 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust NAS under adversarial training: benchmark, theory, and beyond
Mar 19, 2024
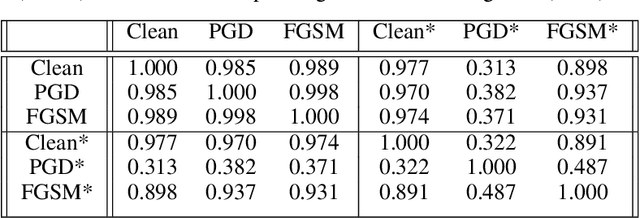
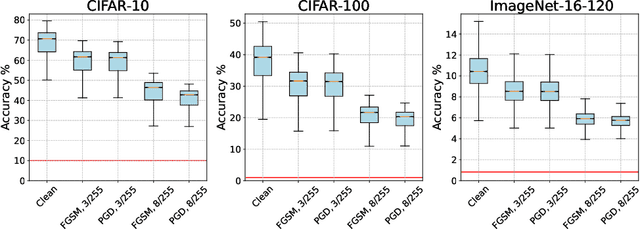

Recent developments in neural architecture search (NAS) emphasize the significance of considering robust architectures against malicious data. However, there is a notable absence of benchmark evaluations and theoretical guarantees for searching these robust architectures, especially when adversarial training is considered. In this work, we aim to address these two challenges, making twofold contributions. First, we release a comprehensive data set that encompasses both clean accuracy and robust accuracy for a vast array of adversarially trained networks from the NAS-Bench-201 search space on image datasets. Then, leveraging the neural tangent kernel (NTK) tool from deep learning theory, we establish a generalization theory for searching architecture in terms of clean accuracy and robust accuracy under multi-objective adversarial training. We firmly believe that our benchmark and theoretical insights will significantly benefit the NAS community through reliable reproducibility, efficient assessment, and theoretical foundation, particularly in the pursuit of robust architectures.
Unsupervised Open-Vocabulary Object Localization in Videos
Sep 18, 2023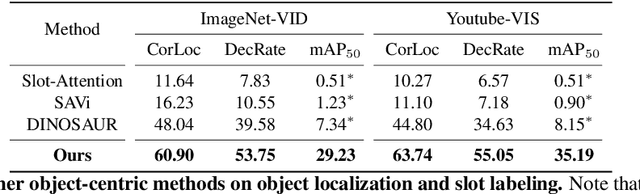
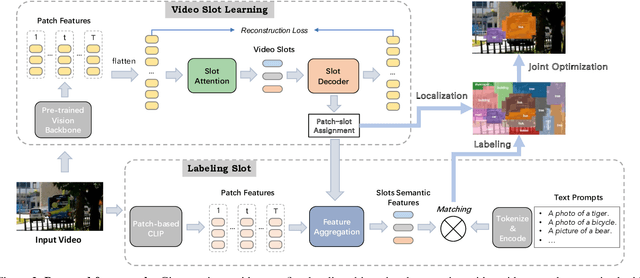
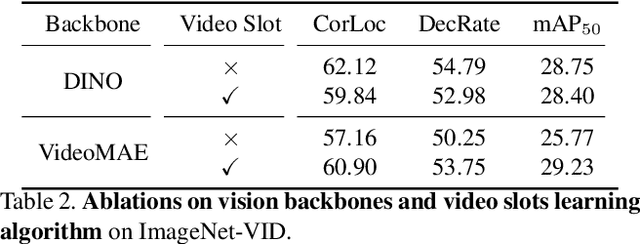
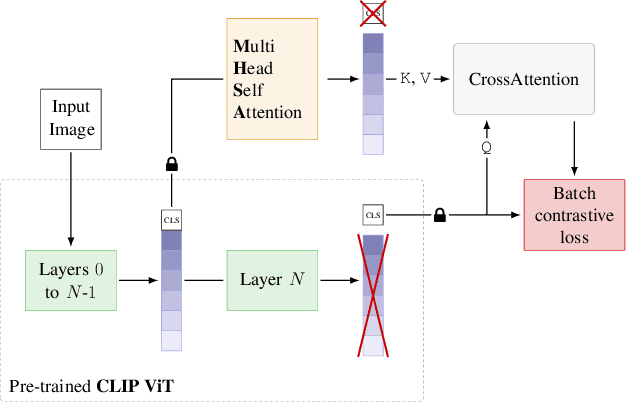
In this paper, we show that recent advances in video representation learning and pre-trained vision-language models allow for substantial improvements in self-supervised video object localization. We propose a method that first localizes objects in videos via a slot attention approach and then assigns text to the obtained slots. The latter is achieved by an unsupervised way to read localized semantic information from the pre-trained CLIP model. The resulting video object localization is entirely unsupervised apart from the implicit annotation contained in CLIP, and it is effectively the first unsupervised approach that yields good results on regular video benchmarks.
Object-Centric Multiple Object Tracking
Sep 05, 2023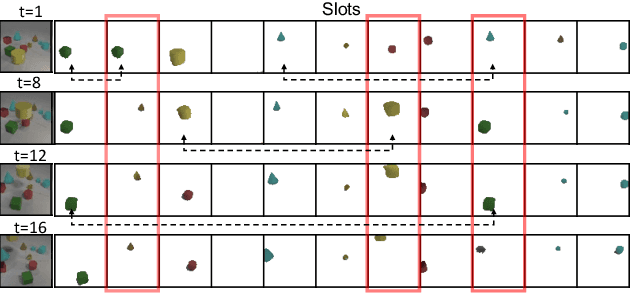
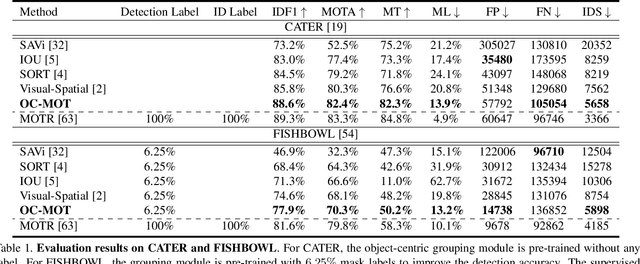
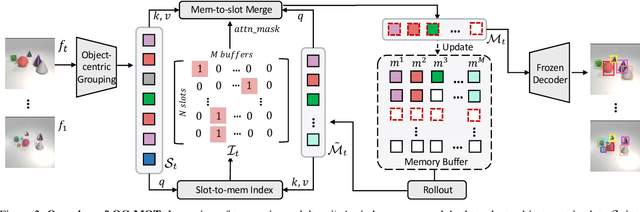
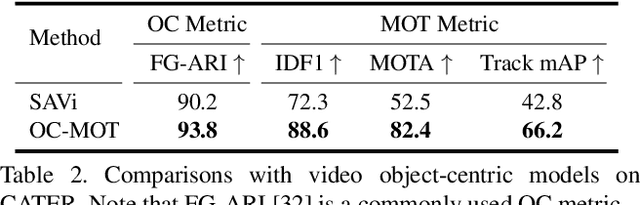
Unsupervised object-centric learning methods allow the partitioning of scenes into entities without additional localization information and are excellent candidates for reducing the annotation burden of multiple-object tracking (MOT) pipelines. Unfortunately, they lack two key properties: objects are often split into parts and are not consistently tracked over time. In fact, state-of-the-art models achieve pixel-level accuracy and temporal consistency by relying on supervised object detection with additional ID labels for the association through time. This paper proposes a video object-centric model for MOT. It consists of an index-merge module that adapts the object-centric slots into detection outputs and an object memory module that builds complete object prototypes to handle occlusions. Benefited from object-centric learning, we only require sparse detection labels (0%-6.25%) for object localization and feature binding. Relying on our self-supervised Expectation-Maximization-inspired loss for object association, our approach requires no ID labels. Our experiments significantly narrow the gap between the existing object-centric model and the fully supervised state-of-the-art and outperform several unsupervised trackers.
Bridging the Gap to Real-World Object-Centric Learning
Sep 29, 2022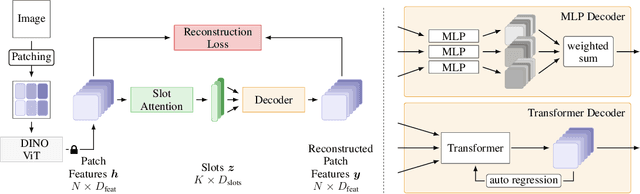
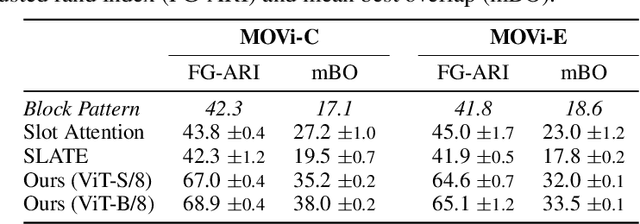


Humans naturally decompose their environment into entities at the appropriate level of abstraction to act in the world. Allowing machine learning algorithms to derive this decomposition in an unsupervised way has become an important line of research. However, current methods are restricted to simulated data or require additional information in the form of motion or depth in order to successfully discover objects. In this work, we overcome this limitation by showing that reconstructing features from models trained in a self-supervised manner is a sufficient training signal for object-centric representations to arise in a fully unsupervised way. Our approach, DINOSAUR, significantly out-performs existing object-centric learning models on simulated data and is the first unsupervised object-centric model that scales to real world-datasets such as COCO and PASCAL VOC. DINOSAUR is conceptually simple and shows competitive performance compared to more involved pipelines from the computer vision literature.
Targeted Separation and Convergence with Kernel Discrepancies
Sep 26, 2022Maximum mean discrepancies (MMDs) like the kernel Stein discrepancy (KSD) have grown central to a wide range of applications, including hypothesis testing, sampler selection, distribution approximation, and variational inference. In each setting, these kernel-based discrepancy measures are required to (i) separate a target P from other probability measures or even (ii) control weak convergence to P. In this article we derive new sufficient and necessary conditions to ensure (i) and (ii). For MMDs on separable metric spaces, we characterize those kernels that separate Bochner embeddable measures and introduce simple conditions for separating all measures with unbounded kernels and for controlling convergence with bounded kernels. We use these results on $\mathbb{R}^d$ to substantially broaden the known conditions for KSD separation and convergence control and to develop the first KSDs known to exactly metrize weak convergence to P. Along the way, we highlight the implications of our results for hypothesis testing, measuring and improving sample quality, and sampling with Stein variational gradient descent.
Assaying Out-Of-Distribution Generalization in Transfer Learning
Jul 19, 2022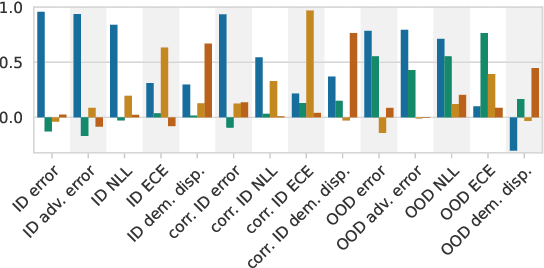
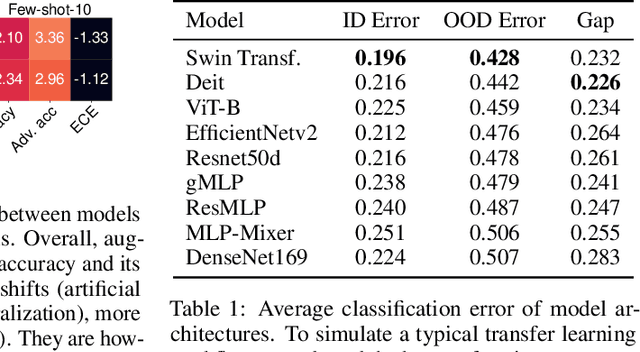
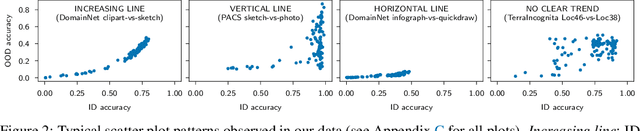
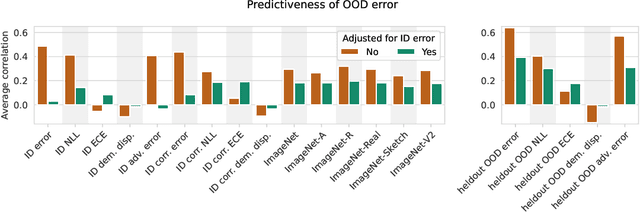
Since out-of-distribution generalization is a generally ill-posed problem, various proxy targets (e.g., calibration, adversarial robustness, algorithmic corruptions, invariance across shifts) were studied across different research programs resulting in different recommendations. While sharing the same aspirational goal, these approaches have never been tested under the same experimental conditions on real data. In this paper, we take a unified view of previous work, highlighting message discrepancies that we address empirically, and providing recommendations on how to measure the robustness of a model and how to improve it. To this end, we collect 172 publicly available dataset pairs for training and out-of-distribution evaluation of accuracy, calibration error, adversarial attacks, environment invariance, and synthetic corruptions. We fine-tune over 31k networks, from nine different architectures in the many- and few-shot setting. Our findings confirm that in- and out-of-distribution accuracies tend to increase jointly, but show that their relation is largely dataset-dependent, and in general more nuanced and more complex than posited by previous, smaller scale studies.
PopSkipJump: Decision-Based Attack for Probabilistic Classifiers
Jun 14, 2021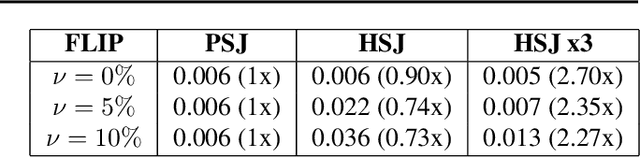
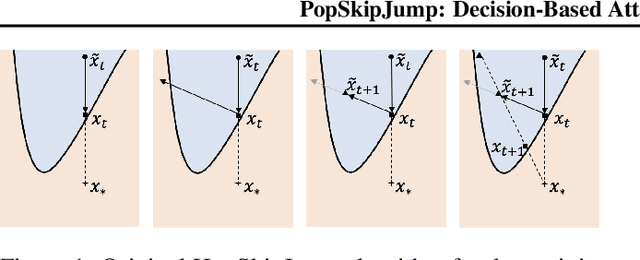
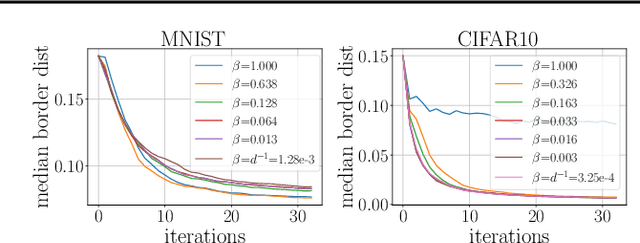

Most current classifiers are vulnerable to adversarial examples, small input perturbations that change the classification output. Many existing attack algorithms cover various settings, from white-box to black-box classifiers, but typically assume that the answers are deterministic and often fail when they are not. We therefore propose a new adversarial decision-based attack specifically designed for classifiers with probabilistic outputs. It is based on the HopSkipJump attack by Chen et al. (2019, arXiv:1904.02144v5 ), a strong and query efficient decision-based attack originally designed for deterministic classifiers. Our P(robabilisticH)opSkipJump attack adapts its amount of queries to maintain HopSkipJump's original output quality across various noise levels, while converging to its query efficiency as the noise level decreases. We test our attack on various noise models, including state-of-the-art off-the-shelf randomized defenses, and show that they offer almost no extra robustness to decision-based attacks. Code is available at https://github.com/cjsg/PopSkipJump .
Metrizing Weak Convergence with Maximum Mean Discrepancies
Jun 16, 2020Theorem 12 of Simon-Gabriel & Sch\"olkopf (JMLR, 2018) seemed to close a 40-year-old quest to characterize maximum mean discrepancies (MMD) that metrize the weak convergence of probability measures. We prove, however, that the theorem is incorrect and provide a correction. We show that, on a locally compact, non-compact, Hausdorff space, the MMD of a bounded continuous Borel measurable kernel k, whose RKHS-functions vanish at infinity, metrizes the weak convergence of probability measures if and only if k is continuous and integrally strictly positive definite (ISPD) over all signed, finite, regular Borel measures. We also show that, contrary to the claim of the aforementioned Theorem 12, there exist both bounded continuous ISPD kernels that do not metrize weak convergence and bounded continuous non-ISPD kernels that do metrize it.
Adversarial Vulnerability of Neural Networks Increases With Input Dimension
Oct 08, 2018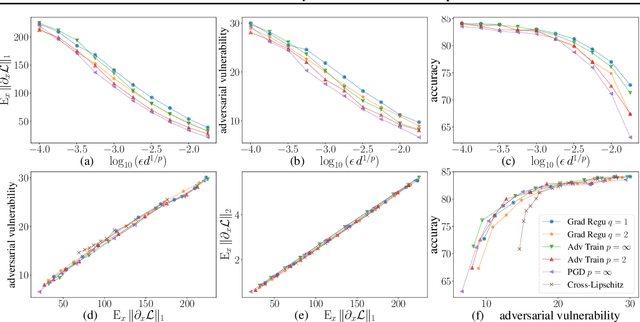
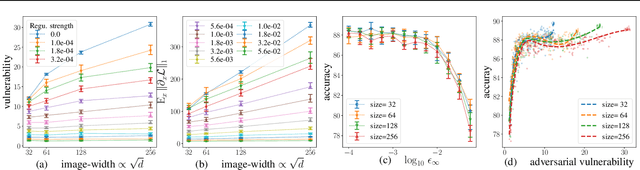
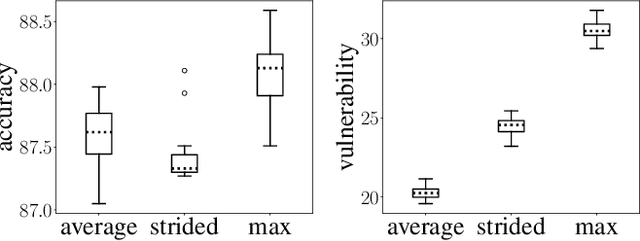
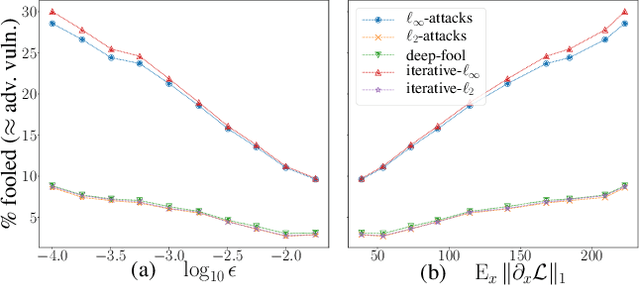
Over the past four years, neural networks have been proven vulnerable to adversarial images: targeted but imperceptible image perturbations lead to drastically different predictions. We show that adversarial vulnerability increases with the gradients of the training objective when viewed as a function of the inputs. For most current network architectures, we prove that the $\ell_1$-norm of these gradients grows as the square root of the input size. These nets therefore become increasingly vulnerable with growing image size. Our proofs rely on the network's weight distribution at initialization, but extensive experiments confirm that our conclusions still hold after training.
AdaGAN: Boosting Generative Models
May 24, 2017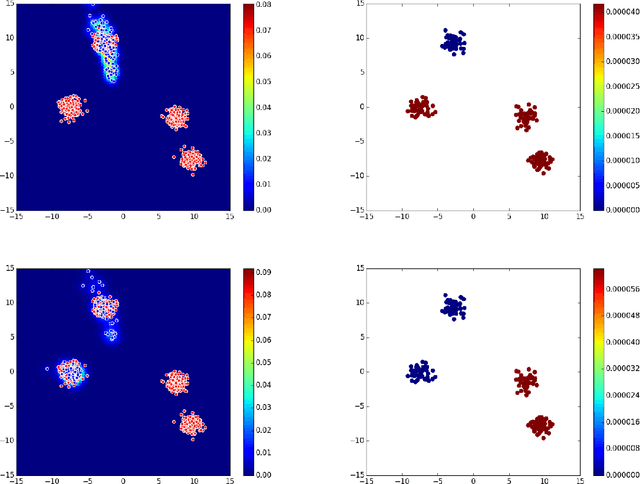
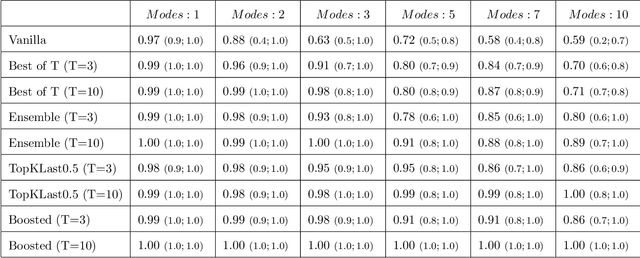
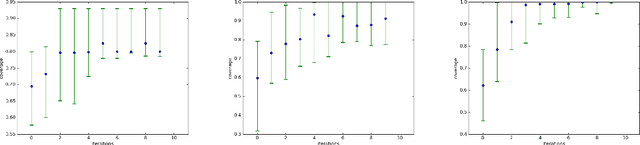
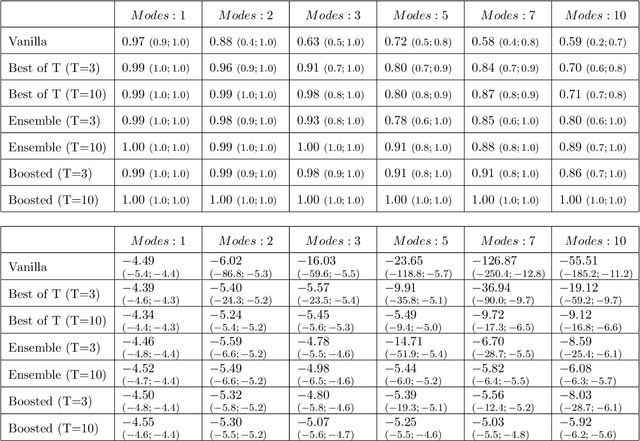
Generative Adversarial Networks (GAN) (Goodfellow et al., 2014) are an effective method for training generative models of complex data such as natural images. However, they are notoriously hard to train and can suffer from the problem of missing modes where the model is not able to produce examples in certain regions of the space. We propose an iterative procedure, called AdaGAN, where at every step we add a new component into a mixture model by running a GAN algorithm on a reweighted sample. This is inspired by boosting algorithms, where many potentially weak individual predictors are greedily aggregated to form a strong composite predictor. We prove that such an incremental procedure leads to convergence to the true distribution in a finite number of steps if each step is optimal, and convergence at an exponential rate otherwise. We also illustrate experimentally that this procedure addresses the problem of missing modes.