 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse What You Know: Causal Foundation Models with Partial Graphs
Feb 16, 2026Estimating causal quantities traditionally relies on bespoke estimators tailored to specific assumptions. Recently proposed Causal Foundation Models (CFMs) promise a more unified approach by amortising causal discovery and inference in a single step. However, in their current state, they do not allow for the incorporation of any domain knowledge, which can lead to suboptimal predictions. We bridge this gap by introducing methods to condition CFMs on causal information, such as the causal graph or more readily available ancestral information. When access to complete causal graph information is too strict a requirement, our approach also effectively leverages partial causal information. We systematically evaluate conditioning strategies and find that injecting learnable biases into the attention mechanism is the most effective method to utilise full and partial causal information. Our experiments show that this conditioning allows a general-purpose CFM to match the performance of specialised models trained on specific causal structures. Overall, our approach addresses a central hurdle on the path towards all-in-one causal foundation models: the capability to answer causal queries in a data-driven manner while effectively leveraging any amount of domain expertise.
Do-PFN: In-Context Learning for Causal Effect Estimation
Jun 06, 2025Estimation of causal effects is critical to a range of scientific disciplines. Existing methods for this task either require interventional data, knowledge about the ground truth causal graph, or rely on assumptions such as unconfoundedness, restricting their applicability in real-world settings. In the domain of tabular machine learning, Prior-data fitted networks (PFNs) have achieved state-of-the-art predictive performance, having been pre-trained on synthetic data to solve tabular prediction problems via in-context learning. To assess whether this can be transferred to the harder problem of causal effect estimation, we pre-train PFNs on synthetic data drawn from a wide variety of causal structures, including interventions, to predict interventional outcomes given observational data. Through extensive experiments on synthetic case studies, we show that our approach allows for the accurate estimation of causal effects without knowledge of the underlying causal graph. We also perform ablation studies that elucidate Do-PFN's scalability and robustness across datasets with a variety of causal characteristics.
Position: The Future of Bayesian Prediction Is Prior-Fitted
May 29, 2025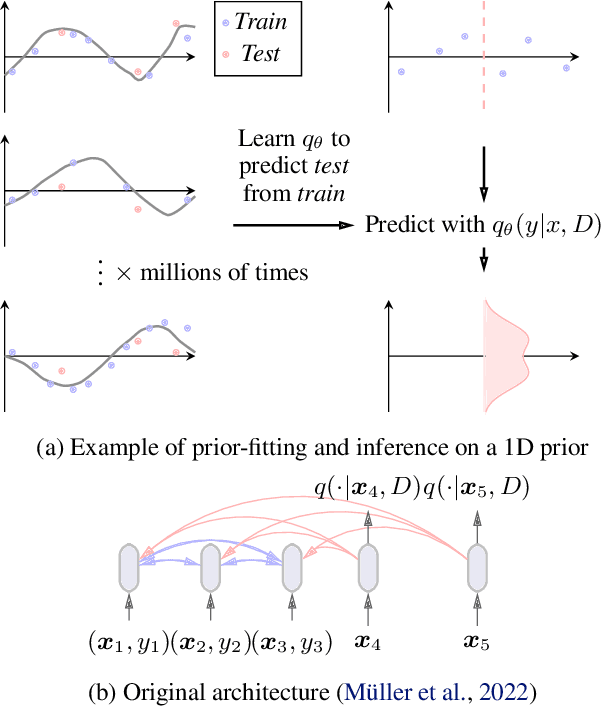
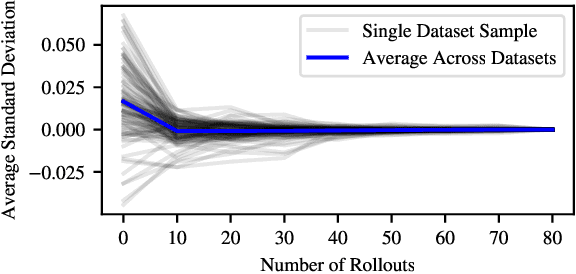
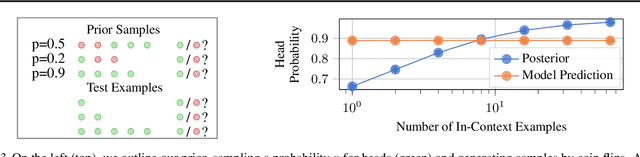
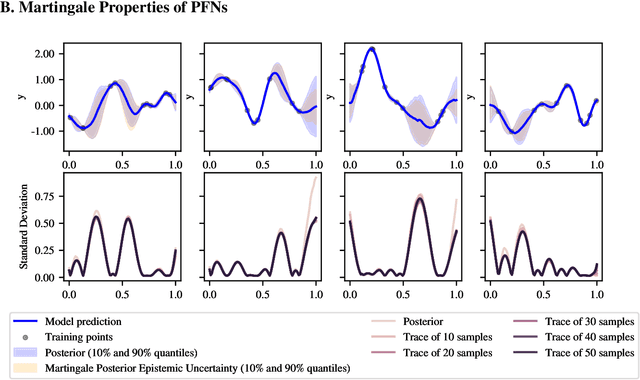
Training neural networks on randomly generated artificial datasets yields Bayesian models that capture the prior defined by the dataset-generating distribution. Prior-data Fitted Networks (PFNs) are a class of methods designed to leverage this insight. In an era of rapidly increasing computational resources for pre-training and a near stagnation in the generation of new real-world data in many applications, PFNs are poised to play a more important role across a wide range of applications. They enable the efficient allocation of pre-training compute to low-data scenarios. Originally applied to small Bayesian modeling tasks, the field of PFNs has significantly expanded to address more complex domains and larger datasets. This position paper argues that PFNs and other amortized inference approaches represent the future of Bayesian inference, leveraging amortized learning to tackle data-scarce problems. We thus believe they are a fruitful area of research. In this position paper, we explore their potential and directions to address their current limitations.
Beyond Black-Box Predictions: Identifying Marginal Feature Effects in Tabular Transformer Networks
Apr 11, 2025In recent years, deep neural networks have showcased their predictive power across a variety of tasks. Beyond natural language processing, the transformer architecture has proven efficient in addressing tabular data problems and challenges the previously dominant gradient-based decision trees in these areas. However, this predictive power comes at the cost of intelligibility: Marginal feature effects are almost completely lost in the black-box nature of deep tabular transformer networks. Alternative architectures that use the additivity constraints of classical statistical regression models can maintain intelligible marginal feature effects, but often fall short in predictive power compared to their more complex counterparts. To bridge the gap between intelligibility and performance, we propose an adaptation of tabular transformer networks designed to identify marginal feature effects. We provide theoretical justifications that marginal feature effects can be accurately identified, and our ablation study demonstrates that the proposed model efficiently detects these effects, even amidst complex feature interactions. To demonstrate the model's predictive capabilities, we compare it to several interpretable as well as black-box models and find that it can match black-box performances while maintaining intelligibility. The source code is available at https://github.com/OpenTabular/NAMpy.
Can Transformers Learn Full Bayesian Inference in Context?
Jan 28, 2025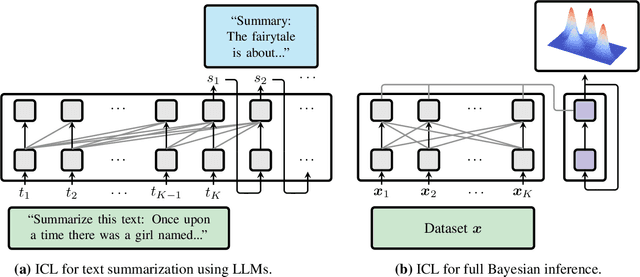
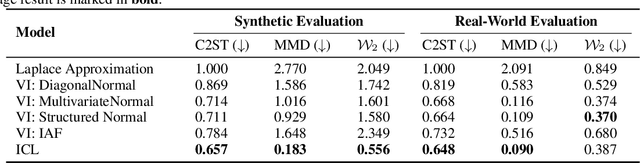
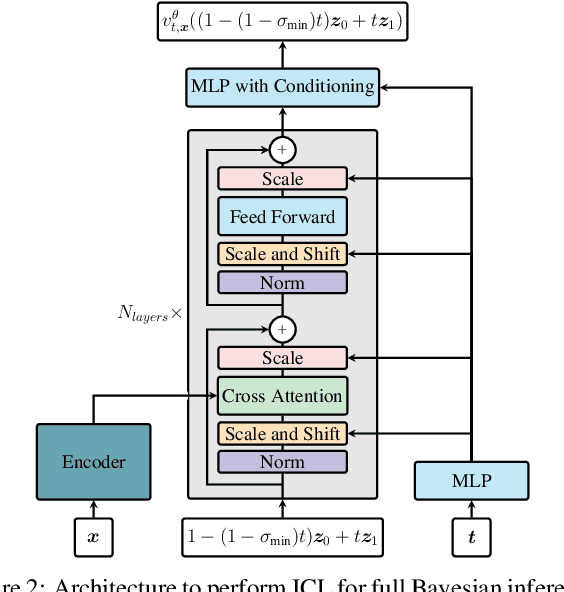

Transformers have emerged as the dominant architecture in the field of deep learning, with a broad range of applications and remarkable in-context learning (ICL) capabilities. While not yet fully understood, ICL has already proved to be an intriguing phenomenon, allowing transformers to learn in context -- without requiring further training. In this paper, we further advance the understanding of ICL by demonstrating that transformers can perform full Bayesian inference for commonly used statistical models in context. More specifically, we introduce a general framework that builds on ideas from prior fitted networks and continuous normalizing flows which enables us to infer complex posterior distributions for methods such as generalized linear models and latent factor models. Extensive experiments on real-world datasets demonstrate that our ICL approach yields posterior samples that are similar in quality to state-of-the-art MCMC or variational inference methods not operating in context.
Mambular: A Sequential Model for Tabular Deep Learning
Aug 12, 2024The analysis of tabular data has traditionally been dominated by gradient-boosted decision trees (GBDTs), known for their proficiency with mixed categorical and numerical features. However, recent deep learning innovations are challenging this dominance. We introduce Mambular, an adaptation of the Mamba architecture optimized for tabular data. We extensively benchmark Mambular against state-of-the-art models, including neural networks and tree-based methods, and demonstrate its competitive performance across diverse datasets. Additionally, we explore various adaptations of Mambular to understand its effectiveness for tabular data. We investigate different pooling strategies, feature interaction mechanisms, and bi-directional processing. Our analysis shows that interpreting features as a sequence and passing them through Mamba layers results in surprisingly performant models. The results highlight Mambulars potential as a versatile and powerful architecture for tabular data analysis, expanding the scope of deep learning applications in this domain. The source code is available at https://github.com/basf/mamba-tabular.
Probabilistic Topic Modelling with Transformer Representations
Mar 06, 2024



Topic modelling was mostly dominated by Bayesian graphical models during the last decade. With the rise of transformers in Natural Language Processing, however, several successful models that rely on straightforward clustering approaches in transformer-based embedding spaces have emerged and consolidated the notion of topics as clusters of embedding vectors. We propose the Transformer-Representation Neural Topic Model (TNTM), which combines the benefits of topic representations in transformer-based embedding spaces and probabilistic modelling. Therefore, this approach unifies the powerful and versatile notion of topics based on transformer embeddings with fully probabilistic modelling, as in models such as Latent Dirichlet Allocation (LDA). We utilize the variational autoencoder (VAE) framework for improved inference speed and modelling flexibility. Experimental results show that our proposed model achieves results on par with various state-of-the-art approaches in terms of embedding coherence while maintaining almost perfect topic diversity. The corresponding source code is available at https://github.com/ArikReuter/TNTM.
GPTopic: Dynamic and Interactive Topic Representations
Mar 06, 2024

Topic modeling seems to be almost synonymous with generating lists of top words to represent topics within large text corpora. However, deducing a topic from such list of individual terms can require substantial expertise and experience, making topic modelling less accessible to people unfamiliar with the particularities and pitfalls of top-word interpretation. A topic representation limited to top-words might further fall short of offering a comprehensive and easily accessible characterization of the various aspects, facets and nuances a topic might have. To address these challenges, we introduce GPTopic, a software package that leverages Large Language Models (LLMs) to create dynamic, interactive topic representations. GPTopic provides an intuitive chat interface for users to explore, analyze, and refine topics interactively, making topic modeling more accessible and comprehensive. The corresponding code is available here: https://github. com/05ec6602be/GPTopic.
Topics in the Haystack: Extracting and Evaluating Topics beyond Coherence
Mar 30, 2023



Extracting and identifying latent topics in large text corpora has gained increasing importance in Natural Language Processing (NLP). Most models, whether probabilistic models similar to Latent Dirichlet Allocation (LDA) or neural topic models, follow the same underlying approach of topic interpretability and topic extraction. We propose a method that incorporates a deeper understanding of both sentence and document themes, and goes beyond simply analyzing word frequencies in the data. This allows our model to detect latent topics that may include uncommon words or neologisms, as well as words not present in the documents themselves. Additionally, we propose several new evaluation metrics based on intruder words and similarity measures in the semantic space. We present correlation coefficients with human identification of intruder words and achieve near-human level results at the word-intrusion task. We demonstrate the competitive performance of our method with a large benchmark study, and achieve superior results compared to state-of-the-art topic modeling and document clustering models.