 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary Contrast: Modeling Continuous Skeleton Action Spaces with Transitional Anchors
Apr 20, 2026Self-supervised contrastive learning has emerged as a powerful paradigm for skeleton-based action recognition by enforcing consistency in the embedding space. However, existing methods rely on binary contrastive objectives that overlook the intrinsic continuity of human motion, resulting in fragmented feature clusters and rigid class boundaries. To address these limitations, we propose TranCLR, a Transitional anchor-based Contrastive Learning framework that captures the continuous geometry of the action space. Specifically, the proposed Action Transitional Anchor Construction (ATAC) explicitly models the geometric structure of transitional states to enhance the model's perception of motion continuity. Building upon these anchors, a Multi-Level Geometric Manifold Calibration (MGMC) mechanism is introduced to adaptively calibrate the action manifold across multiple levels of continuity, yielding a smoother and more discriminative representation space. Extensive experiments on the NTU RGB+D, NTU RGB+D 120 and PKU-MMD datasets demonstrate that TranCLR achieves superior accuracy and calibration performance, effectively learning continuous and uncertainty-aware skeleton representations. The code is available at https://github.com/Philchieh/TranCLR.
GATS: Gaussian Aware Temporal Scaling Transformer for Invariant 4D Spatio-Temporal Point Cloud Representation
Mar 17, 2026Understanding 4D point cloud videos is essential for enabling intelligent agents to perceive dynamic environments. However, temporal scale bias across varying frame rates and distributional uncertainty in irregular point clouds make it highly challenging to design a unified and robust 4D backbone. Existing CNN or Transformer based methods are constrained either by limited receptive fields or by quadratic computational complexity, while neglecting these implicit distortions. To address this problem, we propose a novel dual invariant framework, termed \textbf{Gaussian Aware Temporal Scaling (GATS)}, which explicitly resolves both distributional inconsistencies and temporal. The proposed \emph{Uncertainty Guided Gaussian Convolution (UGGC)} incorporates local Gaussian statistics and uncertainty aware gating into point convolution, thereby achieving robust neighborhood aggregation under density variation, noise, and occlusion. In parallel, the \emph{Temporal Scaling Attention (TSA)} introduces a learnable scaling factor to normalize temporal distances, ensuring frame partition invariance and consistent velocity estimation across different frame rates. These two modules are complementary: temporal scaling normalizes time intervals prior to Gaussian estimation, while Gaussian modeling enhances robustness to irregular distributions. Our experiments on mainstream benchmarks MSR-Action3D (\textbf{+6.62\%} accuracy), NTU RGBD (\textbf{+1.4\%} accuracy), and Synthia4D (\textbf{+1.8\%} mIoU) demonstrate significant performance gains, offering a more efficient and principled paradigm for invariant 4D point cloud video understanding with superior accuracy, robustness, and scalability compared to Transformer based counterparts.
Aortic Valve Disease Detection from PPG via Physiology-Informed Self-Supervised Learning
Feb 04, 2026Traditional diagnosis of aortic valve disease relies on echocardiography, but its cost and required expertise limit its use in large-scale early screening. Photoplethysmography (PPG) has emerged as a promising screening modality due to its widespread availability in wearable devices and its ability to reflect underlying hemodynamic dynamics. However, the extreme scarcity of gold-standard labeled PPG data severely constrains the effectiveness of data-driven approaches. To address this challenge, we propose and validate a new paradigm, Physiology-Guided Self-Supervised Learning (PG-SSL), aimed at unlocking the value of large-scale unlabeled PPG data for efficient screening of Aortic Stenosis (AS) and Aortic Regurgitation (AR). Using over 170,000 unlabeled PPG samples from the UK Biobank, we formalize clinical knowledge into a set of PPG morphological phenotypes and construct a pulse pattern recognition proxy task for self-supervised pre-training. A dual-branch, gated-fusion architecture is then employed for efficient fine-tuning on a small labeled subset. The proposed PG-SSL framework achieves AUCs of 0.765 and 0.776 for AS and AR screening, respectively, significantly outperforming supervised baselines trained on limited labeled data. Multivariable analysis further validates the model output as an independent digital biomarker with sustained prognostic value after adjustment for standard clinical risk factors. This study demonstrates that PG-SSL provides an effective, domain knowledge-driven solution to label scarcity in medical artificial intelligence and shows strong potential for enabling low-cost, large-scale early screening of aortic valve disease.
SceneDecorator: Towards Scene-Oriented Story Generation with Scene Planning and Scene Consistency
Oct 27, 2025Recent text-to-image models have revolutionized image generation, but they still struggle with maintaining concept consistency across generated images. While existing works focus on character consistency, they often overlook the crucial role of scenes in storytelling, which restricts their creativity in practice. This paper introduces scene-oriented story generation, addressing two key challenges: (i) scene planning, where current methods fail to ensure scene-level narrative coherence by relying solely on text descriptions, and (ii) scene consistency, which remains largely unexplored in terms of maintaining scene consistency across multiple stories. We propose SceneDecorator, a training-free framework that employs VLM-Guided Scene Planning to ensure narrative coherence across different scenes in a ``global-to-local'' manner, and Long-Term Scene-Sharing Attention to maintain long-term scene consistency and subject diversity across generated stories. Extensive experiments demonstrate the superior performance of SceneDecorator, highlighting its potential to unleash creativity in the fields of arts, films, and games.
UniView: Enhancing Novel View Synthesis From A Single Image By Unifying Reference Features
Sep 05, 2025The task of synthesizing novel views from a single image is highly ill-posed due to multiple explanations for unobserved areas. Most current methods tend to generate unseen regions from ambiguity priors and interpolation near input views, which often lead to severe distortions. To address this limitation, we propose a novel model dubbed as UniView, which can leverage reference images from a similar object to provide strong prior information during view synthesis. More specifically, we construct a retrieval and augmentation system and employ a multimodal large language model (MLLM) to assist in selecting reference images that meet our requirements. Additionally, a plug-and-play adapter module with multi-level isolation layers is introduced to dynamically generate reference features for the target views. Moreover, in order to preserve the details of an original input image, we design a decoupled triple attention mechanism, which can effectively align and integrate multi-branch features into the synthesis process. Extensive experiments have demonstrated that our UniView significantly improves novel view synthesis performance and outperforms state-of-the-art methods on the challenging datasets.
Medical Large Vision Language Models with Multi-Image Visual Ability
May 25, 2025Medical large vision-language models (LVLMs) have demonstrated promising performance across various single-image question answering (QA) benchmarks, yet their capability in processing multi-image clinical scenarios remains underexplored. Unlike single image based tasks, medical tasks involving multiple images often demand sophisticated visual understanding capabilities, such as temporal reasoning and cross-modal analysis, which are poorly supported by current medical LVLMs. To bridge this critical gap, we present the Med-MIM instruction dataset, comprising 83.2K medical multi-image QA pairs that span four types of multi-image visual abilities (temporal understanding, reasoning, comparison, co-reference). Using this dataset, we fine-tune Mantis and LLaVA-Med, resulting in two specialized medical VLMs: MIM-LLaVA-Med and Med-Mantis, both optimized for multi-image analysis. Additionally, we develop the Med-MIM benchmark to comprehensively evaluate the medical multi-image understanding capabilities of LVLMs. We assess eight popular LVLMs, including our two models, on the Med-MIM benchmark. Experimental results show that both Med-Mantis and MIM-LLaVA-Med achieve superior performance on the held-in and held-out subsets of the Med-MIM benchmark, demonstrating that the Med-MIM instruction dataset effectively enhances LVLMs' multi-image understanding capabilities in the medical domain.
SciVerse: Unveiling the Knowledge Comprehension and Visual Reasoning of LMMs on Multi-modal Scientific Problems
Mar 13, 2025The rapid advancement of Large Multi-modal Models (LMMs) has enabled their application in scientific problem-solving, yet their fine-grained capabilities remain under-explored. In this paper, we introduce SciVerse, a multi-modal scientific evaluation benchmark to thoroughly assess LMMs across 5,735 test instances in five distinct versions. We aim to investigate three key dimensions of LMMs: scientific knowledge comprehension, multi-modal content interpretation, and Chain-of-Thought (CoT) reasoning. To unveil whether LMMs possess sufficient scientific expertise, we first transform each problem into three versions containing different levels of knowledge required for solving, i.e., Knowledge-free, -lite, and -rich. Then, to explore how LMMs interpret multi-modal scientific content, we annotate another two versions, i.e., Vision-rich and -only, marking more question information from texts to diagrams. Comparing the results of different versions, SciVerse systematically examines the professional knowledge stock and visual perception skills of LMMs in scientific domains. In addition, to rigorously assess CoT reasoning, we propose a new scientific CoT evaluation strategy, conducting a step-wise assessment on knowledge and logical errors in model outputs. Our extensive evaluation of different LMMs on SciVerse reveals critical limitations in their scientific proficiency and provides new insights into future developments. Project page: https://sciverse-cuhk.github.io
Point Cloud Understanding via Attention-Driven Contrastive Learning
Nov 22, 2024



Recently Transformer-based models have advanced point cloud understanding by leveraging self-attention mechanisms, however, these methods often overlook latent information in less prominent regions, leading to increased sensitivity to perturbations and limited global comprehension. To solve this issue, we introduce PointACL, an attention-driven contrastive learning framework designed to address these limitations. Our method employs an attention-driven dynamic masking strategy that guides the model to focus on under-attended regions, enhancing the understanding of global structures within the point cloud. Then we combine the original pre-training loss with a contrastive learning loss, improving feature discrimination and generalization. Extensive experiments validate the effectiveness of PointACL, as it achieves state-of-the-art performance across a variety of 3D understanding tasks, including object classification, part segmentation, and few-shot learning. Specifically, when integrated with different Transformer backbones like Point-MAE and PointGPT, PointACL demonstrates improved performance on datasets such as ScanObjectNN, ModelNet40, and ShapeNetPart. This highlights its superior capability in capturing both global and local features, as well as its enhanced robustness against perturbations and incomplete data.
MagicTailor: Component-Controllable Personalization in Text-to-Image Diffusion Models
Oct 17, 2024Recent advancements in text-to-image (T2I) diffusion models have enabled the creation of high-quality images from text prompts, but they still struggle to generate images with precise control over specific visual concepts. Existing approaches can replicate a given concept by learning from reference images, yet they lack the flexibility for fine-grained customization of the individual component within the concept. In this paper, we introduce component-controllable personalization, a novel task that pushes the boundaries of T2I models by allowing users to reconfigure specific components when personalizing visual concepts. This task is particularly challenging due to two primary obstacles: semantic pollution, where unwanted visual elements corrupt the personalized concept, and semantic imbalance, which causes disproportionate learning of the concept and component. To overcome these challenges, we design MagicTailor, an innovative framework that leverages Dynamic Masked Degradation (DM-Deg) to dynamically perturb undesired visual semantics and Dual-Stream Balancing (DS-Bal) to establish a balanced learning paradigm for desired visual semantics. Extensive comparisons, ablations, and analyses demonstrate that MagicTailor not only excels in this challenging task but also holds significant promise for practical applications, paving the way for more nuanced and creative image generation.
SFANet: Spatial-Frequency Attention Network for Weather Forecasting
May 29, 2024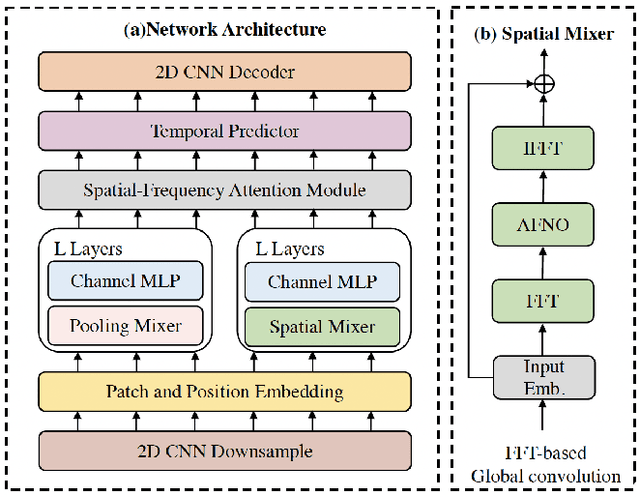

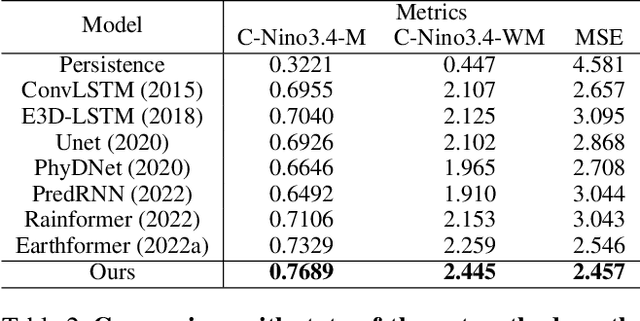
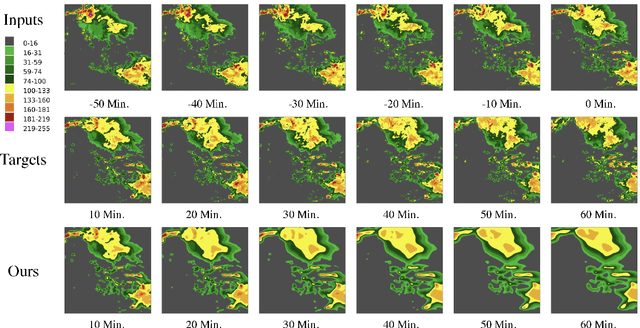
Weather forecasting plays a critical role in various sectors, driving decision-making and risk management. However, traditional methods often struggle to capture the complex dynamics of meteorological systems, particularly in the presence of high-resolution data. In this paper, we propose the Spatial-Frequency Attention Network (SFANet), a novel deep learning framework designed to address these challenges and enhance the accuracy of spatiotemporal weather prediction. Drawing inspiration from the limitations of existing methodologies, we present an innovative approach that seamlessly integrates advanced token mixing and attention mechanisms. By leveraging both pooling and spatial mixing strategies, SFANet optimizes the processing of high-dimensional spatiotemporal sequences, preserving inter-component relational information and modeling extensive long-range relationships. To further enhance feature integration, we introduce a novel spatial-frequency attention module, enabling the model to capture intricate cross-modal correlations. Our extensive experimental evaluation on two distinct datasets, the Storm EVent ImageRy (SEVIR) and the Institute for Climate and Application Research (ICAR) - El Ni\~{n}o Southern Oscillation (ENSO) dataset, demonstrates the remarkable performance of SFANet. Notably, SFANet achieves substantial advancements over state-of-the-art methods, showcasing its proficiency in forecasting precipitation patterns and predicting El Ni\~{n}o events.