 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Successive Learning for Dynamic Distributed Model Training over Heterogeneous Wireless Networks
Paper and Code
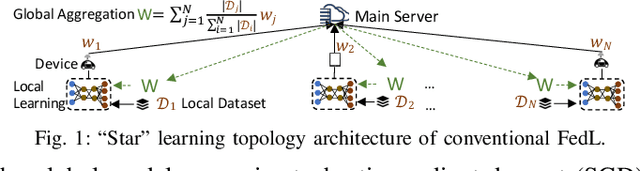


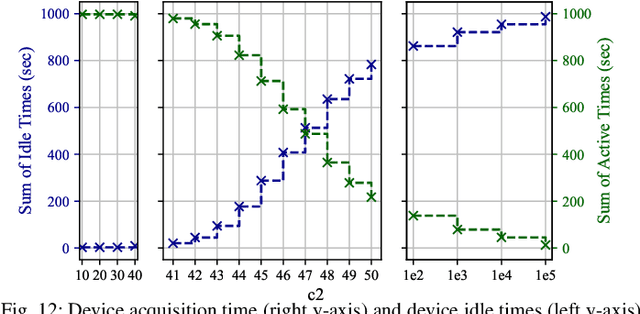
Federated learning (FedL) has emerged as a popular technique for distributing model training over a set of wireless devices, via iterative local updates (at devices) and global aggregations (at the server). In this paper, we develop parallel successive learning (PSL), which expands the FedL architecture along three dimensions: (i) Network, allowing decentralized cooperation among the devices via device-to-device (D2D) communications. (ii) Heterogeneity, interpreted at three levels: (ii-a) Learning: PSL considers heterogeneous number of stochastic gradient descent iterations with different mini-batch sizes at the devices; (ii-b) Data: PSL presumes a dynamic environment with data arrival and departure, where the distributions of local datasets evolve over time, captured via a new metric for model/concept drift. (ii-c) Device: PSL considers devices with different computation and communication capabilities. (iii) Proximity, where devices have different distances to each other and the access point. PSL considers the realistic scenario where global aggregations are conducted with idle times in-between them for resource efficiency improvements, and incorporates data dispersion and model dispersion with local model condensation into FedL. Our analysis sheds light on the notion of cold vs. warmed up models, and model inertia in distributed machine learning. We then propose network-aware dynamic model tracking to optimize the model learning vs. resource efficiency tradeoff, which we show is an NP-hard signomial programming problem. We finally solve this problem through proposing a general optimization solver. Our numerical results reveal new findings on the interdependencies between the idle times in-between the global aggregations, model/concept drift, and D2D cooperation configuration.