 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeVStereo: A NeRF-Driven NVS-Stereo Architecture for High-Fidelity 3D Tasks
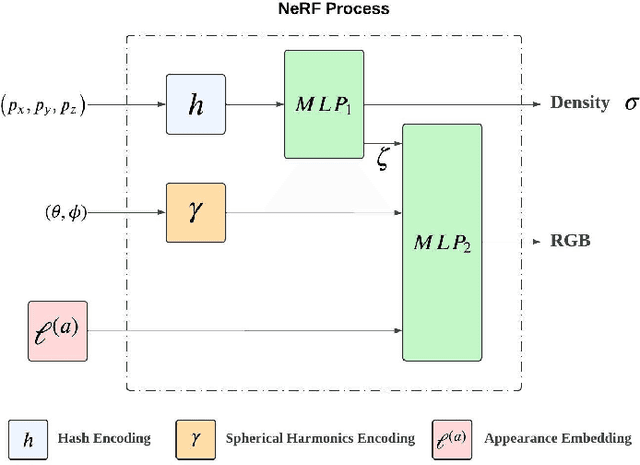
Feb 05, 2026In modern dense 3D reconstruction, feed-forward systems (e.g., VGGT, pi3) focus on end-to-end matching and geometry prediction but do not explicitly output the novel view synthesis (NVS). Neural rendering-based approaches offer high-fidelity NVS and detailed geometry from posed images, yet they typically assume fixed camera poses and can be sensitive to pose errors. As a result, it remains non-trivial to obtain a single framework that can offer accurate poses, reliable depth, high-quality rendering, and accurate 3D surfaces from casually captured views. We present NeVStereo, a NeRF-driven NVS-stereo architecture that aims to jointly deliver camera poses, multi-view depth, novel view synthesis, and surface reconstruction from multi-view RGB-only inputs. NeVStereo combines NeRF-based NVS for stereo-friendly renderings, confidence-guided multi-view depth estimation, NeRF-coupled bundle adjustment for pose refinement, and an iterative refinement stage that updates both depth and the radiance field to improve geometric consistency. This design mitigated the common NeRF-based issues such as surface stacking, artifacts, and pose-depth coupling. Across indoor, outdoor, tabletop, and aerial benchmarks, our experiments indicate that NeVStereo achieves consistently strong zero-shot performance, with up to 36% lower depth error, 10.4% improved pose accuracy, 4.5% higher NVS fidelity, and state-of-the-art mesh quality (F1 91.93%, Chamfer 4.35 mm) compared to existing prestigious methods.
Can Large Language Models Function as Qualified Pediatricians? A Systematic Evaluation in Real-World Clinical Contexts
Nov 17, 2025With the rapid rise of large language models (LLMs) in medicine, a key question is whether they can function as competent pediatricians in real-world clinical settings. We developed PEDIASBench, a systematic evaluation framework centered on a knowledge-system framework and tailored to realistic clinical environments. PEDIASBench assesses LLMs across three dimensions: application of basic knowledge, dynamic diagnosis and treatment capability, and pediatric medical safety and medical ethics. We evaluated 12 representative models released over the past two years, including GPT-4o, Qwen3-235B-A22B, and DeepSeek-V3, covering 19 pediatric subspecialties and 211 prototypical diseases. State-of-the-art models performed well on foundational knowledge, with Qwen3-235B-A22B achieving over 90% accuracy on licensing-level questions, but performance declined ~15% as task complexity increased, revealing limitations in complex reasoning. Multiple-choice assessments highlighted weaknesses in integrative reasoning and knowledge recall. In dynamic diagnosis and treatment scenarios, DeepSeek-R1 scored highest in case reasoning (mean 0.58), yet most models struggled to adapt to real-time patient changes. On pediatric medical ethics and safety tasks, Qwen2.5-72B performed best (accuracy 92.05%), though humanistic sensitivity remained limited. These findings indicate that pediatric LLMs are constrained by limited dynamic decision-making and underdeveloped humanistic care. Future development should focus on multimodal integration and a clinical feedback-model iteration loop to enhance safety, interpretability, and human-AI collaboration. While current LLMs cannot independently perform pediatric care, they hold promise for decision support, medical education, and patient communication, laying the groundwork for a safe, trustworthy, and collaborative intelligent pediatric healthcare system.
TCM-5CEval: Extended Deep Evaluation Benchmark for LLM's Comprehensive Clinical Research Competence in Traditional Chinese Medicine
Nov 17, 2025Large language models (LLMs) have demonstrated exceptional capabilities in general domains, yet their application in highly specialized and culturally-rich fields like Traditional Chinese Medicine (TCM) requires rigorous and nuanced evaluation. Building upon prior foundational work such as TCM-3CEval, which highlighted systemic knowledge gaps and the importance of cultural-contextual alignment, we introduce TCM-5CEval, a more granular and comprehensive benchmark. TCM-5CEval is designed to assess LLMs across five critical dimensions: (1) Core Knowledge (TCM-Exam), (2) Classical Literacy (TCM-LitQA), (3) Clinical Decision-making (TCM-MRCD), (4) Chinese Materia Medica (TCM-CMM), and (5) Clinical Non-pharmacological Therapy (TCM-ClinNPT). We conducted a thorough evaluation of fifteen prominent LLMs, revealing significant performance disparities and identifying top-performing models like deepseek\_r1 and gemini\_2\_5\_pro. Our findings show that while models exhibit proficiency in recalling foundational knowledge, they struggle with the interpretative complexities of classical texts. Critically, permutation-based consistency testing reveals widespread fragilities in model inference. All evaluated models, including the highest-scoring ones, displayed a substantial performance degradation when faced with varied question option ordering, indicating a pervasive sensitivity to positional bias and a lack of robust understanding. TCM-5CEval not only provides a more detailed diagnostic tool for LLM capabilities in TCM but aldso exposes fundamental weaknesses in their reasoning stability. To promote further research and standardized comparison, TCM-5CEval has been uploaded to the Medbench platform, joining its predecessor in the "In-depth Challenge for Comprehensive TCM Abilities" special track.
MedQ-Bench: Evaluating and Exploring Medical Image Quality Assessment Abilities in MLLMs
Oct 02, 2025
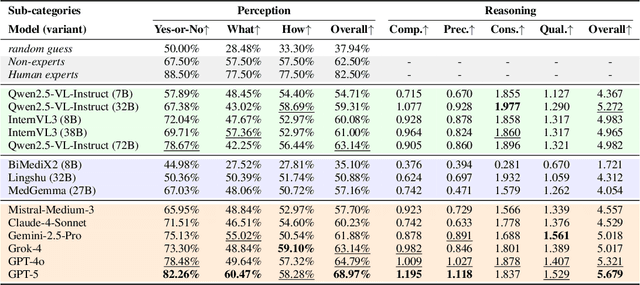
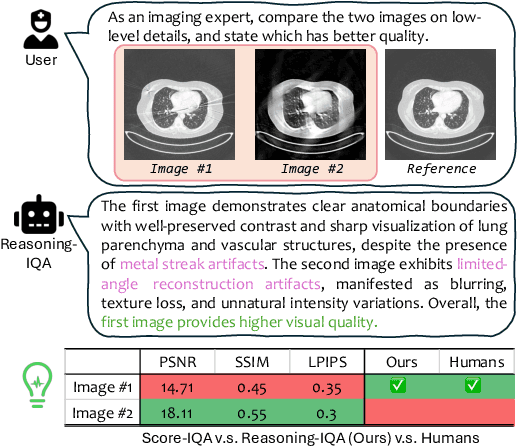

Medical Image Quality Assessment (IQA) serves as the first-mile safety gate for clinical AI, yet existing approaches remain constrained by scalar, score-based metrics and fail to reflect the descriptive, human-like reasoning process central to expert evaluation. To address this gap, we introduce MedQ-Bench, a comprehensive benchmark that establishes a perception-reasoning paradigm for language-based evaluation of medical image quality with Multi-modal Large Language Models (MLLMs). MedQ-Bench defines two complementary tasks: (1) MedQ-Perception, which probes low-level perceptual capability via human-curated questions on fundamental visual attributes; and (2) MedQ-Reasoning, encompassing both no-reference and comparison reasoning tasks, aligning model evaluation with human-like reasoning on image quality. The benchmark spans five imaging modalities and over forty quality attributes, totaling 2,600 perceptual queries and 708 reasoning assessments, covering diverse image sources including authentic clinical acquisitions, images with simulated degradations via physics-based reconstructions, and AI-generated images. To evaluate reasoning ability, we propose a multi-dimensional judging protocol that assesses model outputs along four complementary axes. We further conduct rigorous human-AI alignment validation by comparing LLM-based judgement with radiologists. Our evaluation of 14 state-of-the-art MLLMs demonstrates that models exhibit preliminary but unstable perceptual and reasoning skills, with insufficient accuracy for reliable clinical use. These findings highlight the need for targeted optimization of MLLMs in medical IQA. We hope that MedQ-Bench will catalyze further exploration and unlock the untapped potential of MLLMs for medical image quality evaluation.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Building a Human-Verified Clinical Reasoning Dataset via a Human LLM Hybrid Pipeline for Trustworthy Medical AI
May 11, 2025Despite strong performance in medical question-answering, the clinical adoption of Large Language Models (LLMs) is critically hampered by their opaque 'black-box' reasoning, limiting clinician trust. This challenge is compounded by the predominant reliance of current medical LLMs on corpora from scientific literature or synthetic data, which often lack the granular expert validation and high clinical relevance essential for advancing their specialized medical capabilities. To address these critical gaps, we introduce a highly clinically relevant dataset with 31,247 medical question-answer pairs, each accompanied by expert-validated chain-of-thought (CoT) explanations. This resource, spanning multiple clinical domains, was curated via a scalable human-LLM hybrid pipeline: LLM-generated rationales were iteratively reviewed, scored, and refined by medical experts against a structured rubric, with substandard outputs revised through human effort or guided LLM regeneration until expert consensus. This publicly available dataset provides a vital source for the development of medical LLMs that capable of transparent and verifiable reasoning, thereby advancing safer and more interpretable AI in medicine.
GMAI-VL-R1: Harnessing Reinforcement Learning for Multimodal Medical Reasoning
Apr 02, 2025Recent advances in general medical AI have made significant strides, but existing models often lack the reasoning capabilities needed for complex medical decision-making. This paper presents GMAI-VL-R1, a multimodal medical reasoning model enhanced by reinforcement learning (RL) to improve its reasoning abilities. Through iterative training, GMAI-VL-R1 optimizes decision-making, significantly boosting diagnostic accuracy and clinical support. We also develop a reasoning data synthesis method, generating step-by-step reasoning data via rejection sampling, which further enhances the model's generalization. Experimental results show that after RL training, GMAI-VL-R1 excels in tasks such as medical image diagnosis and visual question answering. While the model demonstrates basic memorization with supervised fine-tuning, RL is crucial for true generalization. Our work establishes new evaluation benchmarks and paves the way for future advancements in medical reasoning models. Code, data, and model will be released at \href{https://github.com/uni-medical/GMAI-VL-R1}{this link}.
GMAI-VL & GMAI-VL-5.5M: A Large Vision-Language Model and A Comprehensive Multimodal Dataset Towards General Medical AI
Nov 21, 2024Despite significant advancements in general artificial intelligence, such as GPT-4, their effectiveness in the medical domain (general medical AI, GMAI) remains constrained due to the absence of specialized medical knowledge. To address this challenge, we present GMAI-VL-5.5M, a comprehensive multimodal medical dataset created by converting hundreds of specialized medical datasets into meticulously constructed image-text pairs. This dataset features comprehensive task coverage, diverse modalities, and high-quality image-text data. Building upon this multimodal dataset, we propose GMAI-VL, a general medical vision-language model with a progressively three-stage training strategy. This approach significantly enhances the model's ability by integrating visual and textual information, thereby improving its ability to process multimodal data and support accurate diagnosis and clinical decision-making. Experimental evaluations demonstrate that GMAI-VL achieves state-of-the-art results across a wide range of multimodal medical tasks, such as visual question answering and medical image diagnosis. Our contributions include the development of the GMAI-VL-5.5M dataset, the introduction of the GMAI-VL model, and the establishment of new benchmarks in multiple medical domains. Code and dataset will be released at https://github.com/uni-medical/GMAI-VL.
Hybrid NeRF-Stereo Vision: Pioneering Depth Estimation and 3D Reconstruction in Endoscopy
Oct 10, 2024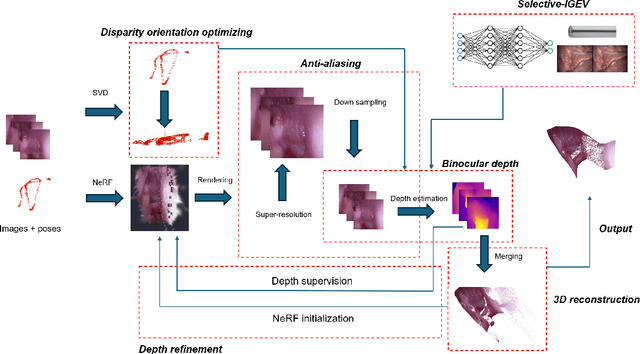
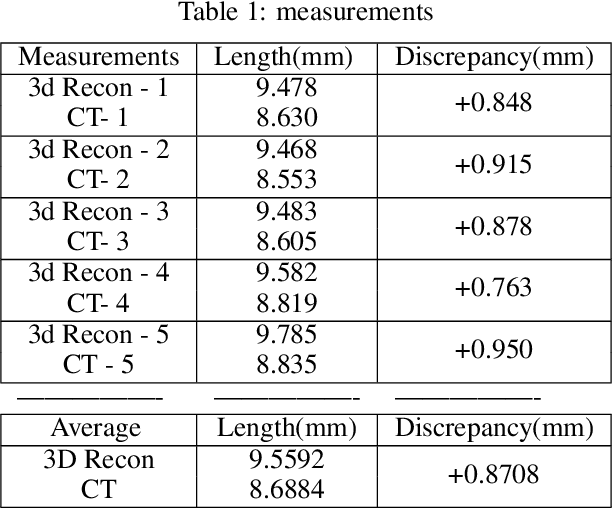
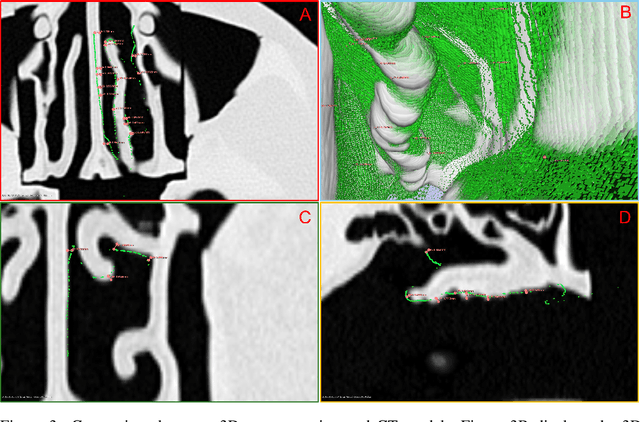
The 3D reconstruction of the surgical field in minimally invasive endoscopic surgery has posed a formidable challenge when using conventional monocular endoscopes. Existing 3D reconstruction methodologies are frequently encumbered by suboptimal accuracy and limited generalization capabilities. In this study, we introduce an innovative pipeline using Neural Radiance Fields (NeRF) for 3D reconstruction. Our approach utilizes a preliminary NeRF reconstruction that yields a coarse model, then creates a binocular scene within the reconstructed environment, which derives an initial depth map via stereo vision. This initial depth map serves as depth supervision for subsequent NeRF iterations, progressively refining the 3D reconstruction with enhanced accuracy. The binocular depth is iteratively recalculated, with the refinement process continuing until the depth map converges, and exhibits negligible variations. Through this recursive process, high-fidelity depth maps are generated from monocular endoscopic video of a realistic cranial phantom. By repeated measures of the final 3D reconstruction compared to X-ray computed tomography, all differences of relevant clinical distances result in sub-millimeter accuracy.
SePPO: Semi-Policy Preference Optimization for Diffusion Alignment
Oct 07, 2024



Reinforcement learning from human feedback (RLHF) methods are emerging as a way to fine-tune diffusion models (DMs) for visual generation. However, commonly used on-policy strategies are limited by the generalization capability of the reward model, while off-policy approaches require large amounts of difficult-to-obtain paired human-annotated data, particularly in visual generation tasks. To address the limitations of both on- and off-policy RLHF, we propose a preference optimization method that aligns DMs with preferences without relying on reward models or paired human-annotated data. Specifically, we introduce a Semi-Policy Preference Optimization (SePPO) method. SePPO leverages previous checkpoints as reference models while using them to generate on-policy reference samples, which replace "losing images" in preference pairs. This approach allows us to optimize using only off-policy "winning images." Furthermore, we design a strategy for reference model selection that expands the exploration in the policy space. Notably, we do not simply treat reference samples as negative examples for learning. Instead, we design an anchor-based criterion to assess whether the reference samples are likely to be winning or losing images, allowing the model to selectively learn from the generated reference samples. This approach mitigates performance degradation caused by the uncertainty in reference sample quality. We validate SePPO across both text-to-image and text-to-video benchmarks. SePPO surpasses all previous approaches on the text-to-image benchmarks and also demonstrates outstanding performance on the text-to-video benchmarks. Code will be released in https://github.com/DwanZhang-AI/SePPO.