2022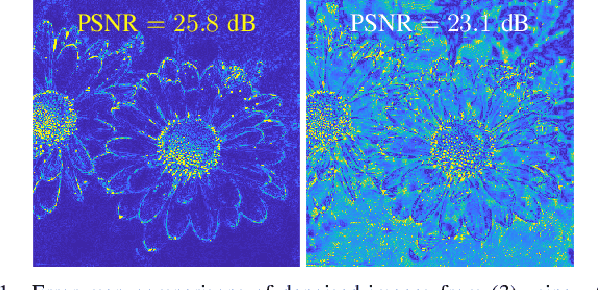
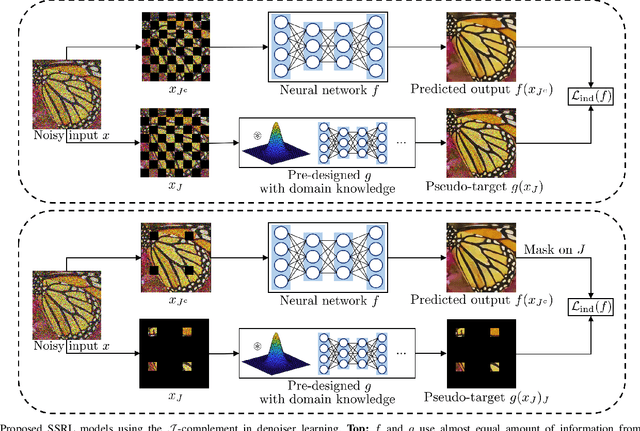
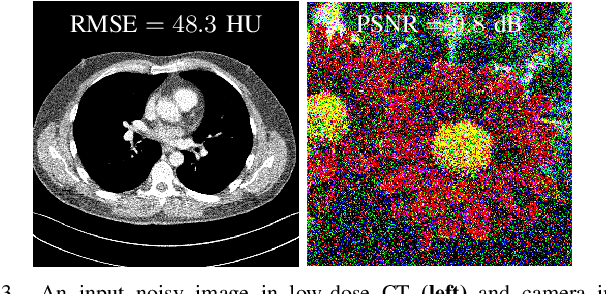
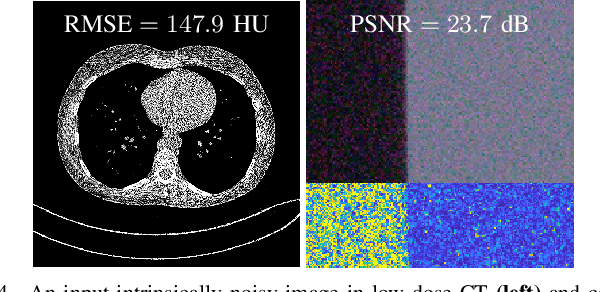
Regression that predicts continuous quantity is a central part of applications using computational imaging and computer vision technologies. Yet, studying and understanding self-supervised learning for regression tasks - except for a particular regression task, image denoising - have lagged behind. This paper proposes a general self-supervised regression learning (SSRL) framework that enables learning regression neural networks with only input data (but without ground-truth target data), by using a designable pseudo-predictor that encapsulates domain knowledge of a specific application. The paper underlines the importance of using domain knowledge by showing that under different settings, the better pseudo-predictor can lead properties of SSRL closer to those of ordinary supervised learning. Numerical experiments for low-dose computational tomography denoising and camera image denoising demonstrate that proposed SSRL significantly improves the denoising quality over several existing self-supervised denoising methods.
Multi-layer Clustering-based Residual Sparsifying Transform for Low-dose CT Image Reconstruction
Mar 22, 2022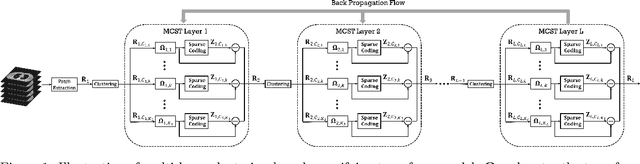

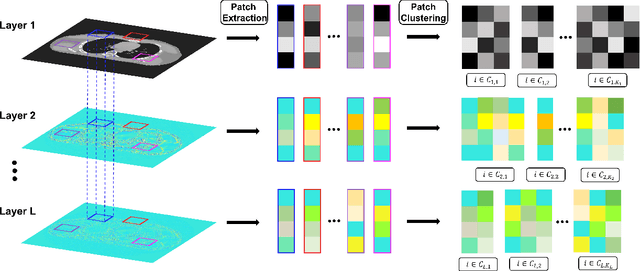
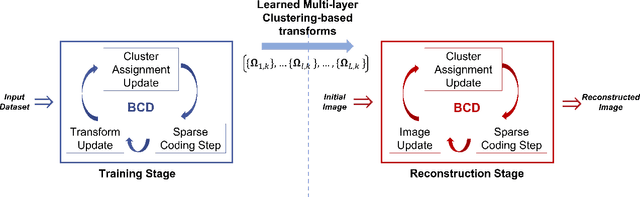
The recently proposed sparsifying transform models incur low computational cost and have been applied to medical imaging. Meanwhile, deep models with nested network structure reveal great potential for learning features in different layers. In this study, we propose a network-structured sparsifying transform learning approach for X-ray computed tomography (CT), which we refer to as multi-layer clustering-based residual sparsifying transform (MCST) learning. The proposed MCST scheme learns multiple different unitary transforms in each layer by dividing each layer's input into several classes. We apply the MCST model to low-dose CT (LDCT) reconstruction by deploying the learned MCST model into the regularizer in penalized weighted least squares (PWLS) reconstruction. We conducted LDCT reconstruction experiments on XCAT phantom data and Mayo Clinic data and trained the MCST model with 2 (or 3) layers and with 5 clusters in each layer. The learned transforms in the same layer showed rich features while additional information is extracted from representation residuals. Our simulation results demonstrate that PWLS-MCST achieves better image reconstruction quality than the conventional FBP method and PWLS with edge-preserving (EP) regularizer. It also outperformed recent advanced methods like PWLS with a learned multi-layer residual sparsifying transform prior (MARS) and PWLS with a union of learned transforms (ULTRA), especially for displaying clear edges and preserving subtle details.
An Improved Iterative Neural Network for High-Quality Image-Domain Material Decomposition in Dual-Energy CT
Dec 02, 2020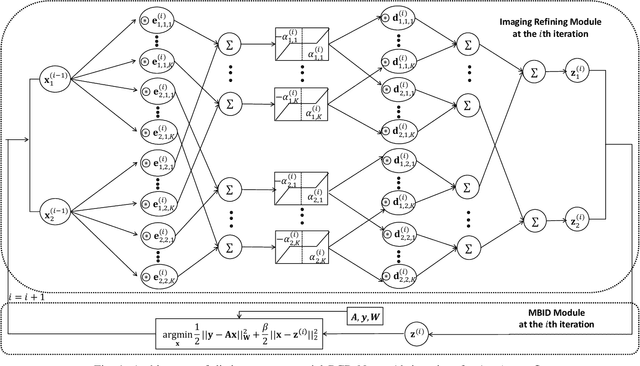
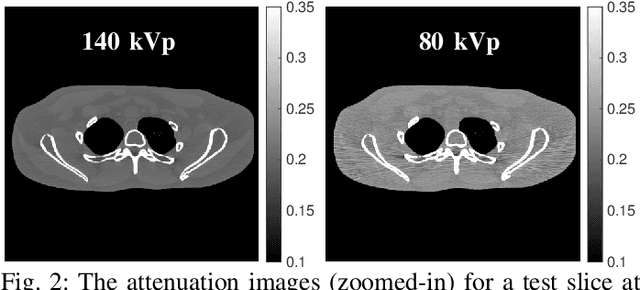
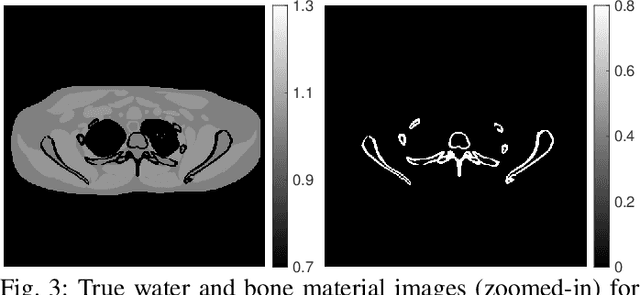
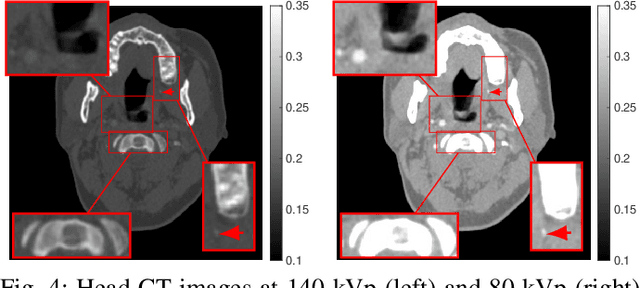
Dual-energy computed tomography (DECT) has been widely used in many applications that need material decomposition. Image-domain methods directly decompose material images from high- and low-energy attenuation images, and thus, are susceptible to noise and artifacts on attenuation images. To obtain high-quality material images, various data-driven methods have been proposed. Iterative neural network (INN) methods combine regression NNs and model-based image reconstruction algorithm. INNs reduced the generalization error of (noniterative) deep regression NNs, and achieved high-quality reconstruction in diverse medical imaging applications. BCD-Net is a recent INN architecture that incorporates imaging refining NNs into the block coordinate descent (BCD) model-based image reconstruction algorithm. We propose a new INN architecture, distinct cross-material BCD-Net, for DECT material decomposition. The proposed INN architecture uses distinct cross-material convolutional neural network (CNN) in image refining modules, and uses image decomposition physics in image reconstruction modules. The distinct cross-material CNN refiners incorporate distinct encoding-decoding filters and cross-material model that captures correlations between different materials. We interpret the distinct cross-material CNN refiner with patch perspective. Numerical experiments with extended cardiactorso (XCAT) phantom and clinical data show that proposed distinct cross-material BCD-Net significantly improves the image quality over several image-domain material decomposition methods, including a conventional model-based image decomposition (MBID) method using an edge-preserving regularizer, a state-of-the-art MBID method using pre-learned material-wise sparsifying transforms, and a noniterative deep CNN denoiser.
Two-layer clustering-based sparsifying transform learning for low-dose CT reconstruction
Nov 01, 2020


Achieving high-quality reconstructions from low-dose computed tomography (LDCT) measurements is of much importance in clinical settings. Model-based image reconstruction methods have been proven to be effective in removing artifacts in LDCT. In this work, we propose an approach to learn a rich two-layer clustering-based sparsifying transform model (MCST2), where image patches and their subsequent feature maps (filter residuals) are clustered into groups with different learned sparsifying filters per group. We investigate a penalized weighted least squares (PWLS) approach for LDCT reconstruction incorporating learned MCST2 priors. Experimental results show the superior performance of the proposed PWLS-MCST2 approach compared to other related recent schemes.
Multi-layer Residual Sparsifying Transform (MARS) Model for Low-dose CT Image Reconstruction
Oct 16, 2020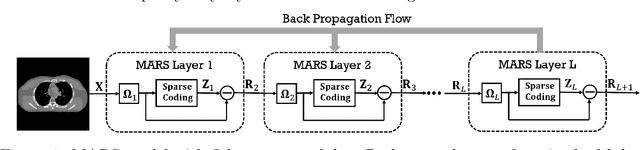



Signal models based on sparse representations have received considerable attention in recent years. On the other hand, deep models consisting of a cascade of functional layers, commonly known as deep neural networks, have been highly successful for the task of object classification and have been recently introduced to image reconstruction. In this work, we develop a new image reconstruction approach based on a novel multi-layer model learned in an unsupervised manner by combining both sparse representations and deep models. The proposed framework extends the classical sparsifying transform model for images to a Multi-lAyer Residual Sparsifying transform (MARS) model, wherein the transform domain data are jointly sparsified over layers. We investigate the application of MARS models learned from limited regular-dose images for low-dose CT reconstruction using Penalized Weighted Least Squares (PWLS) optimization. We propose new formulations for multi-layer transform learning and image reconstruction. We derive an efficient block coordinate descent algorithm to learn the transforms across layers, in an unsupervised manner from limited regular-dose images. The learned model is then incorporated into the low-dose image reconstruction phase. Low-dose CT experimental results with both the XCAT phantom and Mayo Clinic data show that the MARS model outperforms conventional methods such as FBP and PWLS methods based on the edge-preserving (EP) regularizer and the single-layer learned transform (ST) model, especially in terms of reducing noise and maintaining some subtle details.
Learned Multi-layer Residual Sparsifying Transform Model for Low-dose CT Reconstruction
May 08, 2020


Signal models based on sparse representation have received considerable attention in recent years. Compared to synthesis dictionary learning, sparsifying transform learning involves highly efficient sparse coding and operator update steps. In this work, we propose a Multi-layer Residual Sparsifying Transform (MRST) learning model wherein the transform domain residuals are jointly sparsified over layers. In particular, the transforms for the deeper layers exploit the more intricate properties of the residual maps. We investigate the application of the learned MRST model for low-dose CT reconstruction using Penalized Weighted Least Squares (PWLS) optimization. Experimental results on Mayo Clinic data show that the MRST model outperforms conventional methods such as FBP and PWLS methods based on edge-preserving (EP) regularizer and single-layer transform (ST) model, especially for maintaining some subtle details.
Momentum-Net for Low-Dose CT Image Reconstruction
Mar 06, 2020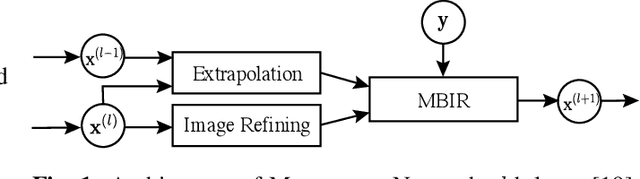

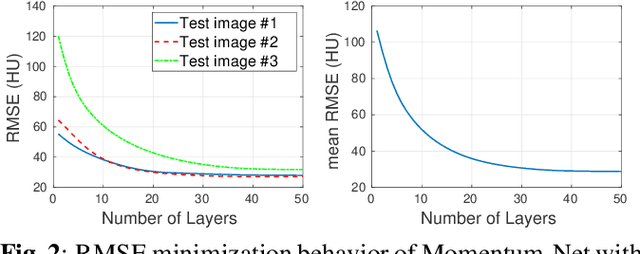
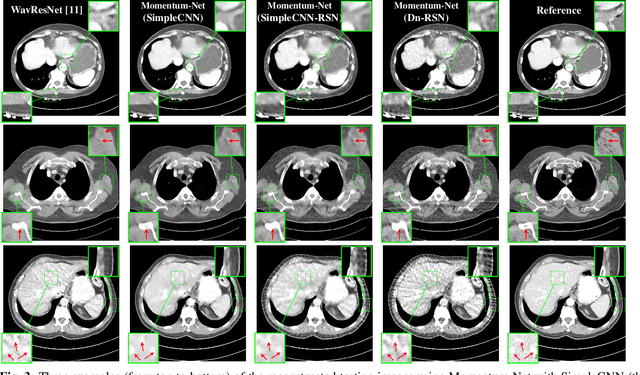
This paper applies the recent fast iterative neural network framework, Momentum-Net, using appropriate models to low-dose X-ray computed tomography (LDCT) image reconstruction. At each layer of the proposed Momentum-Net, the model-based image reconstruction module solves the majorized penalized weighted least-square problem, and the image refining module uses a four-layer convolutional autoencoder. Experimental results with the NIH AAPM-Mayo Clinic Low Dose CT Grand Challenge dataset show that the proposed Momentum-Net architecture significantly improves image reconstruction accuracy, compared to a state-of-the-art noniterative image denoising deep neural network (NN), WavResNet (in LDCT). We also investigated the spectral normalization technique that applies to image refining NN learning to satisfy the nonexpansive NN property; however, experimental results show that this does not improve the image reconstruction performance of Momentum-Net.
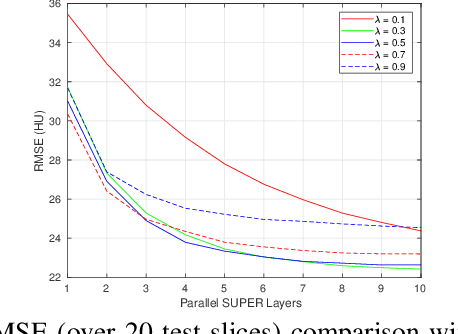
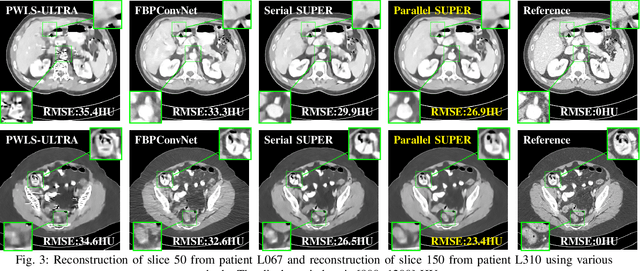
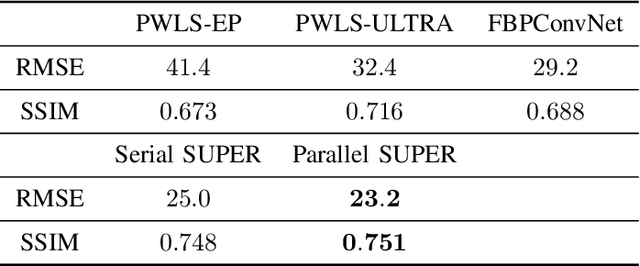
SUPER Learning: A Supervised-Unsupervised Framework for Low-Dose CT Image Reconstruction
Oct 26, 2019

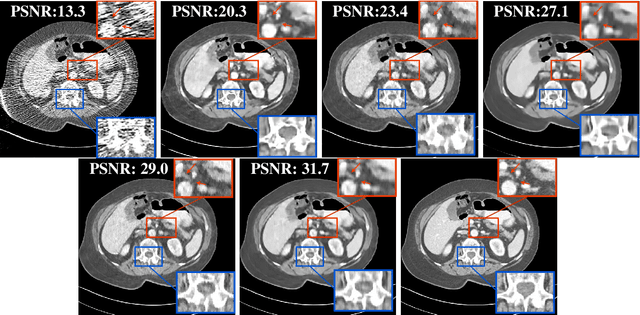
Recent years have witnessed growing interest in machine learning-based models and techniques for low-dose X-ray CT (LDCT) imaging tasks. The methods can typically be categorized into supervised learning methods and unsupervised or model-based learning methods. Supervised learning methods have recently shown success in image restoration tasks. However, they often rely on large training sets. Model-based learning methods such as dictionary or transform learning do not require large or paired training sets and often have good generalization properties, since they learn general properties of CT image sets. Recent works have shown the promising reconstruction performance of methods such as PWLS-ULTRA that rely on clustering the underlying (reconstructed) image patches into a learned union of transforms. In this paper, we propose a new Supervised-UnsuPERvised (SUPER) reconstruction framework for LDCT image reconstruction that combines the benefits of supervised learning methods and (unsupervised) transform learning-based methods such as PWLS-ULTRA that involve highly image-adaptive clustering. The SUPER model consists of several layers, each of which includes a deep network learned in a supervised manner and an unsupervised iterative method that involves image-adaptive components. The SUPER reconstruction algorithms are learned in a greedy manner from training data. The proposed SUPER learning methods dramatically outperform both the constituent supervised learning-based networks and iterative algorithms for LDCT, and use much fewer iterations in the iterative reconstruction modules.