 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Sparse Representations for Concept-Separated Diffusion Unlearning
May 12, 2026Unlearning specific concepts in text-to-image diffusion models has become increasingly important for preventing undesirable content generation. Among prior approaches, sparse autoencoder (SAE)-based methods have attracted attention due to their ability to suppress target concepts through lightweight manipulation of latent features, without modifying model parameters. However, SAEs trained with sparse reconstruction objectives do not explicitly enforce concept-wise separation, resulting in shared latent features across concepts. To address this, we propose SAEParate, which organizes latent representations into concept-specific clusters via a concept-aware contrastive objective, enabling more precise concept suppression while reducing unintended interference during unlearning. In addition, we enhance the encoder with a GeLU-based nonlinear transformation to increase its expressive capacity under this separation objective, enabling a more discriminative and disentangled latent space. Experiments on UnlearnCanvas demonstrate state-of-the-art performance, with particularly strong gains in joint style-object unlearning, a challenging setting where existing methods suffer from severe interference between target and non-target concepts.
Sporadic Gradient Tracking over Directed Graphs: A Theoretical Perspective on Decentralized Federated Learning
Jan 31, 2026Decentralized Federated Learning (DFL) enables clients with local data to collaborate in a peer-to-peer manner to train a generalized model. In this paper, we unify two branches of work that have separately solved important challenges in DFL: (i) gradient tracking techniques for mitigating data heterogeneity and (ii) accounting for diverse availability of resources across clients. We propose $\textit{Sporadic Gradient Tracking}$ ($\texttt{Spod-GT}$), the first DFL algorithm that incorporates these factors over general directed graphs by allowing (i) client-specific gradient computation frequencies and (ii) heterogeneous and asymmetric communication frequencies. We conduct a rigorous convergence analysis of our methodology with relaxed assumptions on gradient estimation variance and gradient diversity of clients, providing consensus and optimality guarantees for GT over directed graphs despite intermittent client participation. Through numerical experiments on image classification datasets, we demonstrate the efficacy of $\texttt{Spod-GT}$ compared to well-known GT baselines.
TAP: Two-Stage Adaptive Personalization of Multi-task and Multi-Modal Foundation Models in Federated Learning
Sep 30, 2025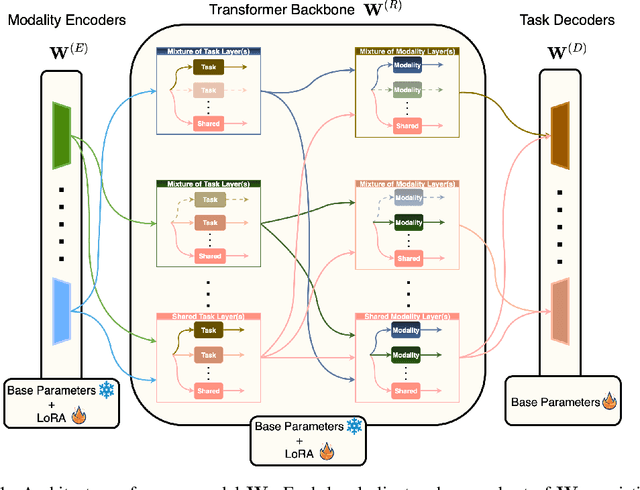
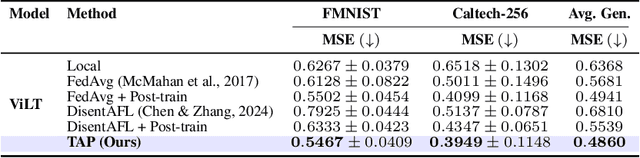
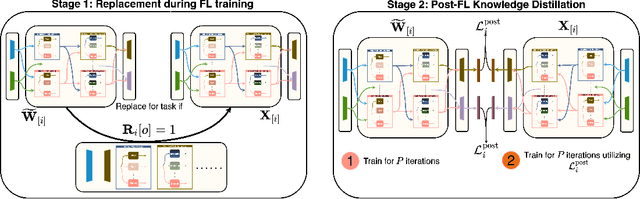
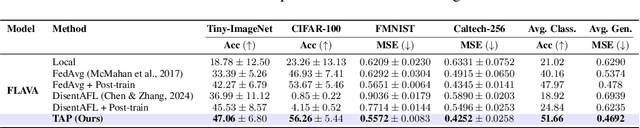
Federated Learning (FL), despite demonstrating impressive capabilities in the training of multiple models in a decentralized manner, has been shown to produce a final model not necessarily well-suited to the needs of each client. While extensive work has been conducted on how to create tailored personalized models, called Personalized Federated Learning (PFL), less attention has been given to personalization via fine-tuning of foundation models with multi-task and multi-modal properties. Moreover, there exists a lack of understanding in the literature on how to fine-tune and personalize such models in a setting that is heterogeneous across clients not only in data, but also in tasks and modalities. To address this gap in the literature, we propose TAP (Two-Stage Adaptive Personalization), which (i) leverages mismatched model architectures between the clients and server to selectively conduct replacement operations when it benefits a client's local tasks and (ii) engages in post-FL knowledge distillation for capturing beneficial general knowledge without compromising personalization. We also introduce the first convergence analysis of the server model under its modality-task pair architecture, and demonstrate that as the number of modality-task pairs increases, its ability to cater to all tasks suffers. Through extensive experiments, we demonstrate the effectiveness of our proposed algorithm across a variety of datasets and tasks in comparison to a multitude of baselines. Implementation code is publicly available at https://github.com/lee3296/TAP.
Decentralized Federated Domain Generalization with Style Sharing: A Formal Modeling and Convergence Analysis
Apr 08, 2025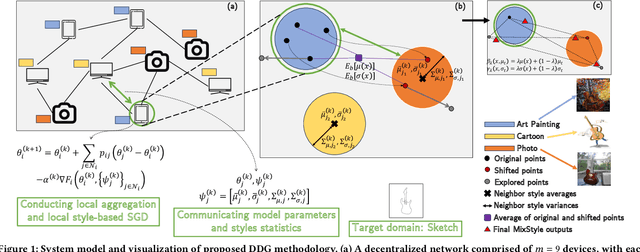
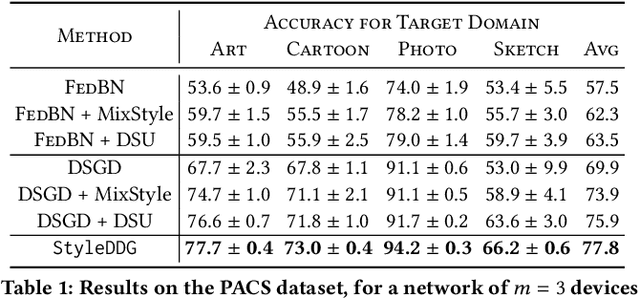
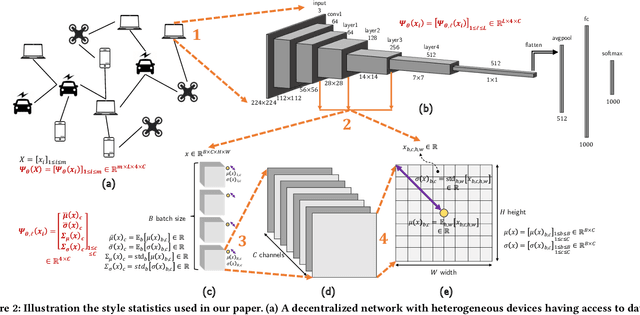
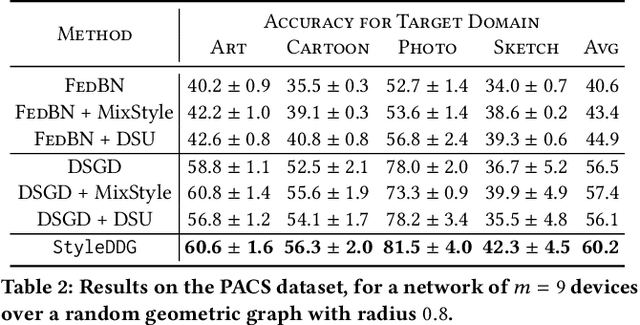
Much of the federated learning (FL) literature focuses on settings where local dataset statistics remain the same between training and testing time. Recent advances in domain generalization (DG) aim to use data from source (training) domains to train a model that generalizes well to data from unseen target (testing) domains. In this paper, we are motivated by two major gaps in existing work on FL and DG: (1) the lack of formal mathematical analysis of DG objectives and training processes; and (2) DG research in FL being limited to the conventional star-topology architecture. Addressing the second gap, we develop $\textit{Decentralized Federated Domain Generalization with Style Sharing}$ ($\texttt{StyleDDG}$), a fully decentralized DG algorithm designed to allow devices in a peer-to-peer network to achieve DG based on sharing style information inferred from their datasets. Additionally, we fill the first gap by providing the first systematic approach to mathematically analyzing style-based DG training optimization. We cast existing centralized DG algorithms within our framework, and employ their formalisms to model $\texttt{StyleDDG}$. Based on this, we obtain analytical conditions under which a sub-linear convergence rate of $\texttt{StyleDDG}$ can be obtained. Through experiments on two popular DG datasets, we demonstrate that $\texttt{StyleDDG}$ can obtain significant improvements in accuracy across target domains with minimal added communication overhead compared to decentralized gradient methods that do not employ style sharing.
PRISM: Privacy-Preserving Improved Stochastic Masking for Federated Generative Models
Mar 11, 2025Despite recent advancements in federated learning (FL), the integration of generative models into FL has been limited due to challenges such as high communication costs and unstable training in heterogeneous data environments. To address these issues, we propose PRISM, a FL framework tailored for generative models that ensures (i) stable performance in heterogeneous data distributions and (ii) resource efficiency in terms of communication cost and final model size. The key of our method is to search for an optimal stochastic binary mask for a random network rather than updating the model weights, identifying a sparse subnetwork with high generative performance; i.e., a ``strong lottery ticket''. By communicating binary masks in a stochastic manner, PRISM minimizes communication overhead. This approach, combined with the utilization of maximum mean discrepancy (MMD) loss and a mask-aware dynamic moving average aggregation method (MADA) on the server side, facilitates stable and strong generative capabilities by mitigating local divergence in FL scenarios. Moreover, thanks to its sparsifying characteristic, PRISM yields a lightweight model without extra pruning or quantization, making it ideal for environments such as edge devices. Experiments on MNIST, FMNIST, CelebA, and CIFAR10 demonstrate that PRISM outperforms existing methods, while maintaining privacy with minimal communication costs. PRISM is the first to successfully generate images under challenging non-IID and privacy-preserving FL environments on complex datasets, where previous methods have struggled.
Federated Sketching LoRA: On-Device Collaborative Fine-Tuning of Large Language Models
Jan 31, 2025



Fine-tuning large language models (LLMs) on devices is attracting increasing interest. Recent works have fused low-rank adaptation (LoRA) techniques with federated fine-tuning to mitigate challenges associated with device model sizes and data scarcity. Still, the heterogeneity of computational resources remains a critical bottleneck: while higher-rank modules generally enhance performance, varying device capabilities constrain LoRA's feasible rank range. Existing approaches attempting to resolve this issue either lack analytical justification or impose additional computational overhead, leaving a wide gap for an efficient and theoretically-grounded solution. To address these challenges, we propose federated sketching LoRA (FSLoRA), which leverages a sketching mechanism to enable devices to selectively update submatrices of global LoRA modules maintained by the server. By adjusting the sketching ratios, which determine the ranks of the submatrices on the devices, FSLoRA flexibly adapts to device-specific communication and computational constraints. We provide a rigorous convergence analysis of FSLoRA that characterizes how the sketching ratios affect the convergence rate. Through comprehensive experiments on multiple datasets and LLM models, we demonstrate FSLoRA's superior performance compared to various baselines.
Using Diffusion Models as Generative Replay in Continual Federated Learning -- What will Happen?
Nov 10, 2024



Federated learning (FL) has become a cornerstone in decentralized learning, where, in many scenarios, the incoming data distribution will change dynamically over time, introducing continuous learning (CL) problems. This continual federated learning (CFL) task presents unique challenges, particularly regarding catastrophic forgetting and non-IID input data. Existing solutions include using a replay buffer to store historical data or leveraging generative adversarial networks. Nevertheless, motivated by recent advancements in the diffusion model for generative tasks, this paper introduces DCFL, a novel framework tailored to address the challenges of CFL in dynamic distributed learning environments. Our approach harnesses the power of the conditional diffusion model to generate synthetic historical data at each local device during communication, effectively mitigating latent shifts in dynamic data distribution inputs. We provide the convergence bound for the proposed CFL framework and demonstrate its promising performance across multiple datasets, showcasing its effectiveness in tackling the complexities of CFL tasks.
Federated Learning with Dynamic Client Arrival and Departure: Convergence and Rapid Adaptation via Initial Model Construction
Oct 08, 2024While most existing federated learning (FL) approaches assume a fixed set of clients in the system, in practice, clients can dynamically leave or join the system depending on their needs or interest in the specific task. This dynamic FL setting introduces several key challenges: (1) the objective function dynamically changes depending on the current set of clients, unlike traditional FL approaches that maintain a static optimization goal; (2) the current global model may not serve as the best initial point for the next FL rounds and could potentially lead to slow adaptation, given the possibility of clients leaving or joining the system. In this paper, we consider a dynamic optimization objective in FL that seeks the optimal model tailored to the currently active set of clients. Building on our probabilistic framework that provides direct insights into how the arrival and departure of different types of clients influence the shifts in optimal points, we establish an upper bound on the optimality gap, accounting for factors such as stochastic gradient noise, local training iterations, non-IIDness of data distribution, and deviations between optimal points caused by dynamic client pattern. We also propose an adaptive initial model construction strategy that employs weighted averaging guided by gradient similarity, prioritizing models trained on clients whose data characteristics align closely with the current one, thereby enhancing adaptability to the current clients. The proposed approach is validated on various datasets and FL algorithms, demonstrating robust performance across diverse client arrival and departure patterns, underscoring its effectiveness in dynamic FL environments.
SePPO: Semi-Policy Preference Optimization for Diffusion Alignment
Oct 07, 2024



Reinforcement learning from human feedback (RLHF) methods are emerging as a way to fine-tune diffusion models (DMs) for visual generation. However, commonly used on-policy strategies are limited by the generalization capability of the reward model, while off-policy approaches require large amounts of difficult-to-obtain paired human-annotated data, particularly in visual generation tasks. To address the limitations of both on- and off-policy RLHF, we propose a preference optimization method that aligns DMs with preferences without relying on reward models or paired human-annotated data. Specifically, we introduce a Semi-Policy Preference Optimization (SePPO) method. SePPO leverages previous checkpoints as reference models while using them to generate on-policy reference samples, which replace "losing images" in preference pairs. This approach allows us to optimize using only off-policy "winning images." Furthermore, we design a strategy for reference model selection that expands the exploration in the policy space. Notably, we do not simply treat reference samples as negative examples for learning. Instead, we design an anchor-based criterion to assess whether the reference samples are likely to be winning or losing images, allowing the model to selectively learn from the generated reference samples. This approach mitigates performance degradation caused by the uncertainty in reference sample quality. We validate SePPO across both text-to-image and text-to-video benchmarks. SePPO surpasses all previous approaches on the text-to-image benchmarks and also demonstrates outstanding performance on the text-to-video benchmarks. Code will be released in https://github.com/DwanZhang-AI/SePPO.
Hierarchical Federated Learning with Multi-Timescale Gradient Correction
Sep 27, 2024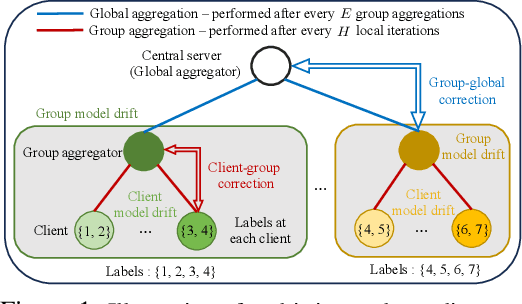
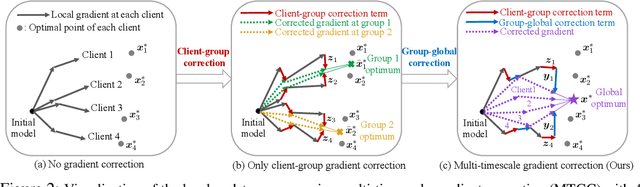
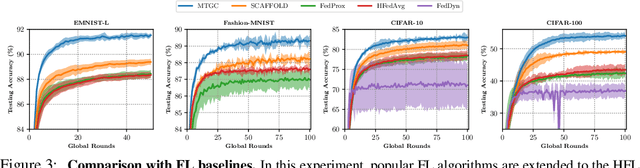
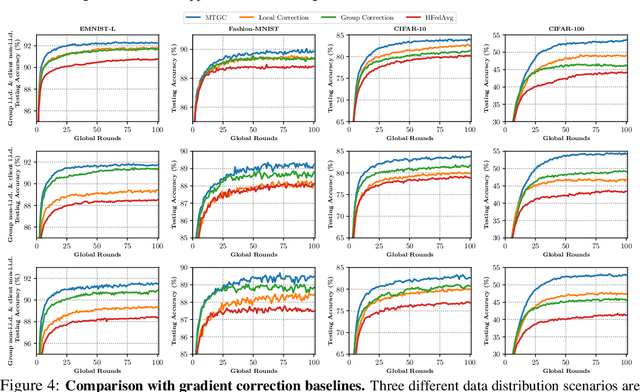
While traditional federated learning (FL) typically focuses on a star topology where clients are directly connected to a central server, real-world distributed systems often exhibit hierarchical architectures. Hierarchical FL (HFL) has emerged as a promising solution to bridge this gap, leveraging aggregation points at multiple levels of the system. However, existing algorithms for HFL encounter challenges in dealing with multi-timescale model drift, i.e., model drift occurring across hierarchical levels of data heterogeneity. In this paper, we propose a multi-timescale gradient correction (MTGC) methodology to resolve this issue. Our key idea is to introduce distinct control variables to (i) correct the client gradient towards the group gradient, i.e., to reduce client model drift caused by local updates based on individual datasets, and (ii) correct the group gradient towards the global gradient, i.e., to reduce group model drift caused by FL over clients within the group. We analytically characterize the convergence behavior of MTGC under general non-convex settings, overcoming challenges associated with couplings between correction terms. We show that our convergence bound is immune to the extent of data heterogeneity, confirming the stability of the proposed algorithm against multi-level non-i.i.d. data. Through extensive experiments on various datasets and models, we validate the effectiveness of MTGC in diverse HFL settings. The code for this project is available at \href{https://github.com/wenzhifang/MTGC}{https://github.com/wenzhifang/MTGC}.