 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Nov 11, 2025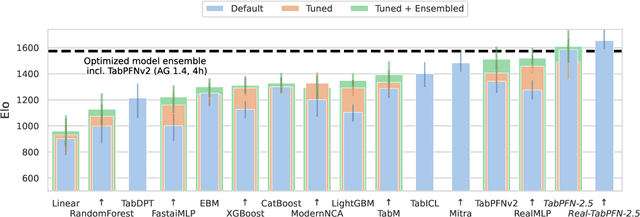
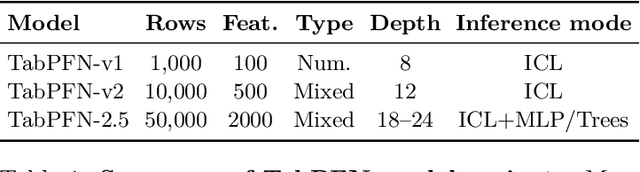
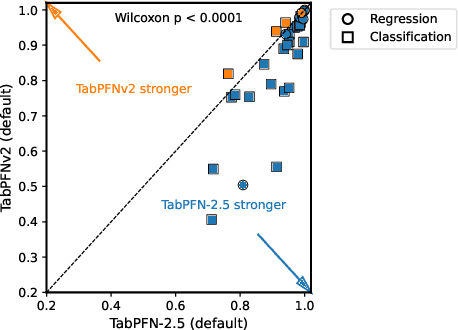
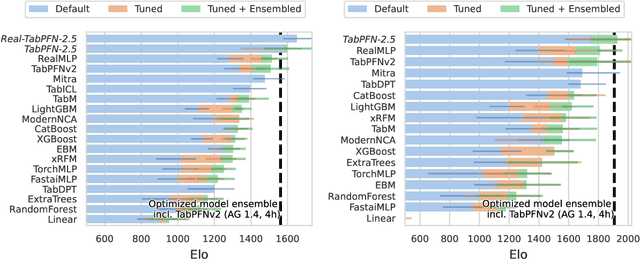
The first tabular foundation model, TabPFN, and its successor TabPFNv2 have impacted tabular AI substantially, with dozens of methods building on it and hundreds of applications across different use cases. This report introduces TabPFN-2.5, the next generation of our tabular foundation model, built for datasets with up to 50,000 data points and 2,000 features, a 20x increase in data cells compared to TabPFNv2. TabPFN-2.5 is now the leading method for the industry standard benchmark TabArena (which contains datasets with up to 100,000 training data points), substantially outperforming tuned tree-based models and matching the accuracy of AutoGluon 1.4, a complex four-hour tuned ensemble that even includes the previous TabPFNv2. Remarkably, default TabPFN-2.5 has a 100% win rate against default XGBoost on small to medium-sized classification datasets (<=10,000 data points, 500 features) and a 87% win rate on larger datasets up to 100K samples and 2K features (85% for regression). For production use cases, we introduce a new distillation engine that converts TabPFN-2.5 into a compact MLP or tree ensemble, preserving most of its accuracy while delivering orders-of-magnitude lower latency and plug-and-play deployment. This new release will immediately strengthen the performance of the many applications and methods already built on the TabPFN ecosystem.
Does TabPFN Understand Causal Structures?
Nov 10, 2025Causal discovery is fundamental for multiple scientific domains, yet extracting causal information from real world data remains a significant challenge. Given the recent success on real data, we investigate whether TabPFN, a transformer-based tabular foundation model pre-trained on synthetic datasets generated from structural causal models, encodes causal information in its internal representations. We develop an adapter framework using a learnable decoder and causal tokens that extract causal signals from TabPFN's frozen embeddings and decode them into adjacency matrices for causal discovery. Our evaluations demonstrate that TabPFN's embeddings contain causal information, outperforming several traditional causal discovery algorithms, with such causal information being concentrated in mid-range layers. These findings establish a new direction for interpretable and adaptable foundation models and demonstrate the potential for leveraging pre-trained tabular models for causal discovery.
FairPFN: A Tabular Foundation Model for Causal Fairness
Jun 08, 2025Machine learning (ML) systems are utilized in critical sectors, such as healthcare, law enforcement, and finance. However, these systems are often trained on historical data that contains demographic biases, leading to ML decisions that perpetuate or exacerbate existing social inequalities. Causal fairness provides a transparent, human-in-the-loop framework to mitigate algorithmic discrimination, aligning closely with legal doctrines of direct and indirect discrimination. However, current causal fairness frameworks hold a key limitation in that they assume prior knowledge of the correct causal model, restricting their applicability in complex fairness scenarios where causal models are unknown or difficult to identify. To bridge this gap, we propose FairPFN, a tabular foundation model pre-trained on synthetic causal fairness data to identify and mitigate the causal effects of protected attributes in its predictions. FairPFN's key contribution is that it requires no knowledge of the causal model and still demonstrates strong performance in identifying and removing protected causal effects across a diverse set of hand-crafted and real-world scenarios relative to robust baseline methods. FairPFN paves the way for promising future research, making causal fairness more accessible to a wider variety of complex fairness problems.
Do-PFN: In-Context Learning for Causal Effect Estimation
Jun 06, 2025Estimation of causal effects is critical to a range of scientific disciplines. Existing methods for this task either require interventional data, knowledge about the ground truth causal graph, or rely on assumptions such as unconfoundedness, restricting their applicability in real-world settings. In the domain of tabular machine learning, Prior-data fitted networks (PFNs) have achieved state-of-the-art predictive performance, having been pre-trained on synthetic data to solve tabular prediction problems via in-context learning. To assess whether this can be transferred to the harder problem of causal effect estimation, we pre-train PFNs on synthetic data drawn from a wide variety of causal structures, including interventions, to predict interventional outcomes given observational data. Through extensive experiments on synthetic case studies, we show that our approach allows for the accurate estimation of causal effects without knowledge of the underlying causal graph. We also perform ablation studies that elucidate Do-PFN's scalability and robustness across datasets with a variety of causal characteristics.
A Human-in-the-Loop Fairness-Aware Model Selection Framework for Complex Fairness Objective Landscapes
Oct 17, 2024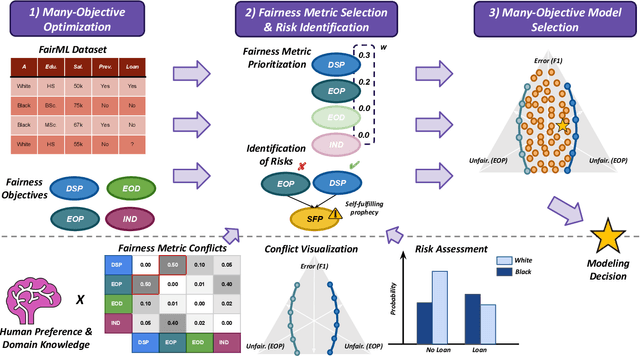
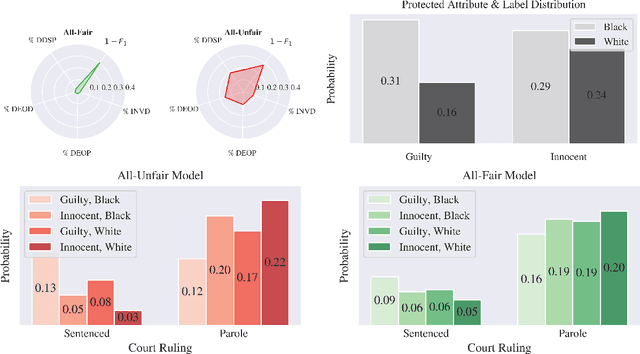

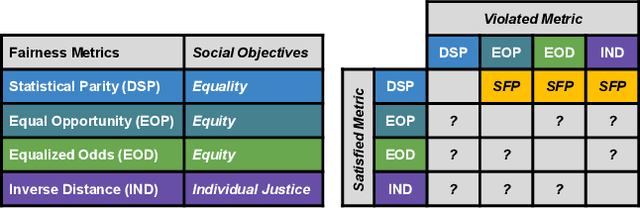
Fairness-aware Machine Learning (FairML) applications are often characterized by complex social objectives and legal requirements, frequently involving multiple, potentially conflicting notions of fairness. Despite the well-known Impossibility Theorem of Fairness and extensive theoretical research on the statistical and socio-technical trade-offs between fairness metrics, many FairML tools still optimize or constrain for a single fairness objective. However, this one-sided optimization can inadvertently lead to violations of other relevant notions of fairness. In this socio-technical and empirical study, we frame fairness as a many-objective (MaO) problem by treating fairness metrics as conflicting objectives. We introduce ManyFairHPO, a human-in-the-loop, fairness-aware model selection framework that enables practitioners to effectively navigate complex and nuanced fairness objective landscapes. ManyFairHPO aids in the identification, evaluation, and balancing of fairness metric conflicts and their related social consequences, leading to more informed and socially responsible model-selection decisions. Through a comprehensive empirical evaluation and a case study on the Law School Admissions problem, we demonstrate the effectiveness of ManyFairHPO in balancing multiple fairness objectives, mitigating risks such as self-fulfilling prophecies, and providing interpretable insights to guide stakeholders in making fairness-aware modeling decisions.
FairPFN: Transformers Can do Counterfactual Fairness
Jul 08, 2024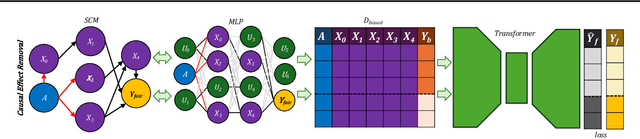
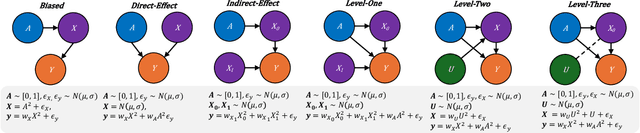
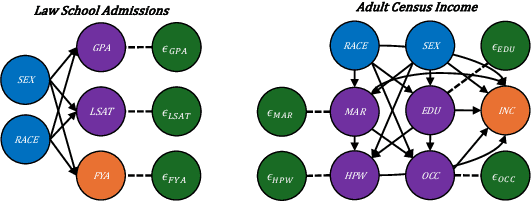
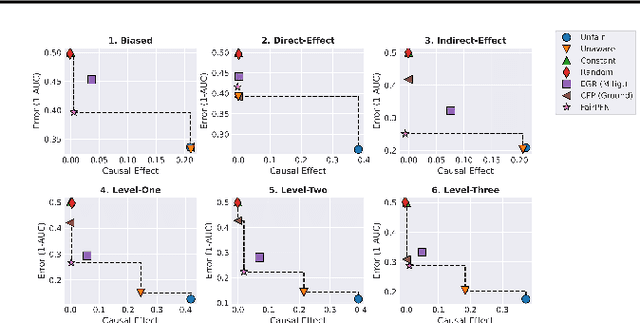
Machine Learning systems are increasingly prevalent across healthcare, law enforcement, and finance but often operate on historical data, which may carry biases against certain demographic groups. Causal and counterfactual fairness provides an intuitive way to define fairness that closely aligns with legal standards. Despite its theoretical benefits, counterfactual fairness comes with several practical limitations, largely related to the reliance on domain knowledge and approximate causal discovery techniques in constructing a causal model. In this study, we take a fresh perspective on counterfactually fair prediction, building upon recent work in in context learning (ICL) and prior fitted networks (PFNs) to learn a transformer called FairPFN. This model is pretrained using synthetic fairness data to eliminate the causal effects of protected attributes directly from observational data, removing the requirement of access to the correct causal model in practice. In our experiments, we thoroughly assess the effectiveness of FairPFN in eliminating the causal impact of protected attributes on a series of synthetic case studies and real world datasets. Our findings pave the way for a new and promising research area: transformers for causal and counterfactual fairness.