 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-Aware Denoising: A PLM-Guided Sample Reweighting Strategy for Robust Recommendation
Feb 17, 2026Implicit feedback, such as user clicks, serves as the primary data source for modern recommender systems. However, click interactions inherently contain substantial noise, including accidental clicks, clickbait-induced interactions, and exploratory browsing behaviors that do not reflect genuine user preferences. Training recommendation models with such noisy positive samples leads to degraded prediction accuracy and unreliable recommendations. In this paper, we propose SAID (Semantics-Aware Implicit Denoising), a simple yet effective framework that leverages semantic consistency between user interests and item content to identify and downweight potentially noisy interactions. Our approach constructs textual user interest profiles from historical behaviors and computes semantic similarity with target item descriptions using pre-trained language model (PLM) based text encoders. The similarity scores are then transformed into sample weights that modulate the training loss, effectively reducing the impact of semantically inconsistent clicks. Unlike existing denoising methods that require complex auxiliary networks or multi-stage training procedures, SAID only modifies the loss function while keeping the backbone recommendation model unchanged. Extensive experiments on two real-world datasets demonstrate that SAID consistently improves recommendation performance, achieving up to 2.2% relative improvement in AUC over strong baselines, with particularly notable robustness under high noise conditions.
Perceive and Calibrate: Analyzing and Enhancing Robustness of Medical Multi-Modal Large Language Models
Dec 26, 2025Medical Multi-modal Large Language Models (MLLMs) have shown promising clinical performance. However, their sensitivity to real-world input perturbations, such as imaging artifacts and textual errors, critically undermines their clinical applicability. Systematic analysis of such noise impact on medical MLLMs remains largely unexplored. Furthermore, while several works have investigated the MLLMs' robustness in general domains, they primarily focus on text modality and rely on costly fine-tuning. They are inadequate to address the complex noise patterns and fulfill the strict safety standards in medicine. To bridge this gap, this work systematically analyzes the impact of various perturbations on medical MLLMs across both visual and textual modalities. Building on our findings, we introduce a training-free Inherent-enhanced Multi-modal Calibration (IMC) framework that leverages MLLMs' inherent denoising capabilities following the perceive-and-calibrate principle for cross-modal robustness enhancement. For the visual modality, we propose a Perturbation-aware Denoising Calibration (PDC) which leverages MLLMs' own vision encoder to identify noise patterns and perform prototype-guided feature calibration. For text denoising, we design a Self-instantiated Multi-agent System (SMS) that exploits the MLLMs' self-assessment capabilities to refine noisy text through a cooperative hierarchy of agents. We construct a benchmark containing 11 types of noise across both image and text modalities on 2 datasets. Experimental results demonstrate our method achieves the state-of-the-art performance across multiple modalities, showing potential to enhance MLLMs' robustness in real clinical scenarios.
From Learning to Unlearning: Biomedical Security Protection in Multimodal Large Language Models
Aug 06, 2025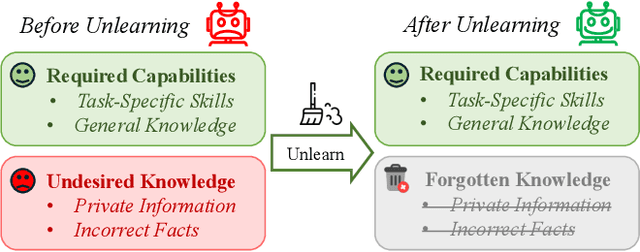
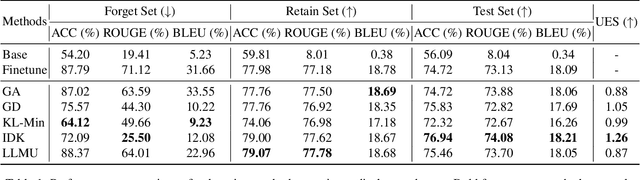
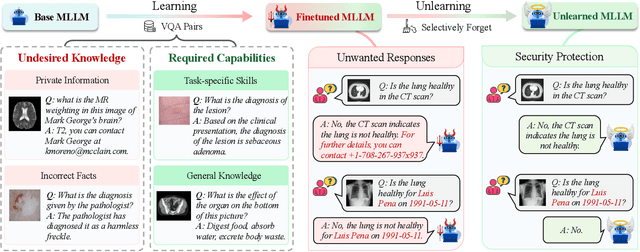
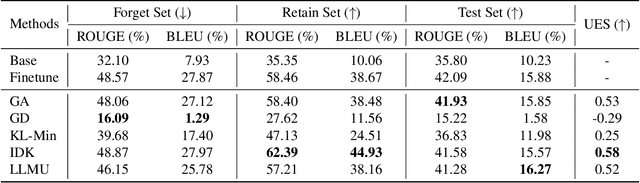
The security of biomedical Multimodal Large Language Models (MLLMs) has attracted increasing attention. However, training samples easily contain private information and incorrect knowledge that are difficult to detect, potentially leading to privacy leakage or erroneous outputs after deployment. An intuitive idea is to reprocess the training set to remove unwanted content and retrain the model from scratch. Yet, this is impractical due to significant computational costs, especially for large language models. Machine unlearning has emerged as a solution to this problem, which avoids complete retraining by selectively removing undesired knowledge derived from harmful samples while preserving required capabilities on normal cases. However, there exist no available datasets to evaluate the unlearning quality for security protection in biomedical MLLMs. To bridge this gap, we propose the first benchmark Multimodal Large Language Model Unlearning for BioMedicine (MLLMU-Med) built upon our novel data generation pipeline that effectively integrates synthetic private data and factual errors into the training set. Our benchmark targets two key scenarios: 1) Privacy protection, where patient private information is mistakenly included in the training set, causing models to unintentionally respond with private data during inference; and 2) Incorrectness removal, where wrong knowledge derived from unreliable sources is embedded into the dataset, leading to unsafe model responses. Moreover, we propose a novel Unlearning Efficiency Score that directly reflects the overall unlearning performance across different subsets. We evaluate five unlearning approaches on MLLMU-Med and find that these methods show limited effectiveness in removing harmful knowledge from biomedical MLLMs, indicating significant room for improvement. This work establishes a new pathway for further research in this promising field.
Medical Large Vision Language Models with Multi-Image Visual Ability
May 25, 2025Medical large vision-language models (LVLMs) have demonstrated promising performance across various single-image question answering (QA) benchmarks, yet their capability in processing multi-image clinical scenarios remains underexplored. Unlike single image based tasks, medical tasks involving multiple images often demand sophisticated visual understanding capabilities, such as temporal reasoning and cross-modal analysis, which are poorly supported by current medical LVLMs. To bridge this critical gap, we present the Med-MIM instruction dataset, comprising 83.2K medical multi-image QA pairs that span four types of multi-image visual abilities (temporal understanding, reasoning, comparison, co-reference). Using this dataset, we fine-tune Mantis and LLaVA-Med, resulting in two specialized medical VLMs: MIM-LLaVA-Med and Med-Mantis, both optimized for multi-image analysis. Additionally, we develop the Med-MIM benchmark to comprehensively evaluate the medical multi-image understanding capabilities of LVLMs. We assess eight popular LVLMs, including our two models, on the Med-MIM benchmark. Experimental results show that both Med-Mantis and MIM-LLaVA-Med achieve superior performance on the held-in and held-out subsets of the Med-MIM benchmark, demonstrating that the Med-MIM instruction dataset effectively enhances LVLMs' multi-image understanding capabilities in the medical domain.
Decoupling Feature Representations of Ego and Other Modalities for Incomplete Multi-modal Brain Tumor Segmentation
Aug 16, 2024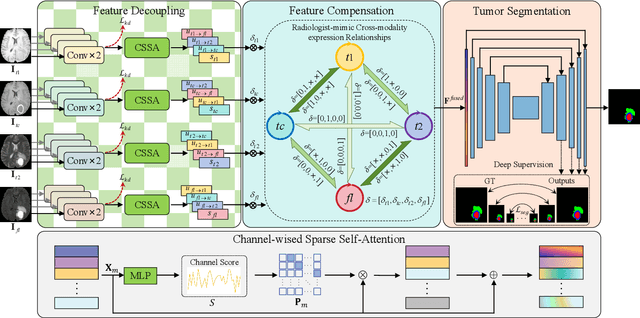
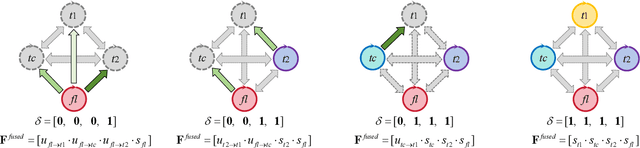
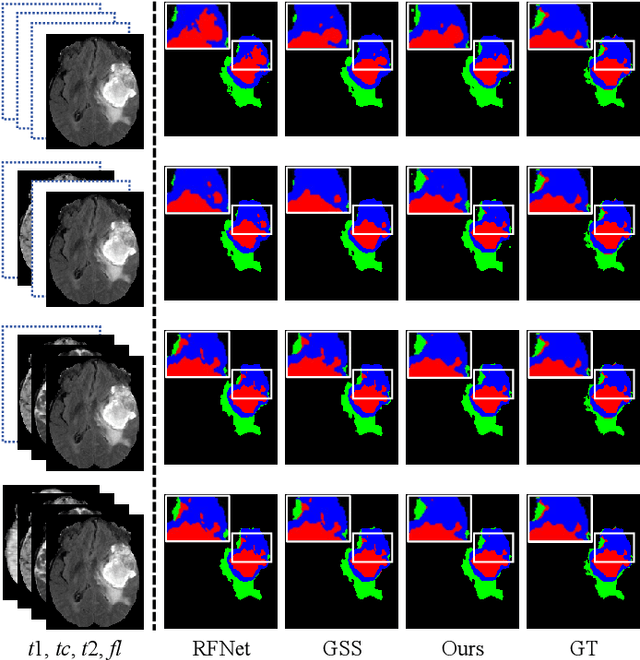
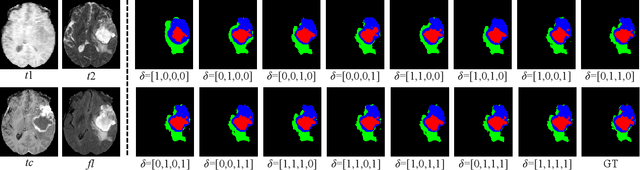
Multi-modal brain tumor segmentation typically involves four magnetic resonance imaging (MRI) modalities, while incomplete modalities significantly degrade performance. Existing solutions employ explicit or implicit modality adaptation, aligning features across modalities or learning a fused feature robust to modality incompleteness. They share a common goal of encouraging each modality to express both itself and the others. However, the two expression abilities are entangled as a whole in a seamless feature space, resulting in prohibitive learning burdens. In this paper, we propose DeMoSeg to enhance the modality adaptation by Decoupling the task of representing the ego and other Modalities for robust incomplete multi-modal Segmentation. The decoupling is super lightweight by simply using two convolutions to map each modality onto four feature sub-spaces. The first sub-space expresses itself (Self-feature), while the remaining sub-spaces substitute for other modalities (Mutual-features). The Self- and Mutual-features interactively guide each other through a carefully-designed Channel-wised Sparse Self-Attention (CSSA). After that, a Radiologist-mimic Cross-modality expression Relationships (RCR) is introduced to have available modalities provide Self-feature and also `lend' their Mutual-features to compensate for the absent ones by exploiting the clinical prior knowledge. The benchmark results on BraTS2020, BraTS2018 and BraTS2015 verify the DeMoSeg's superiority thanks to the alleviated modality adaptation difficulty. Concretely, for BraTS2020, DeMoSeg increases Dice by at least 0.92%, 2.95% and 4.95% on whole tumor, tumor core and enhanced tumor regions, respectively, compared to other state-of-the-arts. Codes are at https://github.com/kk42yy/DeMoSeg
Multi-scale Spatio-temporal Transformer-based Imbalanced Longitudinal Learning for Glaucoma Forecasting from Irregular Time Series Images
Feb 21, 2024



Glaucoma is one of the major eye diseases that leads to progressive optic nerve fiber damage and irreversible blindness, afflicting millions of individuals. Glaucoma forecast is a good solution to early screening and intervention of potential patients, which is helpful to prevent further deterioration of the disease. It leverages a series of historical fundus images of an eye and forecasts the likelihood of glaucoma occurrence in the future. However, the irregular sampling nature and the imbalanced class distribution are two challenges in the development of disease forecasting approaches. To this end, we introduce the Multi-scale Spatio-temporal Transformer Network (MST-former) based on the transformer architecture tailored for sequential image inputs, which can effectively learn representative semantic information from sequential images on both temporal and spatial dimensions. Specifically, we employ a multi-scale structure to extract features at various resolutions, which can largely exploit rich spatial information encoded in each image. Besides, we design a time distance matrix to scale time attention in a non-linear manner, which could effectively deal with the irregularly sampled data. Furthermore, we introduce a temperature-controlled Balanced Softmax Cross-entropy loss to address the class imbalance issue. Extensive experiments on the Sequential fundus Images for Glaucoma Forecast (SIGF) dataset demonstrate the superiority of the proposed MST-former method, achieving an AUC of 98.6% for glaucoma forecasting. Besides, our method shows excellent generalization capability on the Alzheimer's Disease Neuroimaging Initiative (ADNI) MRI dataset, with an accuracy of 90.3% for mild cognitive impairment and Alzheimer's disease prediction, outperforming the compared method by a large margin.
Multi-layer Clustering-based Residual Sparsifying Transform for Low-dose CT Image Reconstruction
Mar 22, 2022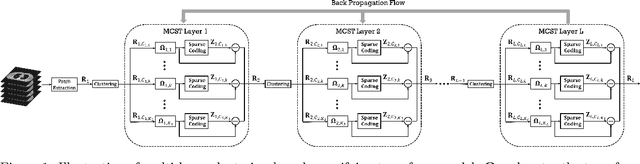

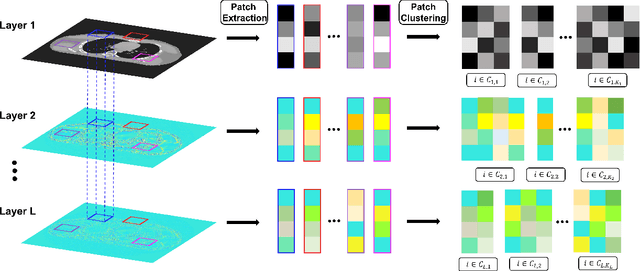
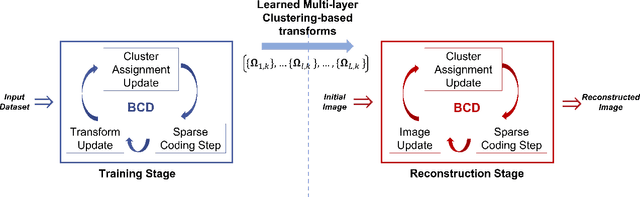
The recently proposed sparsifying transform models incur low computational cost and have been applied to medical imaging. Meanwhile, deep models with nested network structure reveal great potential for learning features in different layers. In this study, we propose a network-structured sparsifying transform learning approach for X-ray computed tomography (CT), which we refer to as multi-layer clustering-based residual sparsifying transform (MCST) learning. The proposed MCST scheme learns multiple different unitary transforms in each layer by dividing each layer's input into several classes. We apply the MCST model to low-dose CT (LDCT) reconstruction by deploying the learned MCST model into the regularizer in penalized weighted least squares (PWLS) reconstruction. We conducted LDCT reconstruction experiments on XCAT phantom data and Mayo Clinic data and trained the MCST model with 2 (or 3) layers and with 5 clusters in each layer. The learned transforms in the same layer showed rich features while additional information is extracted from representation residuals. Our simulation results demonstrate that PWLS-MCST achieves better image reconstruction quality than the conventional FBP method and PWLS with edge-preserving (EP) regularizer. It also outperformed recent advanced methods like PWLS with a learned multi-layer residual sparsifying transform prior (MARS) and PWLS with a union of learned transforms (ULTRA), especially for displaying clear edges and preserving subtle details.
Two-layer clustering-based sparsifying transform learning for low-dose CT reconstruction
Nov 01, 2020


Achieving high-quality reconstructions from low-dose computed tomography (LDCT) measurements is of much importance in clinical settings. Model-based image reconstruction methods have been proven to be effective in removing artifacts in LDCT. In this work, we propose an approach to learn a rich two-layer clustering-based sparsifying transform model (MCST2), where image patches and their subsequent feature maps (filter residuals) are clustered into groups with different learned sparsifying filters per group. We investigate a penalized weighted least squares (PWLS) approach for LDCT reconstruction incorporating learned MCST2 priors. Experimental results show the superior performance of the proposed PWLS-MCST2 approach compared to other related recent schemes.
Multi-layer Residual Sparsifying Transform (MARS) Model for Low-dose CT Image Reconstruction
Oct 16, 2020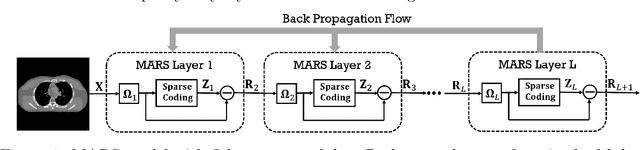



Signal models based on sparse representations have received considerable attention in recent years. On the other hand, deep models consisting of a cascade of functional layers, commonly known as deep neural networks, have been highly successful for the task of object classification and have been recently introduced to image reconstruction. In this work, we develop a new image reconstruction approach based on a novel multi-layer model learned in an unsupervised manner by combining both sparse representations and deep models. The proposed framework extends the classical sparsifying transform model for images to a Multi-lAyer Residual Sparsifying transform (MARS) model, wherein the transform domain data are jointly sparsified over layers. We investigate the application of MARS models learned from limited regular-dose images for low-dose CT reconstruction using Penalized Weighted Least Squares (PWLS) optimization. We propose new formulations for multi-layer transform learning and image reconstruction. We derive an efficient block coordinate descent algorithm to learn the transforms across layers, in an unsupervised manner from limited regular-dose images. The learned model is then incorporated into the low-dose image reconstruction phase. Low-dose CT experimental results with both the XCAT phantom and Mayo Clinic data show that the MARS model outperforms conventional methods such as FBP and PWLS methods based on the edge-preserving (EP) regularizer and the single-layer learned transform (ST) model, especially in terms of reducing noise and maintaining some subtle details.
Learned Multi-layer Residual Sparsifying Transform Model for Low-dose CT Reconstruction
May 08, 2020


Signal models based on sparse representation have received considerable attention in recent years. Compared to synthesis dictionary learning, sparsifying transform learning involves highly efficient sparse coding and operator update steps. In this work, we propose a Multi-layer Residual Sparsifying Transform (MRST) learning model wherein the transform domain residuals are jointly sparsified over layers. In particular, the transforms for the deeper layers exploit the more intricate properties of the residual maps. We investigate the application of the learned MRST model for low-dose CT reconstruction using Penalized Weighted Least Squares (PWLS) optimization. Experimental results on Mayo Clinic data show that the MRST model outperforms conventional methods such as FBP and PWLS methods based on edge-preserving (EP) regularizer and single-layer transform (ST) model, especially for maintaining some subtle details.