 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal RIS Placement in a Multi-User MISO System with User Randomness
Nov 06, 2025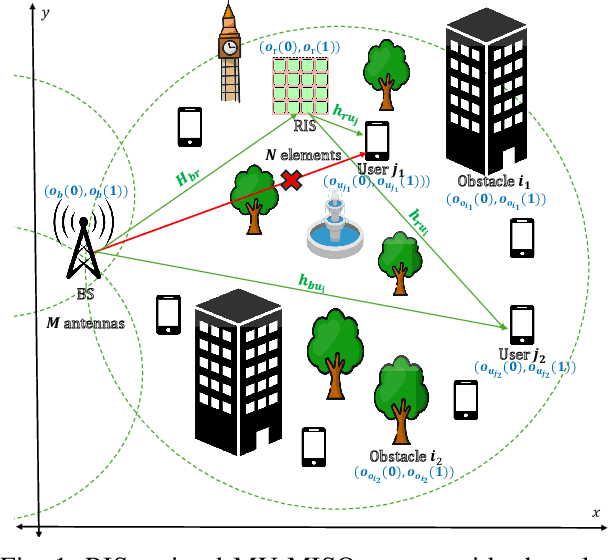
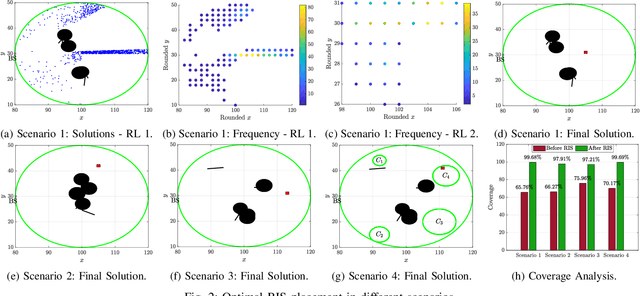
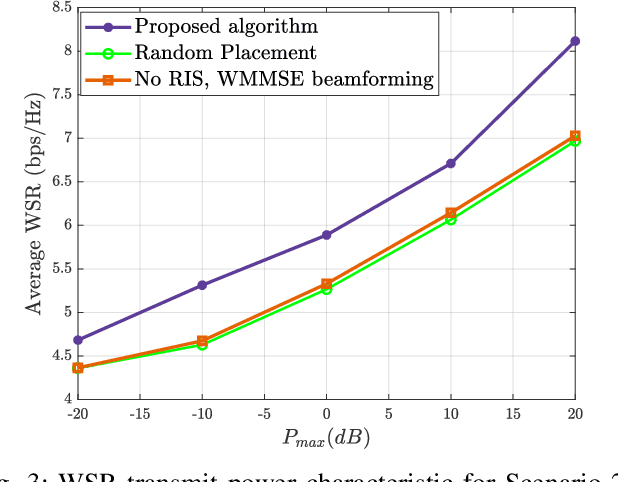
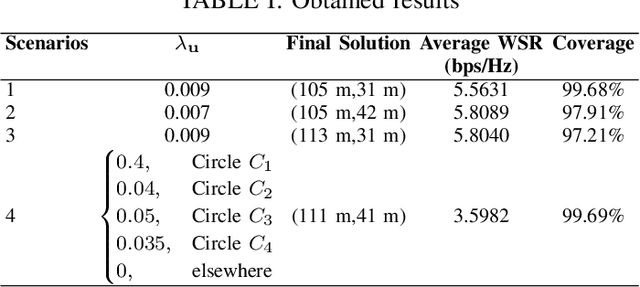
It is well established that the performance of reconfigurable intelligent surface (RIS)-assisted systems critically depends on the optimal placement of the RIS. Previous works consider either simple coverage maximization or simultaneous optimization of the placement of the RIS along with the beamforming and reflection coefficients, most of which assume that the location of the RIS, base station (BS), and users are known. However, in practice, only the spatial variation of user density and obstacle configuration are likely to be known prior to deployment of the system. Thus, we formulate a non-convex problem that optimizes the position of the RIS over the expected minimum signal-to-interference-plus-noise ratio (SINR) of the system with user randomness, assuming that the system employs joint beamforming after deployment. To solve this problem, we propose a recursive coarse-to-fine methodology that constructs a set of candidate locations for RIS placement based on the obstacle configuration and evaluates them over multiple instantiations from the user distribution. The search is recursively refined within the optimal region identified in each stage to determine the final optimal region for RIS deployment. Numerical results are presented to corroborate our findings.
Coherence-Aware Distributed Learning under Heterogeneous Downlink Impairments
Oct 29, 2025The performance of federated learning (FL) over wireless networks critically depends on accurate and timely channel state information (CSI) across distributed devices. This requirement is tightly linked to how rapidly the channel gains vary, i.e., the coherence intervals. In practice, edge devices often exhibit unequal coherence times due to differences in mobility and scattering environments, leading to unequal demands for pilot signaling and channel estimation resources. Conventional FL schemes that overlook this coherence disparity can suffer from severe communication inefficiencies and training overhead. This paper proposes a coherence-aware, communication-efficient framework for joint channel training and model updating in practical wireless FL systems operating under heterogeneous fading dynamics. Focusing on downlink impairments, we introduce a resource-reuse strategy based on product superposition, enabling the parameter server to efficiently schedule both static and dynamic devices by embedding global model updates for static devices within pilot transmissions intended for mobile devices. We theoretically analyze the convergence behavior of the proposed scheme and quantify its gains in expected communication efficiency and training accuracy. Experiments demonstrate the effectiveness of the proposed framework under mobility-induced dynamics and offer useful insights for the practical deployment of FL over wireless channels.
Joint UAV Placement and Transceiver Design in Multi-User Wireless Relay Networks
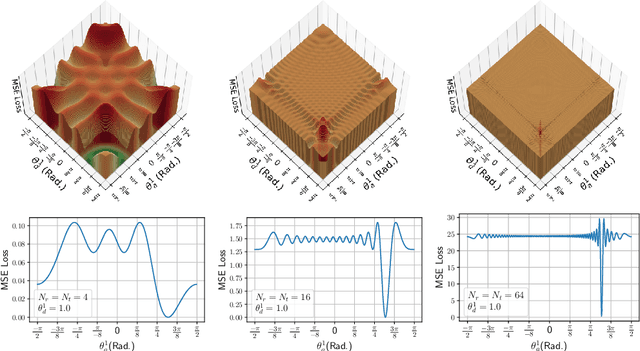
Jul 16, 2025In this paper, a novel approach is proposed to improve the minimum signal-to-interference-plus-noise-ratio (SINR) among users in non-orthogonal multi-user wireless relay networks, by optimizing the placement of unmanned aerial vehicle (UAV) relays, relay beamforming, and receive combining. The design is separated into two problems: beamforming-aware UAV placement optimization and transceiver design for minimum SINR maximization. A significant challenge in beamforming-aware UAV placement optimization is the lack of instantaneous channel state information (CSI) prior to deploying UAV relays, making it difficult to derive the beamforming SINR in non-orthogonal multi-user transmission. To address this issue, an approximation of the expected beamforming SINR is derived using the narrow beam property of a massive MIMO base station. Based on this, a UAV placement algorithm is proposed to provide UAV positions that improve the minimum expected beamforming SINR among users, using a difference-of-convex framework. Subsequently, after deploying the UAV relays to the optimized positions, and with estimated CSI available, a joint relay beamforming and receive combining (JRBC) algorithm is proposed to optimize the transceiver to improve the minimum beamforming SINR among users, using a block-coordinate descent approach. Numerical results show that the UAV placement algorithm combined with the JRBC algorithm provides a 4.6 dB SINR improvement over state-of-the-art schemes.
Privacy-Preserving Quantized Federated Learning with Diverse Precision
Jul 01, 2025Federated learning (FL) has emerged as a promising paradigm for distributed machine learning, enabling collaborative training of a global model across multiple local devices without requiring them to share raw data. Despite its advancements, FL is limited by factors such as: (i) privacy risks arising from the unprotected transmission of local model updates to the fusion center (FC) and (ii) decreased learning utility caused by heterogeneity in model quantization resolution across participating devices. Prior work typically addresses only one of these challenges because maintaining learning utility under both privacy risks and quantization heterogeneity is a non-trivial task. In this paper, our aim is therefore to improve the learning utility of a privacy-preserving FL that allows clusters of devices with different quantization resolutions to participate in each FL round. Specifically, we introduce a novel stochastic quantizer (SQ) that is designed to simultaneously achieve differential privacy (DP) and minimum quantization error. Notably, the proposed SQ guarantees bounded distortion, unlike other DP approaches. To address quantization heterogeneity, we introduce a cluster size optimization technique combined with a linear fusion approach to enhance model aggregation accuracy. Numerical simulations validate the benefits of our approach in terms of privacy protection and learning utility compared to the conventional LaplaceSQ-FL algorithm.
Joint Optimization of User Association and Resource Allocation for Load Balancing With Multi-Level Fairness
May 13, 2025User association, the problem of assigning each user device to a suitable base station, is increasingly crucial as wireless networks become denser and serve more users with diverse service demands. The joint optimization of user association and resource allocation (UARA) is a fundamental issue for future wireless networks, as it plays a pivotal role in enhancing overall network performance, user fairness, and resource efficiency. Given the latency-sensitive nature of emerging network applications, network management favors algorithms that are simple and computationally efficient rather than complex centralized approaches. Thus, distributed pricing-based strategies have gained prominence in the UARA literature, demonstrating practicality and effectiveness across various objective functions, e.g., sum-rate, proportional fairness, max-min fairness, and alpha-fairness. While the alpha-fairness frameworks allow for flexible adjustments between efficiency and fairness via a single parameter $\alpha$, existing works predominantly assume a homogeneous fairness context, assigning an identical $\alpha$ value to all users. Real-world networks, however, frequently require differentiated user prioritization due to varying application requirements and latency. To bridge this gap, we propose a novel heterogeneous alpha-fairness (HAF) objective function, assigning distinct {\alpha} values to different users, thereby providing enhanced control over the balance between throughput, fairness, and latency across the network. We present a distributed, pricing-based optimization approach utilizing an auxiliary variable framework and provide analytical proof of its convergence to an $\epsilon$-optimal solution, where the optimality gap $\epsilon$ decreases with the number of iterations.
Federated Learning for Cyber Physical Systems: A Comprehensive Survey
May 08, 2025The integration of machine learning (ML) in cyber physical systems (CPS) is a complex task due to the challenges that arise in terms of real-time decision making, safety, reliability, device heterogeneity, and data privacy. There are also open research questions that must be addressed in order to fully realize the potential of ML in CPS. Federated learning (FL), a distributed approach to ML, has become increasingly popular in recent years. It allows models to be trained using data from decentralized sources. This approach has been gaining popularity in the CPS field, as it integrates computer, communication, and physical processes. Therefore, the purpose of this work is to provide a comprehensive analysis of the most recent developments of FL-CPS, including the numerous application areas, system topologies, and algorithms developed in recent years. The paper starts by discussing recent advances in both FL and CPS, followed by their integration. Then, the paper compares the application of FL in CPS with its applications in the internet of things (IoT) in further depth to show their connections and distinctions. Furthermore, the article scrutinizes how FL is utilized in critical CPS applications, e.g., intelligent transportation systems, cybersecurity services, smart cities, and smart healthcare solutions. The study also includes critical insights and lessons learned from various FL-CPS implementations. The paper's concluding section delves into significant concerns and suggests avenues for further research in this fast-paced and dynamic era.
Learning-Based Two-Way Communications: Algorithmic Framework and Comparative Analysis
Apr 22, 2025



Machine learning (ML)-based feedback channel coding has garnered significant research interest in the past few years. However, there has been limited research exploring ML approaches in the so-called "two-way" setting where two users jointly encode messages and feedback for each other over a shared channel. In this work, we present a general architecture for ML-based two-way feedback coding, and show how several popular one-way schemes can be converted to the two-way setting through our framework. We compare such schemes against their one-way counterparts, revealing error-rate benefits of ML-based two-way coding in certain signal-to-noise ratio (SNR) regimes. We then analyze the tradeoffs between error performance and computational overhead for three state-of-the-art neural network coding models instantiated in the two-way paradigm.
Multi-Agent Reinforcement Learning for Graph Discovery in D2D-Enabled Federated Learning
Mar 29, 2025Augmenting federated learning (FL) with device-to-device (D2D) communications can help improve convergence speed and reduce model bias through local information exchange. However, data privacy concerns, trust constraints between devices, and unreliable wireless channels each pose challenges in finding an effective yet resource efficient D2D graph structure. In this paper, we develop a decentralized reinforcement learning (RL) method for D2D graph discovery that promotes communication of impactful datapoints over reliable links for multiple learning paradigms, while following both data and device-specific trust constraints. An independent RL agent at each device trains a policy to predict the impact of incoming links in a decentralized manner without exposure of local data or significant communication overhead. For supervised settings, the D2D graph aims to improve device-specific label diversity without compromising system-level performance. For semi-supervised settings, we enable this by incorporating distributed label propagation. For unsupervised settings, we develop a variation-based diversity metric which estimates data diversity in terms of occupied latent space. Numerical experiments on five widely used datasets confirm that the data diversity improvements induced by our method increase convergence speed by up to 3 times while reducing energy consumption by up to 5 times. They also show that our method is resilient to stragglers and changes in the aggregation interval. Finally, we show that our method offers scalability benefits for larger system sizes without increases in relative overhead, and adaptability to various downstream FL architectures and to dynamic wireless environments.
Physics-Informed Generative Approaches for Wireless Channel Modeling
Mar 11, 2025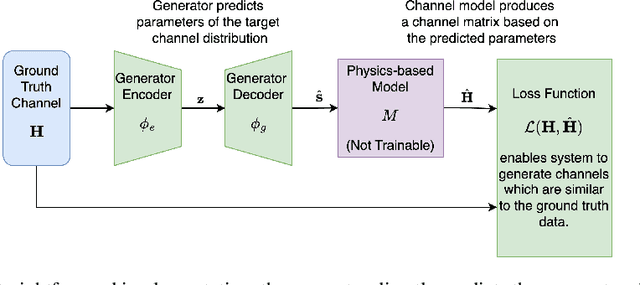
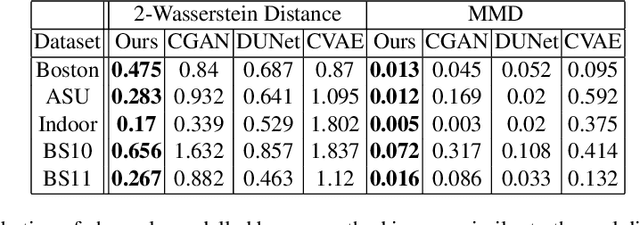

In recent years, machine learning (ML) methods have become increasingly popular in wireless communication systems for several applications. A critical bottleneck for designing ML systems for wireless communications is the availability of realistic wireless channel datasets, which are extremely resource intensive to produce. To this end, the generation of realistic wireless channels plays a key role in the subsequent design of effective ML algorithms for wireless communication systems. Generative models have been proposed to synthesize channel matrices, but outputs produced by such methods may not correspond to geometrically viable channels and do not provide any insight into the scenario of interest. In this work, we aim to address both these issues by integrating a parametric, physics-based geometric channel (PBGC) modeling framework with generative methods. To address limitations with gradient flow through the PBGC model, a linearized reformulation is presented, which ensures smooth gradient flow during generative model training, while also capturing insights about the underlying physical environment. We evaluate our model against prior baselines by comparing the generated samples in terms of the 2-Wasserstein distance and through the utility of generated data when used for downstream compression tasks.
Machine Learning for Future Wireless Communications: Channel Prediction Perspectives
Feb 25, 2025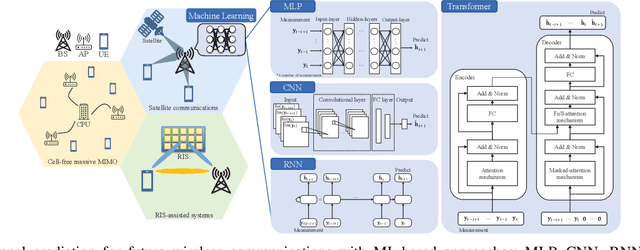
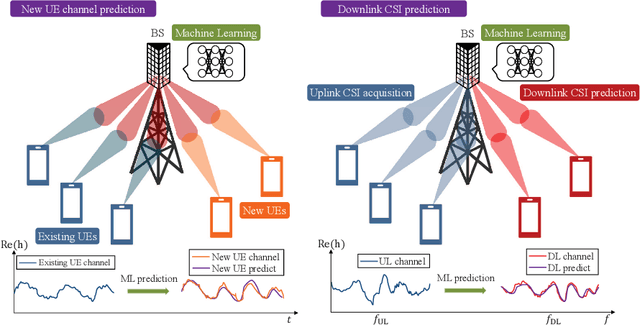
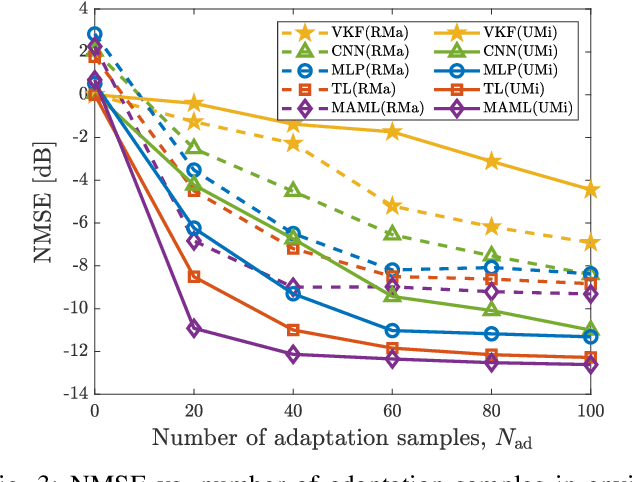
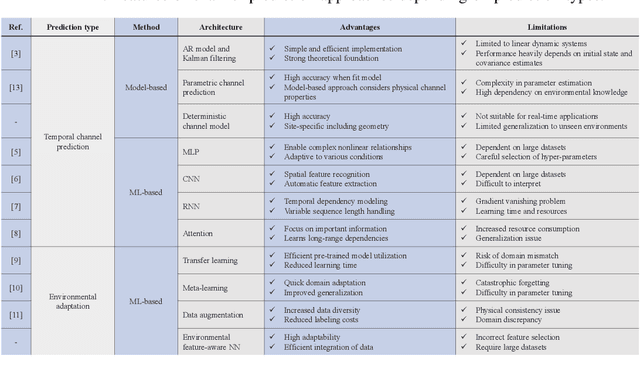
Precise channel state knowledge is crucial in future wireless communication systems, which drives the need for accurate channel prediction without additional pilot overhead. While machine-learning (ML) methods for channel prediction show potential, existing approaches have limitations in their capability to adapt to environmental changes due to their extensive training requirements. In this paper, we introduce the channel prediction approaches in terms of the temporal channel prediction and the environmental adaptation. Then, we elaborate on the use of the advanced ML-based channel prediction to resolve the issues in traditional ML methods. The numerical results show that the advanced ML-based channel prediction has comparable accuracy with much less training overhead compared to conventional prediction methods. Also, we examine the training process, dataset characteristics, and the impact of source tasks and pre-trained models on channel prediction approaches. Finally, we discuss open challenges and possible future research directions of ML-based channel prediction.