 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Uniform to Learned Knots: A Study of Spline-Based Numerical Encodings for Tabular Deep Learning
Apr 07, 2026Numerical preprocessing remains an important component of tabular deep learning, where the representation of continuous features can strongly affect downstream performance. Although its importance is well established for classical statistical and machine learning models, the role of explicit numerical preprocessing in tabular deep learning remains less well understood. In this work, we study this question with a focus on spline-based numerical encodings. We investigate three spline families for encoding numerical features, namely B-splines, M-splines, and integrated splines (I-splines), under uniform, quantile-based, target-aware, and learnable-knot placement. For the learnable-knot variants, we use a differentiable knot parameterization that enables stable end-to-end optimization of knot locations jointly with the backbone. We evaluate these encodings on a diverse collection of public regression and classification datasets using MLP, ResNet, and FT-Transformer backbones, and compare them against common numerical preprocessing baselines. Our results show that the effect of numerical encodings depends strongly on the task, output size, and backbone. For classification, piecewise-linear encoding (PLE) is the most robust choice overall, while spline-based encodings remain competitive. For regression, no single encoding dominates uniformly. Instead, performance depends on the spline family, knot-placement strategy, and output size, with larger gains typically observed for MLP and ResNet than for FT-Transformer. We further find that learnable-knot variants can be optimized stably under the proposed parameterization, but may substantially increase training cost, especially for M-spline and I-spline expansions. Overall, the results show that numerical encodings should be assessed not only in terms of predictive performance, but also in terms of computational overhead.
Sublinear-Time Reconfiguration of Programmable Matter with Joint Movements
Mar 11, 2026We study centralized reconfiguration problems for geometric amoebot structures. A set of $n$ amoebots occupy nodes on the triangular grid and can reconfigure via expansion and contraction operations. We focus on the joint movement extension, where amoebots may expand and contract in parallel, enabling coordinated motion of larger substructures. Prior work introduced this extension and analyzed reconfiguration under additional assumptions such as metamodules. In contrast, we investigate the intrinsic dynamics of reconfiguration without such assumptions by restricting attention to centralized algorithms, leaving distributed solutions for future work. We study the reconfiguration problem between two classes of amoebot structures $A$ and $B$: For every structure $S\in A$, the goal is to compute a schedule that reconfigures $S$ into some structure $S'\in B$. Our focus is on sublinear-time algorithms. We affirmatively answer the open problem by Padalkin et al. (Auton. Robots, 2025) whether a within-the-model sublinear-time universal reconfiguration algorithm is possible, by proving that any structure can be reconfigured into a canonical line-segment structure in $O(\sqrt{n}\log n)$ rounds. Additionally, we give a constant-time algorithm for reconfiguring any spiral structure into a line segment. These results are enabled by new constant-time primitives that facilitate efficient parallel movement. Our findings demonstrate that the joint movement model supports sublinear reconfiguration without auxiliary assumptions. A central open question is whether universal reconfiguration within this model can be achieved in polylogarithmic or even constant time.
Towards Human-AI Accessibility Mapping in India: VLM-Guided Annotations and POI-Centric Analysis in Chandigarh
Feb 17, 2026Project Sidewalk is a web-based platform that enables crowdsourcing accessibility of sidewalks at city-scale by virtually walking through city streets using Google Street View. The tool has been used in 40 cities across the world, including the US, Mexico, Chile, and Europe. In this paper, we describe adaptation efforts to enable deployment in Chandigarh, India, including modifying annotation types, provided examples, and integrating VLM-based mission guidance, which adapts instructions based on a street scene and metadata analysis. Our evaluation with 3 annotators indicates the utility of AI-mission guidance with an average score of 4.66. Using this adapted Project Sidewalk tool, we conduct a Points of Interest (POI)-centric accessibility analysis for three sectors in Chandigarh with very different land uses, residential, commercial and institutional covering about 40 km of sidewalks. Across 40 km of roads audited in three sectors and around 230 POIs, we identified 1,644 of 2,913 locations where infrastructure improvements could enhance accessibility.
Continuous Fairness On Data Streams
Jan 13, 2026We study the problem of enforcing continuous group fairness over windows in data streams. We propose a novel fairness model that ensures group fairness at a finer granularity level (referred to as block) within each sliding window. This formulation is particularly useful when the window size is large, making it desirable to enforce fairness at a finer granularity. Within this framework, we address two key challenges: efficiently monitoring whether each sliding window satisfies block-level group fairness, and reordering the current window as effectively as possible when fairness is violated. To enable real-time monitoring, we design sketch-based data structures that maintain attribute distributions with minimal overhead. We also develop optimal, efficient algorithms for the reordering task, supported by rigorous theoretical guarantees. Our evaluation on four real-world streaming scenarios demonstrates the practical effectiveness of our approach. We achieve millisecond-level processing and a throughput of approximately 30,000 queries per second on average, depending on system parameters. The stream reordering algorithm improves block-level group fairness by up to 95% in certain cases, and by 50-60% on average across datasets. A qualitative study further highlights the advantages of block-level fairness compared to window-level fairness.
LLM-Augmented Changepoint Detection: A Framework for Ensemble Detection and Automated Explanation
Jan 06, 2026This paper introduces a novel changepoint detection framework that combines ensemble statistical methods with Large Language Models (LLMs) to enhance both detection accuracy and the interpretability of regime changes in time series data. Two critical limitations in the field are addressed. First, individual detection methods exhibit complementary strengths and weaknesses depending on data characteristics, making method selection non-trivial and prone to suboptimal results. Second, automated, contextual explanations for detected changes are largely absent. The proposed ensemble method aggregates results from ten distinct changepoint detection algorithms, achieving superior performance and robustness compared to individual methods. Additionally, an LLM-powered explanation pipeline automatically generates contextual narratives, linking detected changepoints to potential real-world historical events. For private or domain-specific data, a Retrieval-Augmented Generation (RAG) solution enables explanations grounded in user-provided documents. The open source Python framework demonstrates practical utility in diverse domains, including finance, political science, and environmental science, transforming raw statistical output into actionable insights for analysts and decision-makers.
Optimal Dispersion Under Asynchrony
Jul 02, 2025We study the dispersion problem in anonymous port-labeled graphs: $k \leq n$ mobile agents, each with a unique ID and initially located arbitrarily on the nodes of an $n$-node graph with maximum degree $\Delta$, must autonomously relocate so that no node hosts more than one agent. Dispersion serves as a fundamental task in distributed computing of mobile agents, and its complexity stems from key challenges in local coordination under anonymity and limited memory. The goal is to minimize both the time to achieve dispersion and the memory required per agent. It is known that any algorithm requires $\Omega(k)$ time in the worst case, and $\Omega(\log k)$ bits of memory per agent. A recent result [SPAA'25] gives an optimal $O(k)$-time algorithm in the synchronous setting and an $O(k \log k)$-time algorithm in the asynchronous setting, both using $O(\log(k+\Delta))$ bits. In this paper, we close the complexity gap in the asynchronous setting by presenting the first dispersion algorithm that runs in optimal $O(k)$ time using $O(\log(k+\Delta))$ bits of memory per agent. Our solution is based on a novel technique we develop in this paper that constructs a port-one tree in anonymous graphs, which may be of independent interest.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
Dispersion is (Almost) Optimal under (A)synchrony
Mar 20, 2025
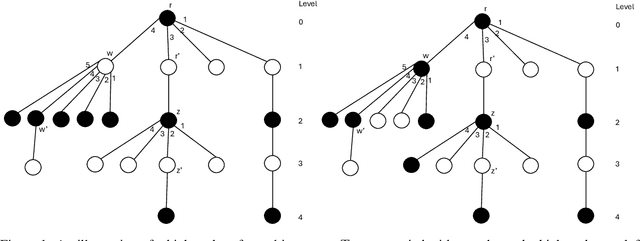
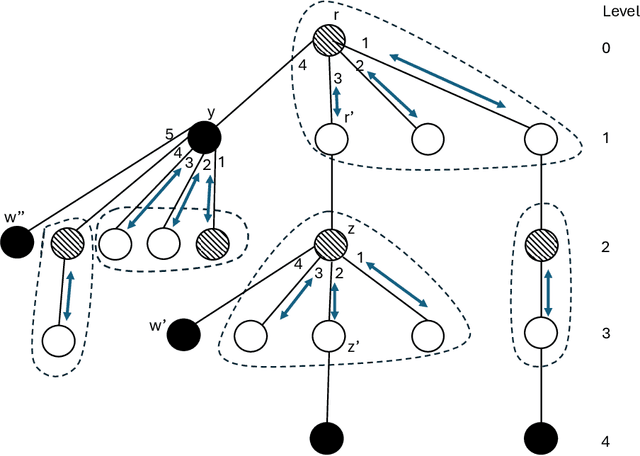
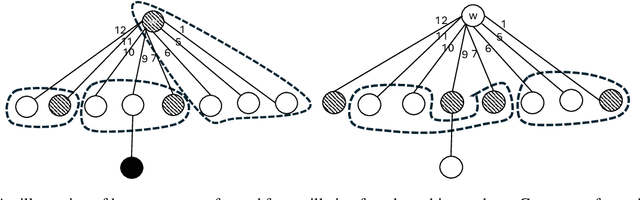
The dispersion problem has received much attention recently in the distributed computing literature. In this problem, $k\leq n$ agents placed initially arbitrarily on the nodes of an $n$-node, $m$-edge anonymous graph of maximum degree $\Delta$ have to reposition autonomously to reach a configuration in which each agent is on a distinct node of the graph. Dispersion is interesting as well as important due to its connections to many fundamental coordination problems by mobile agents on graphs, such as exploration, scattering, load balancing, relocation of self-driven electric cars (robots) to recharge stations (nodes), etc. The objective has been to provide a solution that optimizes simultaneously time and memory complexities. There exist graphs for which the lower bound on time complexity is $\Omega(k)$. Memory complexity is $\Omega(\log k)$ per agent independent of graph topology. The state-of-the-art algorithms have (i) time complexity $O(k\log^2k)$ and memory complexity $O(\log(k+\Delta))$ under the synchronous setting [DISC'24] and (ii) time complexity $O(\min\{m,k\Delta\})$ and memory complexity $O(\log(k+\Delta))$ under the asynchronous setting [OPODIS'21]. In this paper, we improve substantially on this state-of-the-art. Under the synchronous setting as in [DISC'24], we present the first optimal $O(k)$ time algorithm keeping memory complexity $O(\log (k+\Delta))$. Under the asynchronous setting as in [OPODIS'21], we present the first algorithm with time complexity $O(k\log k)$ keeping memory complexity $O(\log (k+\Delta))$, which is time-optimal within an $O(\log k)$ factor despite asynchrony. Both results were obtained through novel techniques to quickly find empty nodes to settle agents, which may be of independent interest.
Hybrid Fingerprint-based Positioning in Cell-Free Massive MIMO Systems
Feb 04, 2025



Recently, there has been an increasing interest in 6G technology for integrated sensing and communications, where positioning stands out as a key application. In the realm of 6G, cell-free massive multiple-input multiple-output (MIMO) systems, featuring distributed base stations equipped with a large number of antennas, present an abundant source of angle-of-arrival (AOA) information that could be exploited for positioning applications. In this paper we leverage this AOA information at the base stations using the multiple signal classification (MUSIC) algorithm, in conjunction with received signal strength (RSS) for positioning through Gaussian process regression (GPR). An AOA fingerprint database is constructed by capturing the angle data from multiple locations across the network area and is combined with RSS data from the same locations to form a hybrid fingerprint which is then used to train a GPR model employing a squared exponential kernel. The trained regression model is subsequently utilized to estimate the location of a user equipment. Simulations demonstrate that the GPR model with hybrid input achieves better positioning accuracy than traditional GPR models utilizing RSS-only and AOA-only inputs.
Robot Swarming over the internet
Nov 06, 2024
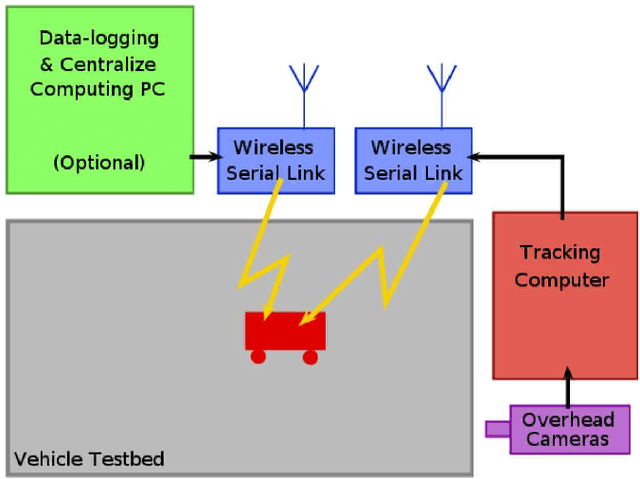

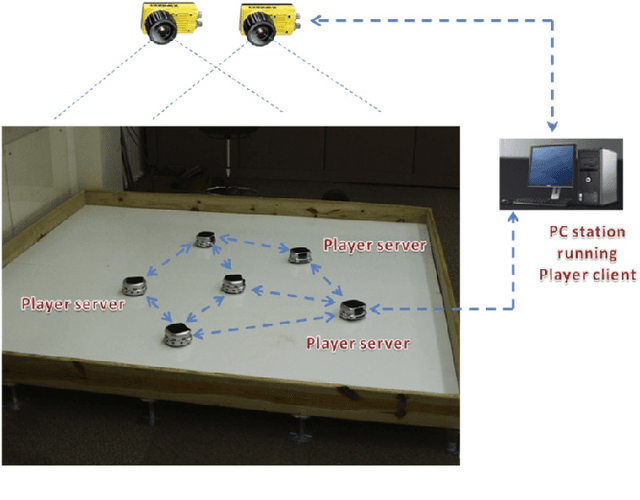
This paper considers cooperative control of robots involving two different testbed systems in remote locations with communication on the internet. This provides us the capability to exchange robots status like positions, velocities and directions needed for the swarming algorithm. The results show that all robots properly follow some leader defined one of the testbeds. Measurement of data exchange rates show no loss of packets, and average transfer delays stay within tolerance limits for practical applications. In our knowledge, the novelty of this paper concerns this kind of control over a large network like internet.