Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Vulnerability of Neural Networks Increases With Input Dimension
Paper and Code
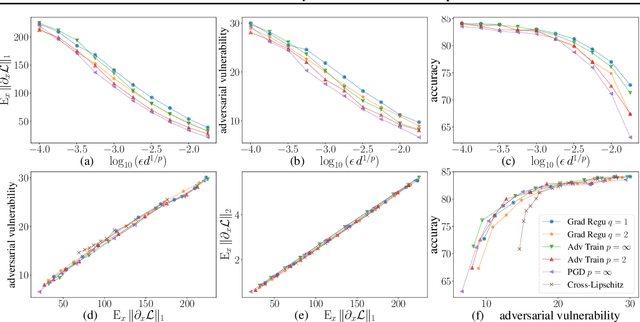
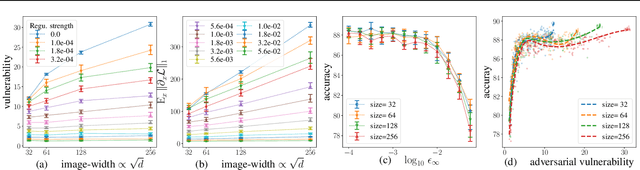
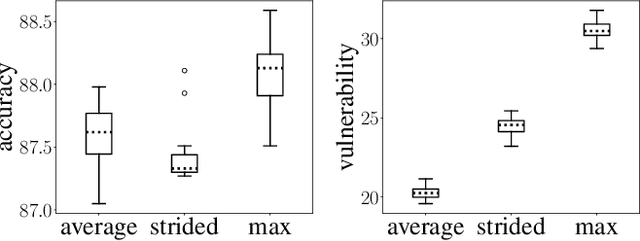
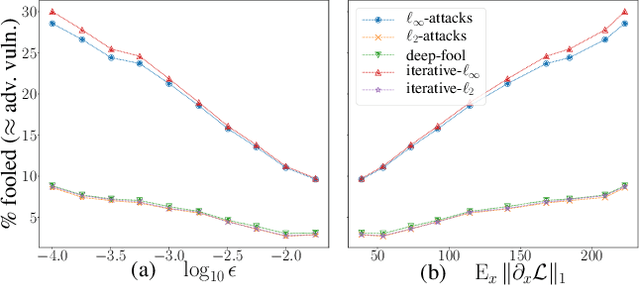
Over the past four years, neural networks have been proven vulnerable to adversarial images: targeted but imperceptible image perturbations lead to drastically different predictions. We show that adversarial vulnerability increases with the gradients of the training objective when viewed as a function of the inputs. For most current network architectures, we prove that the $\ell_1$-norm of these gradients grows as the square root of the input size. These nets therefore become increasingly vulnerable with growing image size. Our proofs rely on the network's weight distribution at initialization, but extensive experiments confirm that our conclusions still hold after training.
* 10 pages main text and references, 8 pages appendix, 7 figures
View paper on
 OpenReview
OpenReview