 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Continual Learning of Local Language Models and Cloud Offloading Decisions with Budget Constraints
Jan 29, 2026Locally deployed Small Language Models (SLMs) must continually support diverse tasks under strict memory and computation constraints, making selective reliance on cloud Large Language Models (LLMs) unavoidable. Regulating cloud assistance during continual learning is challenging, as naive reward-based reinforcement learning often yields unstable offloading behavior and exacerbates catastrophic forgetting as task distributions shift. We propose DA-GRPO, a dual-advantage extension of Group Relative Policy Optimization that incorporates cloud-usage constraints directly into advantage computation, avoiding fixed reward shaping and external routing models. This design enables the local model to jointly learn task competence and collaboration behavior, allowing cloud requests to emerge naturally during post-training while respecting a prescribed assistance budget. Experiments on mathematical reasoning and code generation benchmarks show that DA-GRPO improves post-switch accuracy, substantially reduces forgetting, and maintains stable cloud usage compared to prior collaborative and routing-based approaches.
TAP: Two-Stage Adaptive Personalization of Multi-task and Multi-Modal Foundation Models in Federated Learning
Sep 30, 2025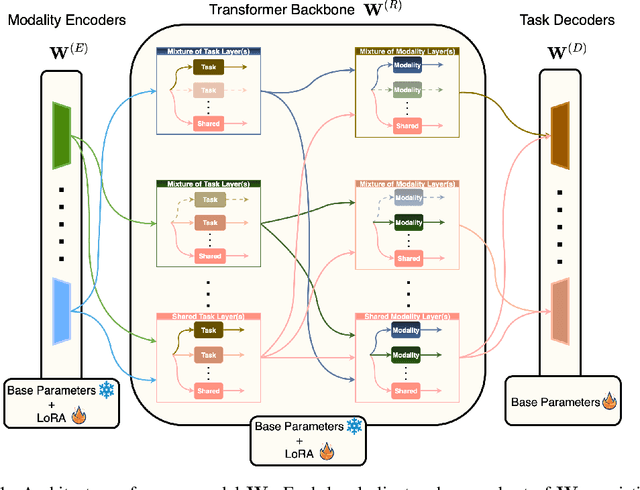
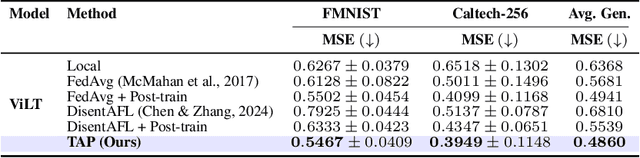
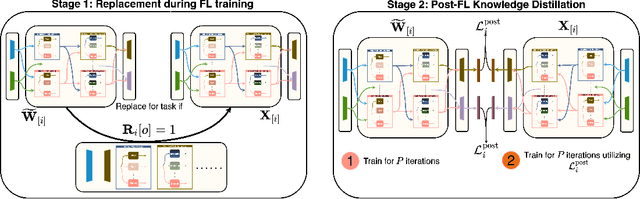
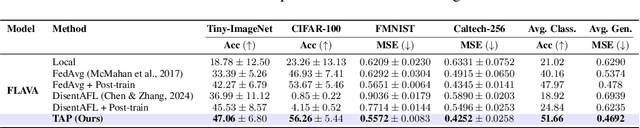
Federated Learning (FL), despite demonstrating impressive capabilities in the training of multiple models in a decentralized manner, has been shown to produce a final model not necessarily well-suited to the needs of each client. While extensive work has been conducted on how to create tailored personalized models, called Personalized Federated Learning (PFL), less attention has been given to personalization via fine-tuning of foundation models with multi-task and multi-modal properties. Moreover, there exists a lack of understanding in the literature on how to fine-tune and personalize such models in a setting that is heterogeneous across clients not only in data, but also in tasks and modalities. To address this gap in the literature, we propose TAP (Two-Stage Adaptive Personalization), which (i) leverages mismatched model architectures between the clients and server to selectively conduct replacement operations when it benefits a client's local tasks and (ii) engages in post-FL knowledge distillation for capturing beneficial general knowledge without compromising personalization. We also introduce the first convergence analysis of the server model under its modality-task pair architecture, and demonstrate that as the number of modality-task pairs increases, its ability to cater to all tasks suffers. Through extensive experiments, we demonstrate the effectiveness of our proposed algorithm across a variety of datasets and tasks in comparison to a multitude of baselines. Implementation code is publicly available at https://github.com/lee3296/TAP.
Federated Sketching LoRA: On-Device Collaborative Fine-Tuning of Large Language Models
Jan 31, 2025



Fine-tuning large language models (LLMs) on devices is attracting increasing interest. Recent works have fused low-rank adaptation (LoRA) techniques with federated fine-tuning to mitigate challenges associated with device model sizes and data scarcity. Still, the heterogeneity of computational resources remains a critical bottleneck: while higher-rank modules generally enhance performance, varying device capabilities constrain LoRA's feasible rank range. Existing approaches attempting to resolve this issue either lack analytical justification or impose additional computational overhead, leaving a wide gap for an efficient and theoretically-grounded solution. To address these challenges, we propose federated sketching LoRA (FSLoRA), which leverages a sketching mechanism to enable devices to selectively update submatrices of global LoRA modules maintained by the server. By adjusting the sketching ratios, which determine the ranks of the submatrices on the devices, FSLoRA flexibly adapts to device-specific communication and computational constraints. We provide a rigorous convergence analysis of FSLoRA that characterizes how the sketching ratios affect the convergence rate. Through comprehensive experiments on multiple datasets and LLM models, we demonstrate FSLoRA's superior performance compared to various baselines.
Cooperative Decentralized Backdoor Attacks on Vertical Federated Learning
Jan 16, 2025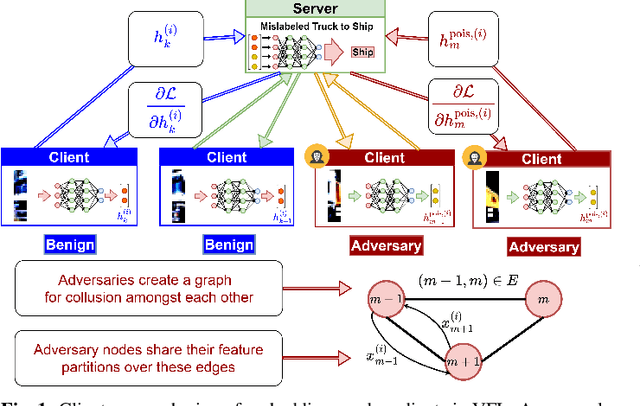
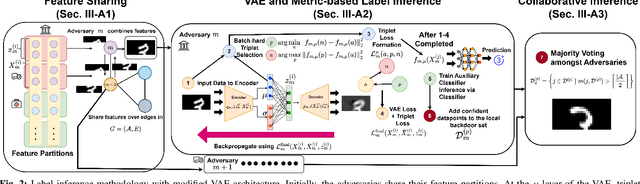
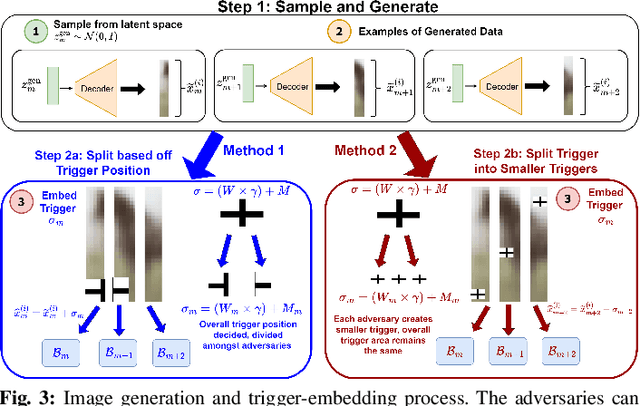
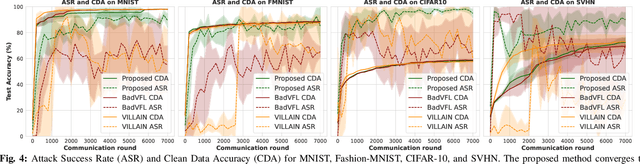
Federated learning (FL) is vulnerable to backdoor attacks, where adversaries alter model behavior on target classification labels by embedding triggers into data samples. While these attacks have received considerable attention in horizontal FL, they are less understood for vertical FL (VFL), where devices hold different features of the samples, and only the server holds the labels. In this work, we propose a novel backdoor attack on VFL which (i) does not rely on gradient information from the server and (ii) considers potential collusion among multiple adversaries for sample selection and trigger embedding. Our label inference model augments variational autoencoders with metric learning, which adversaries can train locally. A consensus process over the adversary graph topology determines which datapoints to poison. We further propose methods for trigger splitting across the adversaries, with an intensity-based implantation scheme skewing the server towards the trigger. Our convergence analysis reveals the impact of backdoor perturbations on VFL indicated by a stationarity gap for the trained model, which we verify empirically as well. We conduct experiments comparing our attack with recent backdoor VFL approaches, finding that ours obtains significantly higher success rates for the same main task performance despite not using server information. Additionally, our results verify the impact of collusion on attack performance.
Hierarchical Federated Learning with Multi-Timescale Gradient Correction
Sep 27, 2024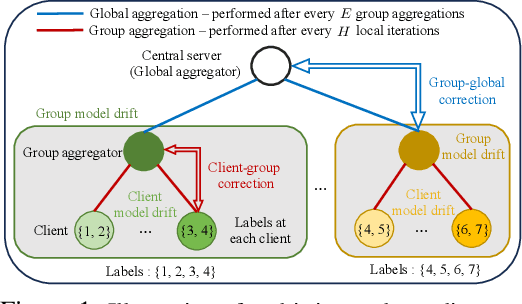
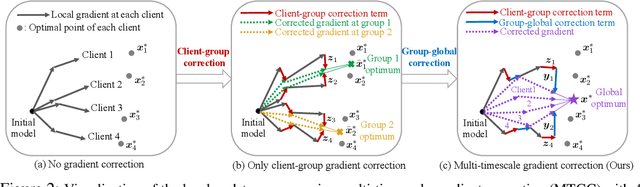
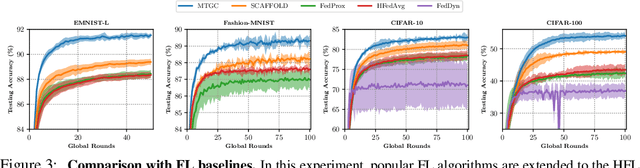
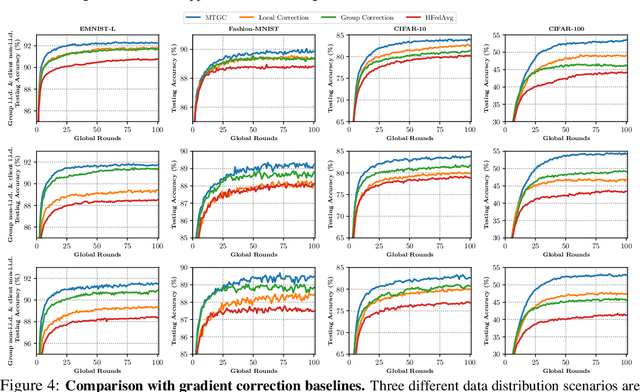
While traditional federated learning (FL) typically focuses on a star topology where clients are directly connected to a central server, real-world distributed systems often exhibit hierarchical architectures. Hierarchical FL (HFL) has emerged as a promising solution to bridge this gap, leveraging aggregation points at multiple levels of the system. However, existing algorithms for HFL encounter challenges in dealing with multi-timescale model drift, i.e., model drift occurring across hierarchical levels of data heterogeneity. In this paper, we propose a multi-timescale gradient correction (MTGC) methodology to resolve this issue. Our key idea is to introduce distinct control variables to (i) correct the client gradient towards the group gradient, i.e., to reduce client model drift caused by local updates based on individual datasets, and (ii) correct the group gradient towards the global gradient, i.e., to reduce group model drift caused by FL over clients within the group. We analytically characterize the convergence behavior of MTGC under general non-convex settings, overcoming challenges associated with couplings between correction terms. We show that our convergence bound is immune to the extent of data heterogeneity, confirming the stability of the proposed algorithm against multi-level non-i.i.d. data. Through extensive experiments on various datasets and models, we validate the effectiveness of MTGC in diverse HFL settings. The code for this project is available at \href{https://github.com/wenzhifang/MTGC}{https://github.com/wenzhifang/MTGC}.
Submodel Partitioning in Hierarchical Federated Learning: Algorithm Design and Convergence Analysis
Oct 27, 2023Hierarchical federated learning (HFL) has demonstrated promising scalability advantages over the traditional "star-topology" architecture-based federated learning (FL). However, HFL still imposes significant computation, communication, and storage burdens on the edge, especially when training a large-scale model over resource-constrained Internet of Things (IoT) devices. In this paper, we propose hierarchical independent submodel training (HIST), a new FL methodology that aims to address these issues in hierarchical settings. The key idea behind HIST is a hierarchical version of model partitioning, where we partition the global model into disjoint submodels in each round, and distribute them across different cells, so that each cell is responsible for training only one partition of the full model. This enables each client to save computation/storage costs while alleviating the communication loads throughout the hierarchy. We characterize the convergence behavior of HIST for non-convex loss functions under mild assumptions, showing the impact of several attributes (e.g., number of cells, local and global aggregation frequency) on the performance-efficiency tradeoff. Finally, through numerical experiments, we verify that HIST is able to save communication costs by a wide margin while achieving the same target testing accuracy.
Communication-Efficient Stochastic Zeroth-Order Optimization for Federated Learning
Jan 24, 2022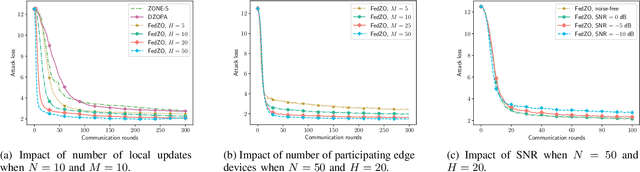
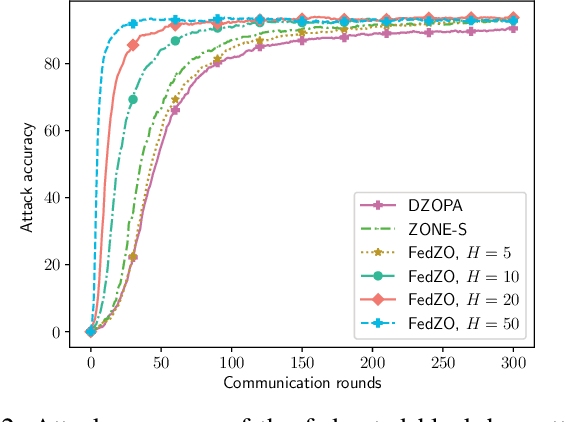
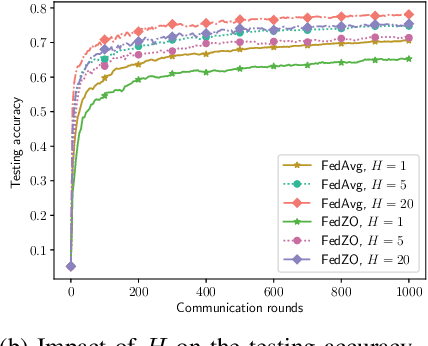
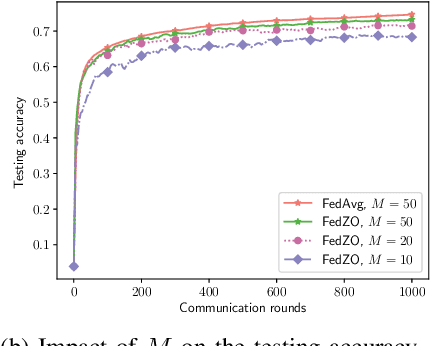
Federated learning (FL), as an emerging edge artificial intelligence paradigm, enables many edge devices to collaboratively train a global model without sharing their private data. To enhance the training efficiency of FL, various algorithms have been proposed, ranging from first-order to second-order methods. However, these algorithms cannot be applied in scenarios where the gradient information is not available, e.g., federated black-box attack and federated hyperparameter tuning. To address this issue, in this paper we propose a derivative-free federated zeroth-order optimization (FedZO) algorithm featured by performing multiple local updates based on stochastic gradient estimators in each communication round and enabling partial device participation. Under the non-convex setting, we derive the convergence performance of the FedZO algorithm and characterize the impact of the numbers of local iterates and participating edge devices on the convergence. To enable communication-efficient FedZO over wireless networks, we further propose an over-the-air computation (AirComp) assisted FedZO algorithm. With an appropriate transceiver design, we show that the convergence of AirComp-assisted FedZO can still be preserved under certain signal-to-noise ratio conditions. Simulation results demonstrate the effectiveness of the FedZO algorithm and validate the theoretical observations.
Over-the-Air Computation via Reconfigurable Intelligent Surface
May 11, 2021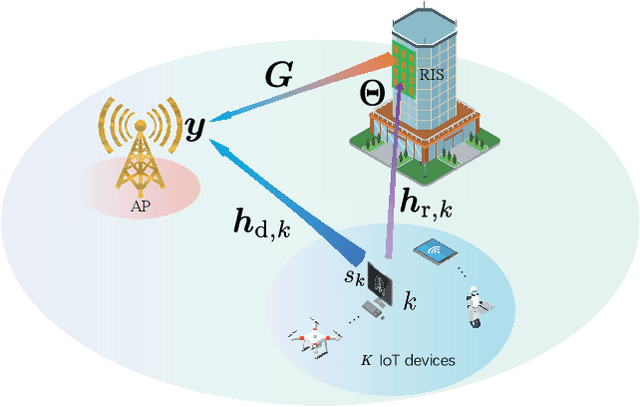
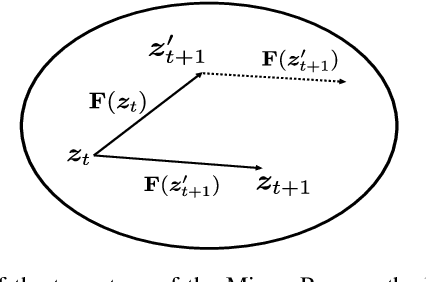
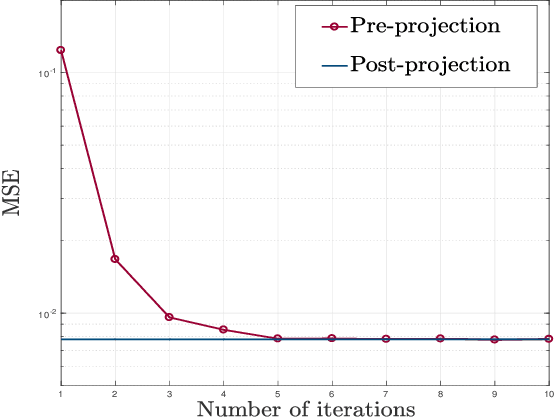
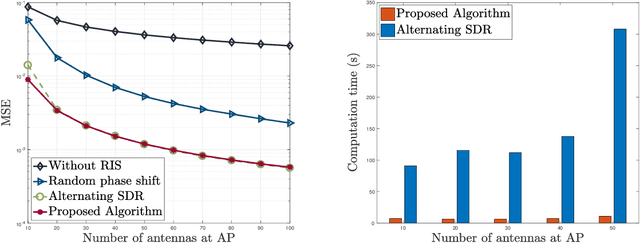
Over-the-air computation (AirComp) is a disruptive technique for fast wireless data aggregation in Internet of Things (IoT) networks via exploiting the waveform superposition property of multiple-access channels. However, the performance of AirComp is bottlenecked by the worst channel condition among all links between the IoT devices and the access point. In this paper, a reconfigurable intelligent surface (RIS) assisted AirComp system is proposed to boost the received signal power and thus mitigate the performance bottleneck by reconfiguring the propagation channels. With an objective to minimize the AirComp distortion, we propose a joint design of AirComp transceivers and RIS phase-shifts, which however turns out to be a highly intractable non-convex programming problem. To this end, we develop a novel alternating minimization framework in conjunction with the successive convex approximation technique, which is proved to converge monotonically. To reduce the computational complexity, we transform the subproblem in each alternation as a smooth convex-concave saddle point problem, which is then tackled by proposing a Mirror-Prox method that only involves a sequence of closed-form updates. Simulations show that the computation time of the proposed algorithm can be two orders of magnitude smaller than that of the state-of-the-art algorithms, while achieving a similar distortion performance.
Optimal Receive Beamforming for Over-the-Air Computation
May 11, 2021
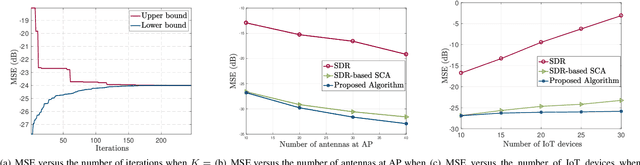
In this paper, we consider fast wireless data aggregation via over-the-air computation (AirComp) in Internet of Things (IoT) networks, where an access point (AP) with multiple antennas aim to recover the arithmetic mean of sensory data from multiple IoT devices. To minimize the estimation distortion, we formulate a mean-squared-error (MSE) minimization problem that involves the joint optimization of the transmit scalars at the IoT devices as well as the denoising factor and the receive beamforming vector at the AP. To this end, we derive the transmit scalars and the denoising factor in closed-form, resulting in a non-convex quadratic constrained quadratic programming (QCQP) problem concerning the receive beamforming vector.Different from the existing studies that only obtain sub-optimal beamformers, we propose a branch and bound (BnB) algorithm to design the globally optimal receive beamformer.Extensive simulations demonstrate the superior performance of the proposed algorithm in terms of MSE. Moreover, the proposed BnB algorithm can serve as a benchmark to evaluate the performance of the existing sub-optimal algorithms.