 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint UAV Placement and Transceiver Design in Multi-User Wireless Relay Networks
Jul 16, 2025In this paper, a novel approach is proposed to improve the minimum signal-to-interference-plus-noise-ratio (SINR) among users in non-orthogonal multi-user wireless relay networks, by optimizing the placement of unmanned aerial vehicle (UAV) relays, relay beamforming, and receive combining. The design is separated into two problems: beamforming-aware UAV placement optimization and transceiver design for minimum SINR maximization. A significant challenge in beamforming-aware UAV placement optimization is the lack of instantaneous channel state information (CSI) prior to deploying UAV relays, making it difficult to derive the beamforming SINR in non-orthogonal multi-user transmission. To address this issue, an approximation of the expected beamforming SINR is derived using the narrow beam property of a massive MIMO base station. Based on this, a UAV placement algorithm is proposed to provide UAV positions that improve the minimum expected beamforming SINR among users, using a difference-of-convex framework. Subsequently, after deploying the UAV relays to the optimized positions, and with estimated CSI available, a joint relay beamforming and receive combining (JRBC) algorithm is proposed to optimize the transceiver to improve the minimum beamforming SINR among users, using a block-coordinate descent approach. Numerical results show that the UAV placement algorithm combined with the JRBC algorithm provides a 4.6 dB SINR improvement over state-of-the-art schemes.
Unified Analysis of Decentralized Gradient Descent: a Contraction Mapping Framework
Mar 18, 2025The decentralized gradient descent (DGD) algorithm, and its sibling, diffusion, are workhorses in decentralized machine learning, distributed inference and estimation, and multi-agent coordination. We propose a novel, principled framework for the analysis of DGD and diffusion for strongly convex, smooth objectives, and arbitrary undirected topologies, using contraction mappings coupled with a result called the mean Hessian theorem (MHT). The use of these tools yields tight convergence bounds, both in the noise-free and noisy regimes. While these bounds are qualitatively similar to results found in the literature, our approach using contractions together with the MHT decouples the algorithm dynamics (how quickly the algorithm converges to its fixed point) from its asymptotic convergence properties (how far the fixed point is from the global optimum). This yields a simple, intuitive analysis that is accessible to a broader audience. Extensions are provided to multiple local gradient updates, time-varying step sizes, noisy gradients (stochastic DGD and diffusion), communication noise, and random topologies.
Hybrid Fingerprint-based Positioning in Cell-Free Massive MIMO Systems
Feb 04, 2025



Recently, there has been an increasing interest in 6G technology for integrated sensing and communications, where positioning stands out as a key application. In the realm of 6G, cell-free massive multiple-input multiple-output (MIMO) systems, featuring distributed base stations equipped with a large number of antennas, present an abundant source of angle-of-arrival (AOA) information that could be exploited for positioning applications. In this paper we leverage this AOA information at the base stations using the multiple signal classification (MUSIC) algorithm, in conjunction with received signal strength (RSS) for positioning through Gaussian process regression (GPR). An AOA fingerprint database is constructed by capturing the angle data from multiple locations across the network area and is combined with RSS data from the same locations to form a hybrid fingerprint which is then used to train a GPR model employing a squared exponential kernel. The trained regression model is subsequently utilized to estimate the location of a user equipment. Simulations demonstrate that the GPR model with hybrid input achieves better positioning accuracy than traditional GPR models utilizing RSS-only and AOA-only inputs.
Propagation Measurements and Analyses at 28 GHz via an Autonomous Beam-Steering Platform
Feb 16, 2023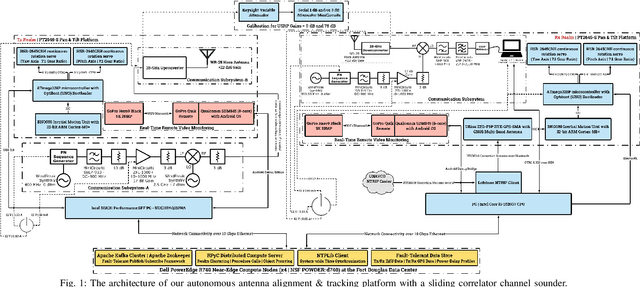

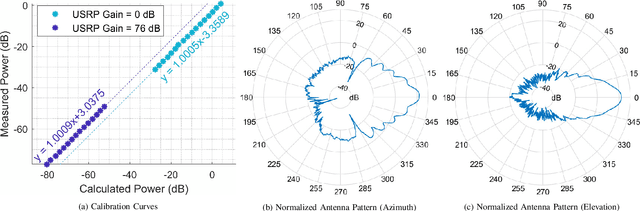

This paper details the design of an autonomous alignment and tracking platform to mechanically steer directional horn antennas in a sliding correlator channel sounder setup for 28 GHz V2X propagation modeling. A pan-and-tilt subsystem facilitates uninhibited rotational mobility along the yaw and pitch axes, driven by open-loop servo units and orchestrated via inertial motion controllers. A geo-positioning subsystem augmented in accuracy by real-time kinematics enables navigation events to be shared between a transmitter and receiver over an Apache Kafka messaging middleware framework with fault tolerance. Herein, our system demonstrates a 3D geo-positioning accuracy of 17 cm, an average principal axes positioning accuracy of 1.1 degrees, and an average tracking response time of 27.8 ms. Crucially, fully autonomous antenna alignment and tracking facilitates continuous series of measurements, a unique yet critical necessity for millimeter wave channel modeling in vehicular networks. The power-delay profiles, collected along routes spanning urban and suburban neighborhoods on the NSF POWDER testbed, are used in pathloss evaluations involving the 3GPP TR38.901 and ITU-R M.2135 standards. Empirically, we demonstrate that these models fail to accurately capture the 28 GHz pathloss behavior in urban foliage and suburban radio environments. In addition to RMS direction-spread analyses for angles-of-arrival via the SAGE algorithm, we perform signal decoherence studies wherein we derive exponential models for the spatial/angular autocorrelation coefficient under distance and alignment effects.
Non-Coherent Over-the-Air Decentralized Stochastic Gradient Descent
Nov 19, 2022This paper proposes a Decentralized Stochastic Gradient Descent (DSGD) algorithm to solve distributed machine-learning tasks over wirelessly-connected systems, without the coordination of a base station. It combines local stochastic gradient descent steps with a Non-Coherent Over-The-Air (NCOTA) consensus scheme at the receivers, that enables concurrent transmissions by leveraging the waveform superposition properties of the wireless channels. With NCOTA, local optimization signals are mapped to a mixture of orthogonal preamble sequences and transmitted concurrently over the wireless channel under half-duplex constraints. Consensus is estimated by non-coherently combining the received signals with the preamble sequences and mitigating the impact of noise and fading via a consensus stepsize. NCOTA-DSGD operates without channel state information (typically used in over-the-air computation schemes for channel inversion) and leverages the channel pathloss to mix signals, without explicit knowledge of the mixing weights (typically known in consensus-based optimization). It is shown that, with a suitable tuning of decreasing consensus and learning stepsizes, the error (measured as Euclidean distance) between the local and globally optimum models vanishes with rate $\mathcal O(k^{-1/4})$ after $k$ iterations. NCOTA-DSGD is evaluated numerically by solving an image classification task on the MNIST dataset, cast as a regularized cross-entropy loss minimization. Numerical results depict faster convergence vis-\`a-vis running time than implementations of the classical DSGD algorithm over digital and analog orthogonal channels, when the number of learning devices is large, under stringent delay constraints.
Multiscale Adaptive Scheduling and Path-Planning for Power-Constrained UAV-Relays via SMDPs
Sep 16, 2022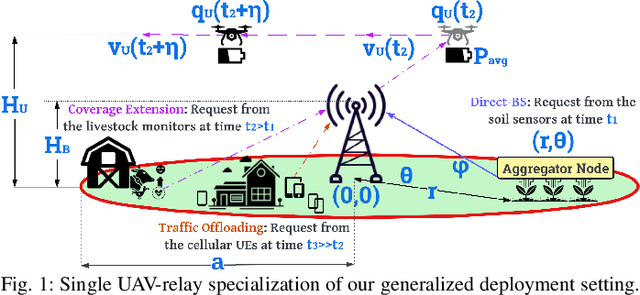
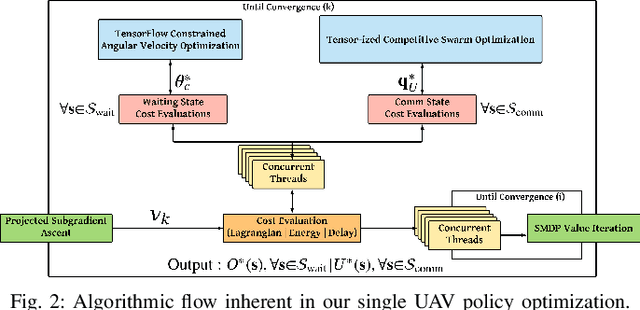


We describe the orchestration of a decentralized swarm of rotary-wing UAV-relays, augmenting the coverage and service capabilities of a terrestrial base station. Our goal is to minimize the time-average service latencies involved in handling transmission requests from ground users under Poisson arrivals, subject to an average UAV power constraint. Equipped with rate adaptation to efficiently leverage air-to-ground channel stochastics, we first derive the optimal control policy for a single relay via a semi-Markov decision process formulation, with competitive swarm optimization for UAV trajectory design. Accordingly, we detail a multiscale decomposition of this construction: outer decisions on radial wait velocities and end positions optimize the expected long-term delay-power trade-off; consequently, inner decisions on angular wait velocities, service schedules, and UAV trajectories greedily minimize the instantaneous delay-power costs. Next, generalizing to UAV swarms via replication and consensus-driven command-and-control, this policy is embedded with spread maximization and conflict resolution heuristics. We demonstrate that our framework offers superior performance vis-\`a-vis average service latencies and average per-UAV power consumption: 11x faster data payload delivery relative to static UAV-relay deployments and 2x faster than a deep-Q network solution; remarkably, one relay with our scheme outclasses three relays under a joint successive convex approximation policy by 62%.
Parallel Successive Learning for Dynamic Distributed Model Training over Heterogeneous Wireless Networks
Feb 12, 2022


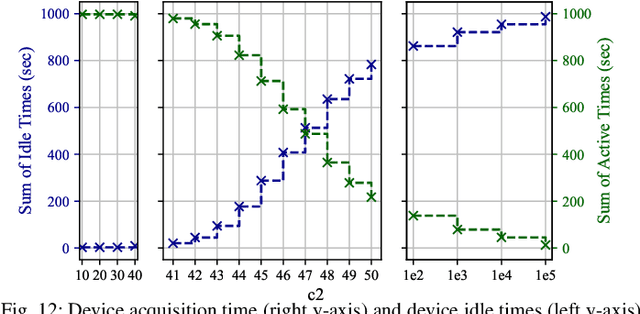
Federated learning (FedL) has emerged as a popular technique for distributing model training over a set of wireless devices, via iterative local updates (at devices) and global aggregations (at the server). In this paper, we develop parallel successive learning (PSL), which expands the FedL architecture along three dimensions: (i) Network, allowing decentralized cooperation among the devices via device-to-device (D2D) communications. (ii) Heterogeneity, interpreted at three levels: (ii-a) Learning: PSL considers heterogeneous number of stochastic gradient descent iterations with different mini-batch sizes at the devices; (ii-b) Data: PSL presumes a dynamic environment with data arrival and departure, where the distributions of local datasets evolve over time, captured via a new metric for model/concept drift. (ii-c) Device: PSL considers devices with different computation and communication capabilities. (iii) Proximity, where devices have different distances to each other and the access point. PSL considers the realistic scenario where global aggregations are conducted with idle times in-between them for resource efficiency improvements, and incorporates data dispersion and model dispersion with local model condensation into FedL. Our analysis sheds light on the notion of cold vs. warmed up models, and model inertia in distributed machine learning. We then propose network-aware dynamic model tracking to optimize the model learning vs. resource efficiency tradeoff, which we show is an NP-hard signomial programming problem. We finally solve this problem through proposing a general optimization solver. Our numerical results reveal new findings on the interdependencies between the idle times in-between the global aggregations, model/concept drift, and D2D cooperation configuration.
Dual-Wideband Time-Varying Sub-Terahertz Massive MIMO Systems: A Compressed Training Framework
Jan 04, 2022
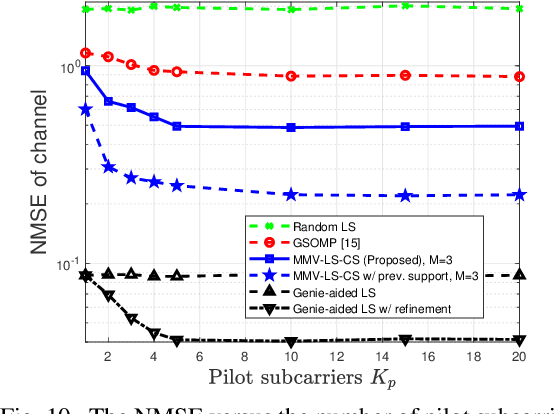
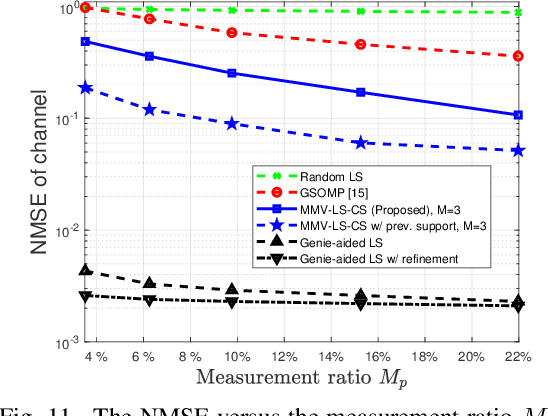
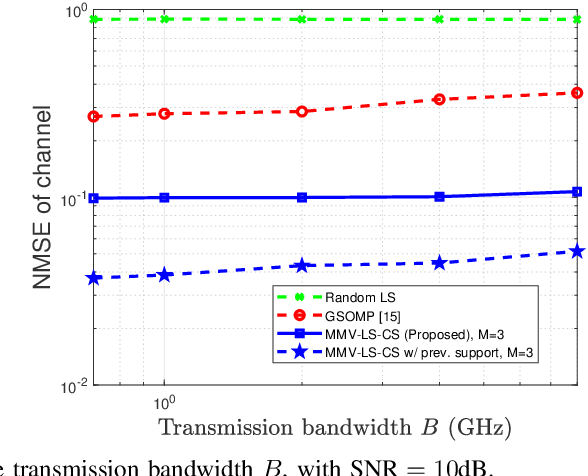
Designers of beyond-5G systems are planning to use new frequencies in the millimeter wave (mmWave) and sub-terahertz (sub-THz) bands to meet ever-increasing demand for wireless broadband access. Sub-THz communication, however, will come with many challenges of mmWave communication and new challenges associated with the wider bandwidths, larger numbers of antennas and harsher propagation characteristics. Notably the frequency- and spatial-wideband (dual-wideband) effects are significant at sub-THz. To address these challenges, this paper presents a compressed training framework to estimate the sub-THz time-varying MIMO-OFDM channels. A set of frequency-dependent array response matrices are constructed, enabling the channel recovery from multiple observations across subcarriers via multiple measurement vectors (MMV). Capitalizing on the temporal correlation, MMV least squares (MMV-LS) is designed to estimate the channel on the previous beam index support, followed by MMV compressed sensing (MMV-CS) on the residual signal to estimate the time-varying channel components. Furthermore, a channel refinement algorithm is proposed to estimate the path coefficients and time delays of the dominant paths. To reduce the computational complexity, a sequential search method using hierarchical codebooks is proposed for greedy beam selection. Numerical results show that MMV-LS-CS achieves a more accurate and robust channel estimation than state-of-the-art algorithms on time-varying dual-wideband MIMO-OFDM.
Resource-Efficient and Delay-Aware Federated Learning Design under Edge Heterogeneity
Jan 03, 2022
Federated learning (FL) has emerged as a popular methodology for distributing machine learning across wireless edge devices. In this work, we consider optimizing the tradeoff between model performance and resource utilization in FL, under device-server communication delays and device computation heterogeneity. Our proposed StoFedDelAv algorithm incorporates a local-global model combiner into the FL synchronization step. We theoretically characterize the convergence behavior of StoFedDelAv and obtain the optimal combiner weights, which consider the global model delay and expected local gradient error at each device. We then formulate a network-aware optimization problem which tunes the minibatch sizes of the devices to jointly minimize energy consumption and machine learning training loss, and solve the non-convex problem through a series of convex approximations. Our simulations reveal that StoFedDelAv outperforms the current art in FL in terms of model convergence speed and network resource utilization when the minibatch size and the combiner weights are adjusted. Additionally, our method can reduce the number of uplink communication rounds required during the model training period to reach the same accuracy.
A Robotic Antenna Alignment and Tracking System for Millimeter Wave Propagation Modeling
Oct 14, 2021

In this paper, we discuss the design of a sliding-correlator channel sounder for 28 GHz propagation modeling on the NSF POWDER testbed in Salt Lake City, UT. Beam-alignment is mechanically achieved via a fully autonomous robotic antenna tracking platform, designed using commercial off-the-shelf components. Equipped with an Apache Zookeeper/Kafka managed fault-tolerant publish-subscribe framework, we demonstrate tracking response times of 27.8 ms, in addition to superior scalability over state-of-the-art mechanical beam-steering systems. Enhanced with real-time kinematic correction streams, our geo-positioning subsystem achieves a 3D accuracy of 17 cm, while our principal axes positioning subsystem achieves an average accuracy of 1.1 degrees across yaw and pitch movements. Finally, by facilitating remote orchestration (via managed containers), uninhibited rotation (via encapsulation), and real-time positioning visualization (via Dash/MapBox), we exhibit a proven prototype well-suited for V2X measurements.