 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Slot Attention: Object Discovery with Dynamic Slot Number
Jun 13, 2024
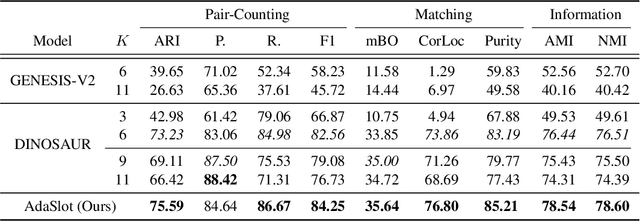

Object-centric learning (OCL) extracts the representation of objects with slots, offering an exceptional blend of flexibility and interpretability for abstracting low-level perceptual features. A widely adopted method within OCL is slot attention, which utilizes attention mechanisms to iteratively refine slot representations. However, a major drawback of most object-centric models, including slot attention, is their reliance on predefining the number of slots. This not only necessitates prior knowledge of the dataset but also overlooks the inherent variability in the number of objects present in each instance. To overcome this fundamental limitation, we present a novel complexity-aware object auto-encoder framework. Within this framework, we introduce an adaptive slot attention (AdaSlot) mechanism that dynamically determines the optimal number of slots based on the content of the data. This is achieved by proposing a discrete slot sampling module that is responsible for selecting an appropriate number of slots from a candidate list. Furthermore, we introduce a masked slot decoder that suppresses unselected slots during the decoding process. Our framework, tested extensively on object discovery tasks with various datasets, shows performance matching or exceeding top fixed-slot models. Moreover, our analysis substantiates that our method exhibits the capability to dynamically adapt the slot number according to each instance's complexity, offering the potential for further exploration in slot attention research. Project will be available at https://kfan21.github.io/AdaSlot/
Unsupervised Open-Vocabulary Object Localization in Videos
Sep 18, 2023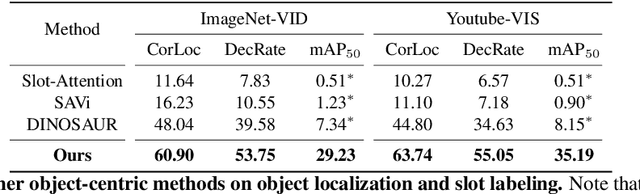
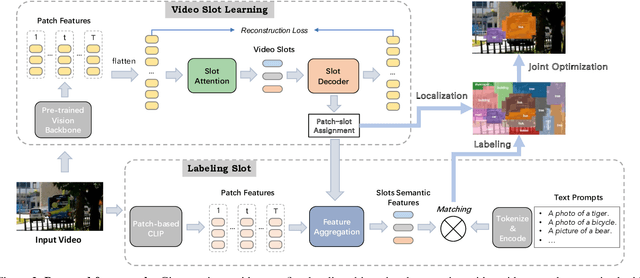
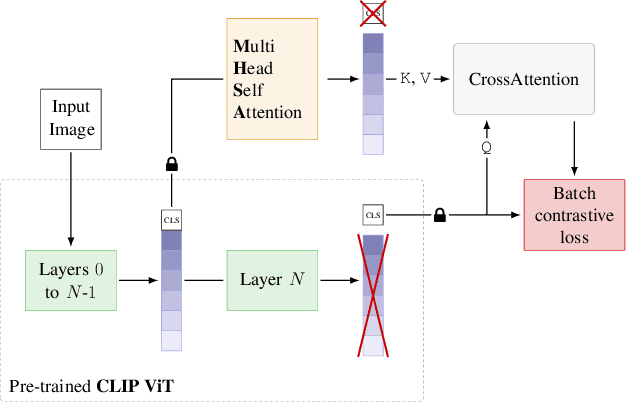
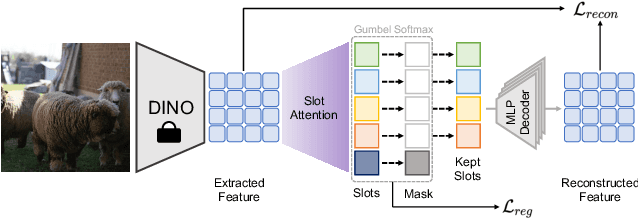
In this paper, we show that recent advances in video representation learning and pre-trained vision-language models allow for substantial improvements in self-supervised video object localization. We propose a method that first localizes objects in videos via a slot attention approach and then assigns text to the obtained slots. The latter is achieved by an unsupervised way to read localized semantic information from the pre-trained CLIP model. The resulting video object localization is entirely unsupervised apart from the implicit annotation contained in CLIP, and it is effectively the first unsupervised approach that yields good results on regular video benchmarks.
Object-Centric Multiple Object Tracking
Sep 05, 2023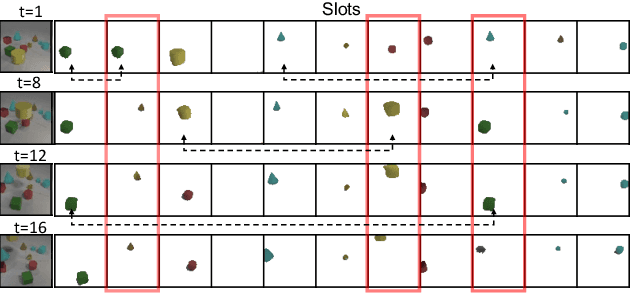
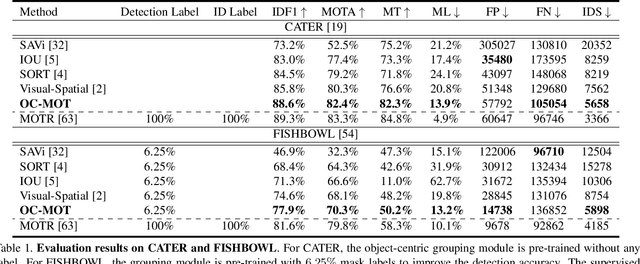
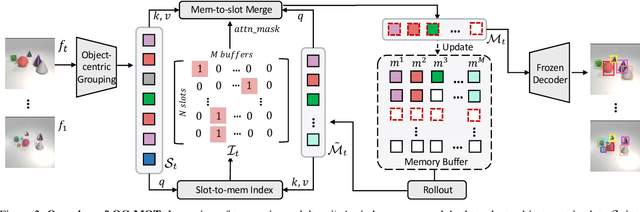
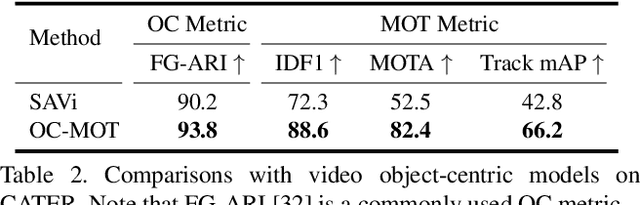
Unsupervised object-centric learning methods allow the partitioning of scenes into entities without additional localization information and are excellent candidates for reducing the annotation burden of multiple-object tracking (MOT) pipelines. Unfortunately, they lack two key properties: objects are often split into parts and are not consistently tracked over time. In fact, state-of-the-art models achieve pixel-level accuracy and temporal consistency by relying on supervised object detection with additional ID labels for the association through time. This paper proposes a video object-centric model for MOT. It consists of an index-merge module that adapts the object-centric slots into detection outputs and an object memory module that builds complete object prototypes to handle occlusions. Benefited from object-centric learning, we only require sparse detection labels (0%-6.25%) for object localization and feature binding. Relying on our self-supervised Expectation-Maximization-inspired loss for object association, our approach requires no ID labels. Our experiments significantly narrow the gap between the existing object-centric model and the fully supervised state-of-the-art and outperform several unsupervised trackers.
A data augmentation perspective on diffusion models and retrieval
Apr 20, 2023Diffusion models excel at generating photorealistic images from text-queries. Naturally, many approaches have been proposed to use these generative abilities to augment training datasets for downstream tasks, such as classification. However, diffusion models are themselves trained on large noisily supervised, but nonetheless, annotated datasets. It is an open question whether the generalization capabilities of diffusion models beyond using the additional data of the pre-training process for augmentation lead to improved downstream performance. We perform a systematic evaluation of existing methods to generate images from diffusion models and study new extensions to assess their benefit for data augmentation. While we find that personalizing diffusion models towards the target data outperforms simpler prompting strategies, we also show that using the training data of the diffusion model alone, via a simple nearest neighbor retrieval procedure, leads to even stronger downstream performance. Overall, our study probes the limitations of diffusion models for data augmentation but also highlights its potential in generating new training data to improve performance on simple downstream vision tasks.
Causal Triplet: An Open Challenge for Intervention-centric Causal Representation Learning
Jan 12, 2023


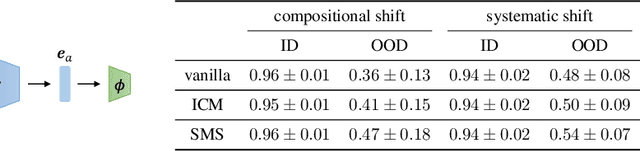
Recent years have seen a surge of interest in learning high-level causal representations from low-level image pairs under interventions. Yet, existing efforts are largely limited to simple synthetic settings that are far away from real-world problems. In this paper, we present Causal Triplet, a causal representation learning benchmark featuring not only visually more complex scenes, but also two crucial desiderata commonly overlooked in previous works: (i) an actionable counterfactual setting, where only certain object-level variables allow for counterfactual observations whereas others do not; (ii) an interventional downstream task with an emphasis on out-of-distribution robustness from the independent causal mechanisms principle. Through extensive experiments, we find that models built with the knowledge of disentangled or object-centric representations significantly outperform their distributed counterparts. However, recent causal representation learning methods still struggle to identify such latent structures, indicating substantial challenges and opportunities for future work. Our code and datasets will be available at https://sites.google.com/view/causaltriplet.
Bridging the Gap to Real-World Object-Centric Learning
Sep 29, 2022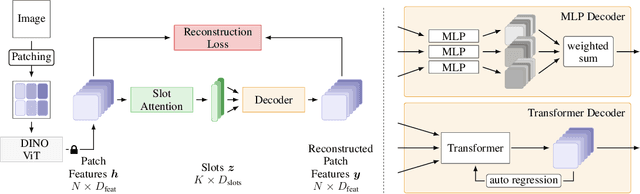
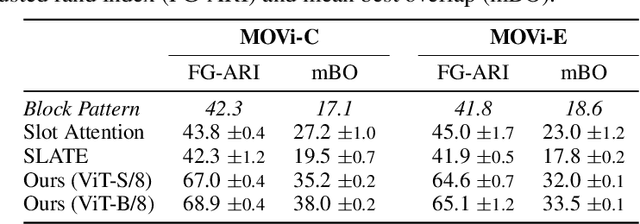


Humans naturally decompose their environment into entities at the appropriate level of abstraction to act in the world. Allowing machine learning algorithms to derive this decomposition in an unsupervised way has become an important line of research. However, current methods are restricted to simulated data or require additional information in the form of motion or depth in order to successfully discover objects. In this work, we overcome this limitation by showing that reconstructing features from models trained in a self-supervised manner is a sufficient training signal for object-centric representations to arise in a fully unsupervised way. Our approach, DINOSAUR, significantly out-performs existing object-centric learning models on simulated data and is the first unsupervised object-centric model that scales to real world-datasets such as COCO and PASCAL VOC. DINOSAUR is conceptually simple and shows competitive performance compared to more involved pipelines from the computer vision literature.
Assaying Out-Of-Distribution Generalization in Transfer Learning
Jul 19, 2022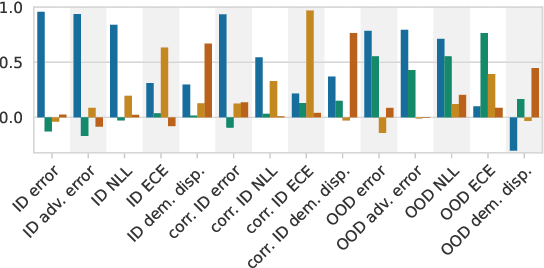
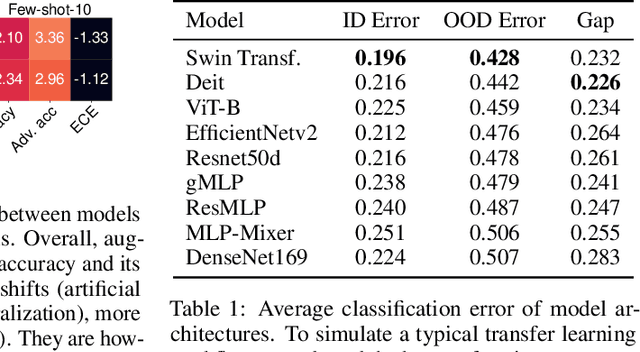
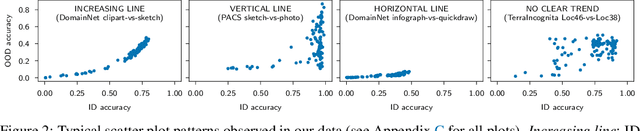
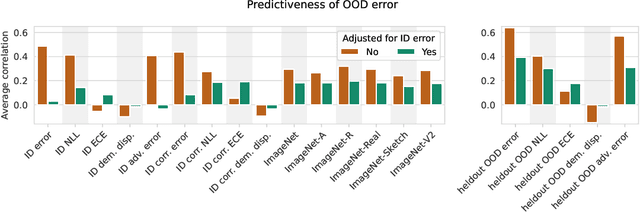
Since out-of-distribution generalization is a generally ill-posed problem, various proxy targets (e.g., calibration, adversarial robustness, algorithmic corruptions, invariance across shifts) were studied across different research programs resulting in different recommendations. While sharing the same aspirational goal, these approaches have never been tested under the same experimental conditions on real data. In this paper, we take a unified view of previous work, highlighting message discrepancies that we address empirically, and providing recommendations on how to measure the robustness of a model and how to improve it. To this end, we collect 172 publicly available dataset pairs for training and out-of-distribution evaluation of accuracy, calibration error, adversarial attacks, environment invariance, and synthetic corruptions. We fine-tune over 31k networks, from nine different architectures in the many- and few-shot setting. Our findings confirm that in- and out-of-distribution accuracies tend to increase jointly, but show that their relation is largely dataset-dependent, and in general more nuanced and more complex than posited by previous, smaller scale studies.
Pathologies in priors and inference for Bayesian transformers
Oct 15, 2021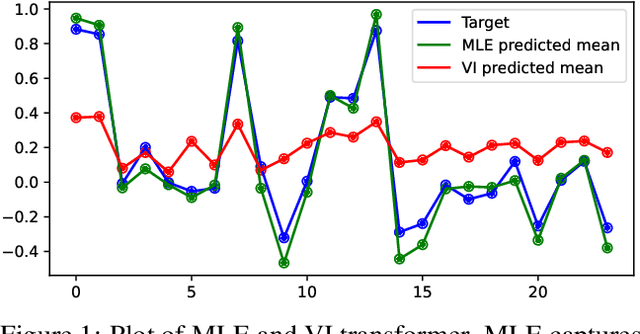
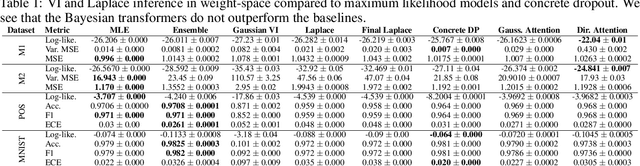


In recent years, the transformer has established itself as a workhorse in many applications ranging from natural language processing to reinforcement learning. Similarly, Bayesian deep learning has become the gold-standard for uncertainty estimation in safety-critical applications, where robustness and calibration are crucial. Surprisingly, no successful attempts to improve transformer models in terms of predictive uncertainty using Bayesian inference exist. In this work, we study this curiously underpopulated area of Bayesian transformers. We find that weight-space inference in transformers does not work well, regardless of the approximate posterior. We also find that the prior is at least partially at fault, but that it is very hard to find well-specified weight priors for these models. We hypothesize that these problems stem from the complexity of obtaining a meaningful mapping from weight-space to function-space distributions in the transformer. Therefore, moving closer to function-space, we propose a novel method based on the implicit reparameterization of the Dirichlet distribution to apply variational inference directly to the attention weights. We find that this proposed method performs competitively with our baselines.
Predicting sepsis in multi-site, multi-national intensive care cohorts using deep learning
Jul 12, 2021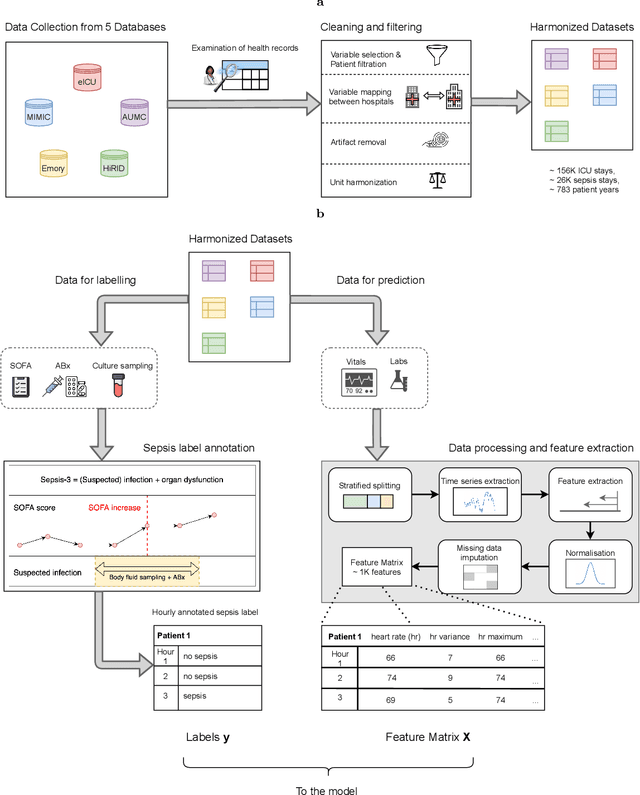
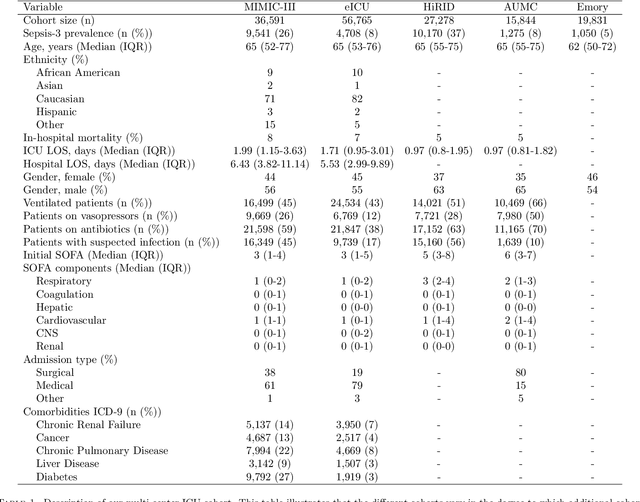
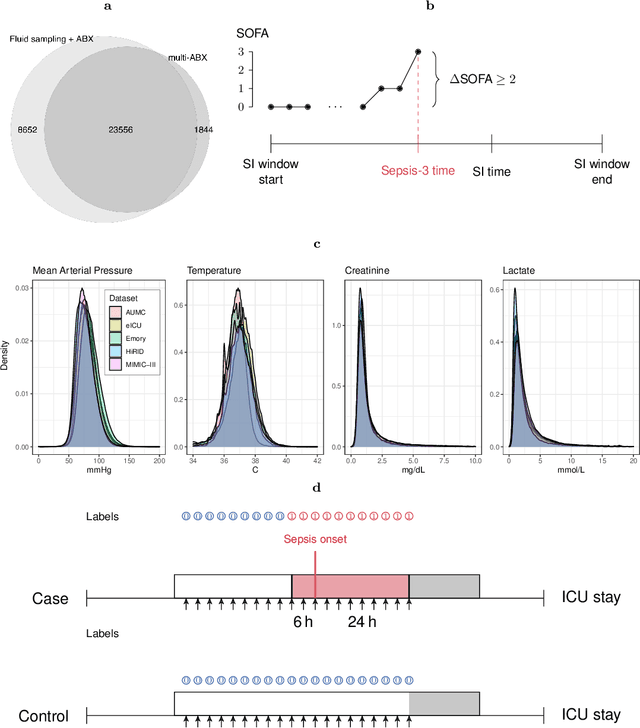
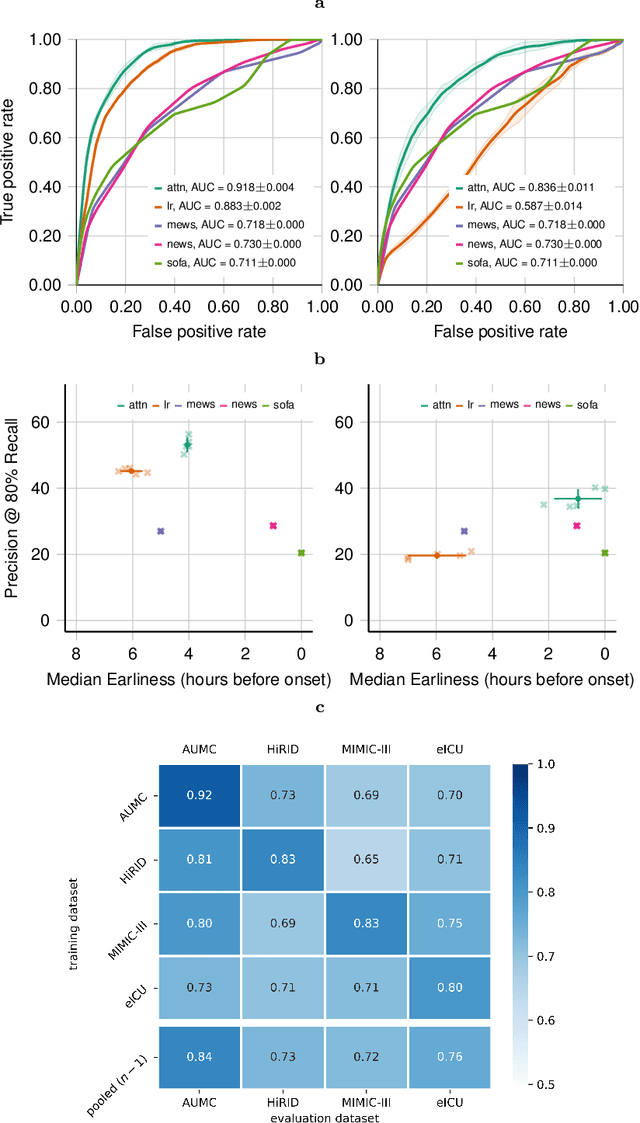
Despite decades of clinical research, sepsis remains a global public health crisis with high mortality, and morbidity. Currently, when sepsis is detected and the underlying pathogen is identified, organ damage may have already progressed to irreversible stages. Effective sepsis management is therefore highly time-sensitive. By systematically analysing trends in the plethora of clinical data available in the intensive care unit (ICU), an early prediction of sepsis could lead to earlier pathogen identification, resistance testing, and effective antibiotic and supportive treatment, and thereby become a life-saving measure. Here, we developed and validated a machine learning (ML) system for the prediction of sepsis in the ICU. Our analysis represents the largest multi-national, multi-centre in-ICU study for sepsis prediction using ML to date. Our dataset contains $156,309$ unique ICU admissions, which represent a refined and harmonised subset of five large ICU databases originating from three countries. Using the international consensus definition Sepsis-3, we derived hourly-resolved sepsis label annotations, amounting to $26,734$ ($17.1\%$) septic stays. We compared our approach, a deep self-attention model, to several clinical baselines as well as ML baselines and performed an extensive internal and external validation within and across databases. On average, our model was able to predict sepsis with an AUROC of $0.847 \pm 0.050$ (internal out-of sample validation) and $0.761 \pm 0.052$ (external validation). For a harmonised prevalence of $17\%$, at $80\%$ recall our model detects septic patients with $39\%$ precision 3.7 hours in advance.
Evaluation Metrics for Graph Generative Models: Problems, Pitfalls, and Practical Solutions
Jun 02, 2021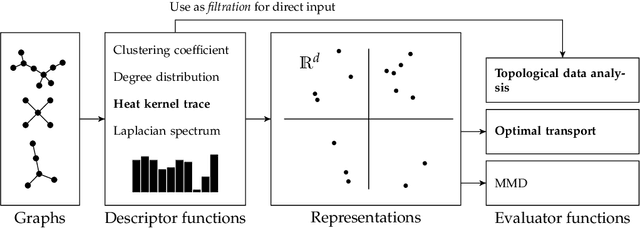
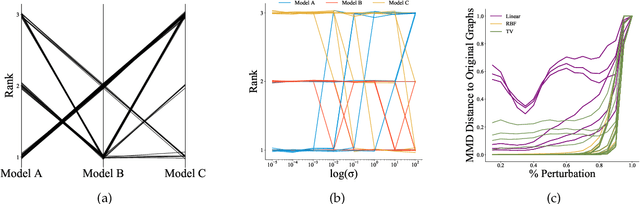
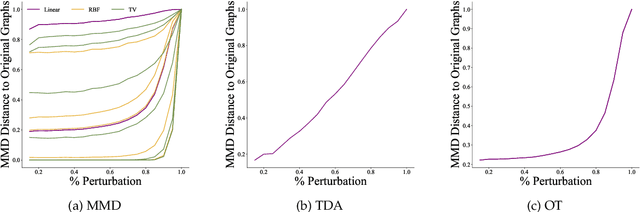

Graph generative models are a highly active branch of machine learning. Given the steady development of new models of ever-increasing complexity, it is necessary to provide a principled way to evaluate and compare them. In this paper, we enumerate the desirable criteria for comparison metrics, discuss the development of such metrics, and provide a comparison of their respective expressive power. We perform a systematic evaluation of the main metrics in use today, highlighting some of the challenges and pitfalls researchers inadvertently can run into. We then describe a collection of suitable metrics, give recommendations as to their practical suitability, and analyse their behaviour on synthetically generated perturbed graphs as well as on recently proposed graph generative models.