 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Aligned Evaluation of Uncertainty Quantification
Jun 25, 2026Uncertainty estimates in machine learning are typically evaluated using generic metrics such as the negative log-likelihood and expected calibration error, yet good performance on such metrics does not necessarily imply high utility in downstream decisions. We introduce decision-alignment, a criterion that reveals which evaluation metrics meaningfully align with downstream utilities. Applying this framework, we show that many widely used uncertainty metrics are either misaligned with common decision problems or encode pathological prior beliefs about the downstream task. We then propose prior-weighted utility metrics, a special class of proper scoring rules that provides decision-aligned uncertainty evaluation. Across benchmark experiments and real-world case studies, our metrics consistently align with realized decision utility, while conventional metrics do not. Our results surface flaws in the current UQ evaluation protocol and offer a principled extension of existing metrics toward decision-relevant UQ evaluation.
Gaussian Mean Field Variational Inference can Overestimate Predictive Variance
Jun 24, 2026Mean Field Variational Inference (MFVI) is widely understood to underestimate posterior variance. By analysing conjugate Bayesian Linear Regression (BLR), we show that this characterization is incomplete: while MFVI underestimates the variance in parameter space, it can overestimate the predictive variance compared to the exact posterior. We show that if the MFVI posterior underestimates predictive variances in some directions, it necessarily overestimates them in others. Crucially, this overestimation occurs in directions where the training data concentrates. This leads to the surprising result that, for a test point drawn from the training distribution, MFVI's expected predictive variance exceeds that of the exact posterior. We demonstrate a pathological case of this effect, where the MFVI posterior fails to reduce predictive variance compared to the prior on in distribution data. We connect these results to the Cold Posterior Effect, arguing that varying the temperature can correct this overestimation, yielding predictions closer to those of the exact posterior. We validate our theory on synthetic and real-world regression tasks.
Standard Acquisition Is Sufficient for Asynchronous Bayesian Optimization
Mar 13, 2026Asynchronous Bayesian optimization is widely used for gradient-free optimization in domains with independent parallel experiments and varying evaluation times. Existing methods posit that standard acquisitions lead to redundant and repeated queries, proposing complex solutions to enforce diversity in queries. Challenging this fundamental premise, we show that methods, like the Upper Confidence Bound, can in fact achieve theoretical guarantees essentially equivalent to those of sequential Thompson sampling. A conceptual analysis of asynchronous Bayesian optimization reveals that existing works neglect intermediate posterior updates, which we find to be generally sufficient to avoid redundant queries. Further investigation shows that by penalizing busy locations, diversity-enforcing methods can over-explore in asynchronous settings, reducing their performance. Our extensive experiments demonstrate that simple standard acquisition functions match or outperform purpose-built asynchronous methods across synthetic and real-world tasks.
In-Context Function Learning in Large Language Models
Feb 12, 2026Large language models (LLMs) can learn from a few demonstrations provided at inference time. We study this in-context learning phenomenon through the lens of Gaussian Processes (GPs). We build controlled experiments where models observe sequences of multivariate scalar-valued function samples drawn from known GP priors. We evaluate prediction error in relation to the number of demonstrations and compare against two principled references: (i) an empirical GP-regression learner that gives a lower bound on achievable error, and (ii) the expected error of a 1-nearest-neighbor (1-NN) rule, which gives a data-driven upper bound. Across model sizes, we find that LLM learning curves are strongly influenced by the function-generating kernels and approach the GP lower bound as the number of demonstrations increases. We then study the inductive biases of these models using a likelihood-based analysis. We find that LLM predictions are most likely under less smooth GP kernels. Finally, we explore whether post-training can shift these inductive biases and improve sample-efficiency on functions sampled from GPs with smoother kernels. We find that both reinforcement learning and supervised fine-tuning can effectively shift inductive biases in the direction of the training data. Together, our framework quantifies the extent to which LLMs behave like GP learners and provides tools for steering their inductive biases for continuous function learning tasks.
Amortising Inference and Meta-Learning Priors in Neural Networks
Feb 09, 2026One of the core facets of Bayesianism is in the updating of prior beliefs in light of new evidence$\text{ -- }$so how can we maintain a Bayesian approach if we have no prior beliefs in the first place? This is one of the central challenges in the field of Bayesian deep learning, where it is not clear how to represent beliefs about a prediction task by prior distributions over model parameters. Bridging the fields of Bayesian deep learning and probabilistic meta-learning, we introduce a way to $\textit{learn}$ a weights prior from a collection of datasets by introducing a way to perform per-dataset amortised variational inference. The model we develop can be viewed as a neural process whose latent variable is the set of weights of a BNN and whose decoder is the neural network parameterised by a sample of the latent variable itself. This unique model allows us to study the behaviour of Bayesian neural networks under well-specified priors, use Bayesian neural networks as flexible generative models, and perform desirable but previously elusive feats in neural processes such as within-task minibatching or meta-learning under extreme data-starvation.
Data-Driven Discovery of Feature Groups in Clinical Time Series
Nov 11, 2025Clinical time series data are critical for patient monitoring and predictive modeling. These time series are typically multivariate and often comprise hundreds of heterogeneous features from different data sources. The grouping of features based on similarity and relevance to the prediction task has been shown to enhance the performance of deep learning architectures. However, defining these groups a priori using only semantic knowledge is challenging, even for domain experts. To address this, we propose a novel method that learns feature groups by clustering weights of feature-wise embedding layers. This approach seamlessly integrates into standard supervised training and discovers the groups that directly improve downstream performance on clinically relevant tasks. We demonstrate that our method outperforms static clustering approaches on synthetic data and achieves performance comparable to expert-defined groups on real-world medical data. Moreover, the learned feature groups are clinically interpretable, enabling data-driven discovery of task-relevant relationships between variables.
ProSpero: Active Learning for Robust Protein Design Beyond Wild-Type Neighborhoods
May 28, 2025Designing protein sequences of both high fitness and novelty is a challenging task in data-efficient protein engineering. Exploration beyond wild-type neighborhoods often leads to biologically implausible sequences or relies on surrogate models that lose fidelity in novel regions. Here, we propose ProSpero, an active learning framework in which a frozen pre-trained generative model is guided by a surrogate updated from oracle feedback. By integrating fitness-relevant residue selection with biologically-constrained Sequential Monte Carlo sampling, our approach enables exploration beyond wild-type neighborhoods while preserving biological plausibility. We show that our framework remains effective even when the surrogate is misspecified. ProSpero consistently outperforms or matches existing methods across diverse protein engineering tasks, retrieving sequences of both high fitness and novelty.
Sparse Gaussian Neural Processes
Apr 02, 2025Despite significant recent advances in probabilistic meta-learning, it is common for practitioners to avoid using deep learning models due to a comparative lack of interpretability. Instead, many practitioners simply use non-meta-models such as Gaussian processes with interpretable priors, and conduct the tedious procedure of training their model from scratch for each task they encounter. While this is justifiable for tasks with a limited number of data points, the cubic computational cost of exact Gaussian process inference renders this prohibitive when each task has many observations. To remedy this, we introduce a family of models that meta-learn sparse Gaussian process inference. Not only does this enable rapid prediction on new tasks with sparse Gaussian processes, but since our models have clear interpretations as members of the neural process family, it also allows manual elicitation of priors in a neural process for the first time. In meta-learning regimes for which the number of observed tasks is small or for which expert domain knowledge is available, this offers a crucial advantage.
Can Transformers Learn Full Bayesian Inference in Context?
Jan 28, 2025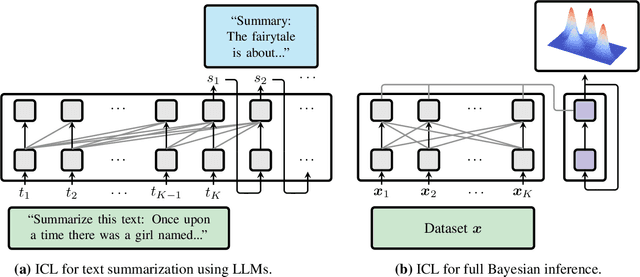
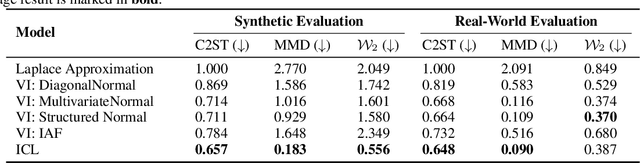
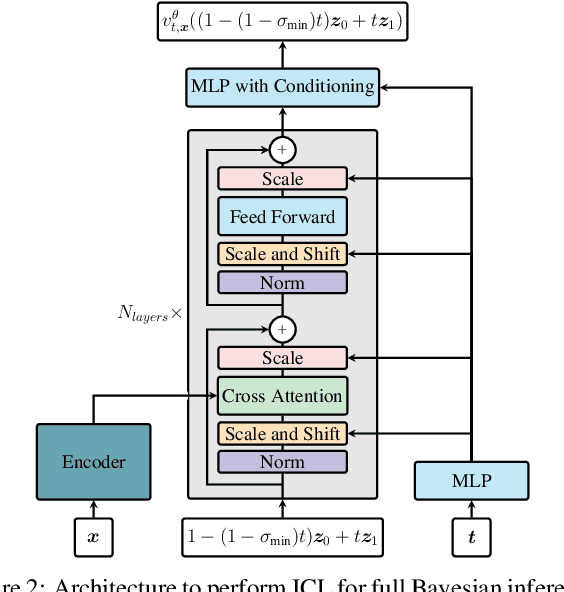

Transformers have emerged as the dominant architecture in the field of deep learning, with a broad range of applications and remarkable in-context learning (ICL) capabilities. While not yet fully understood, ICL has already proved to be an intriguing phenomenon, allowing transformers to learn in context -- without requiring further training. In this paper, we further advance the understanding of ICL by demonstrating that transformers can perform full Bayesian inference for commonly used statistical models in context. More specifically, we introduce a general framework that builds on ideas from prior fitted networks and continuous normalizing flows which enables us to infer complex posterior distributions for methods such as generalized linear models and latent factor models. Extensive experiments on real-world datasets demonstrate that our ICL approach yields posterior samples that are similar in quality to state-of-the-art MCMC or variational inference methods not operating in context.
OneProt: Towards Multi-Modal Protein Foundation Models
Nov 07, 2024



Recent AI advances have enabled multi-modal systems to model and translate diverse information spaces. Extending beyond text and vision, we introduce OneProt, a multi-modal AI for proteins that integrates structural, sequence, alignment, and binding site data. Using the ImageBind framework, OneProt aligns the latent spaces of modality encoders along protein sequences. It demonstrates strong performance in retrieval tasks and surpasses state-of-the-art methods in various downstream tasks, including metal ion binding classification, gene-ontology annotation, and enzyme function prediction. This work expands multi-modal capabilities in protein models, paving the way for applications in drug discovery, biocatalytic reaction planning, and protein engineering.