 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombined fluorescence and photoacoustic imaging of tozuleristide in muscle tissue in vitro -- toward optically-guided solid tumor surgery: feasibility studies
Oct 31, 2025Near-infrared fluorescence (NIRF) can deliver high-contrast, video-rate, non-contact imaging of tumor-targeted contrast agents with the potential to guide surgeries excising solid tumors. However, it has been met with skepticism for wide-margin excision due to sensitivity and resolution limitations at depths larger than ~5 mm in tissue. To address this limitation, fast-sweep photoacoustic-ultrasound (PAUS) imaging is proposed to complement NIRF. In an exploratory in vitro feasibility study using dark-red bovine muscle tissue, we observed that PAUS scanning can identify tozuleristide, a clinical stage investigational imaging agent, at a concentration of 20 uM from the background at depths of up to ~34 mm, highly extending the capabilities of NIRF alone. The capability of spectroscopic PAUS imaging was tested by direct injection of 20 uM tozuleristide into bovine muscle tissue at a depth of ~ 8 mm. It is shown that laser-fluence compensation and strong clutter suppression enabled by the unique capabilities of the fast-sweep approach greatly improve spectroscopic accuracy and the PA detection limit, and strongly reduce image artifacts. Thus, the combined NIRF-PAUS approach can be promising for comprehensive pre- (with PA) and intra- (with NIRF) operative solid tumor detection and wide-margin excision in optically guided solid tumor surgery.
Hybrid NeRF-Stereo Vision: Pioneering Depth Estimation and 3D Reconstruction in Endoscopy
Oct 10, 2024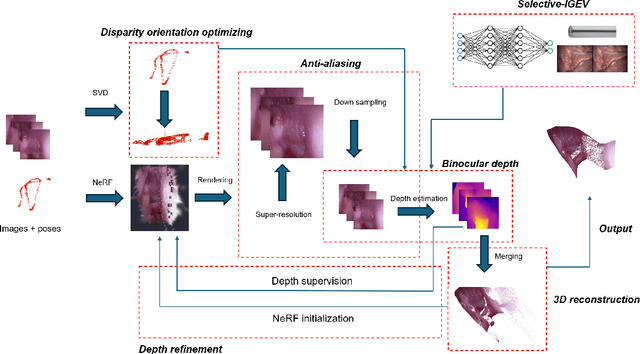
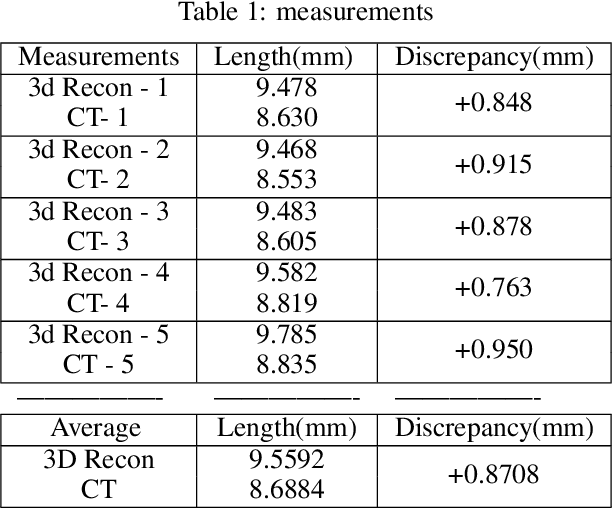
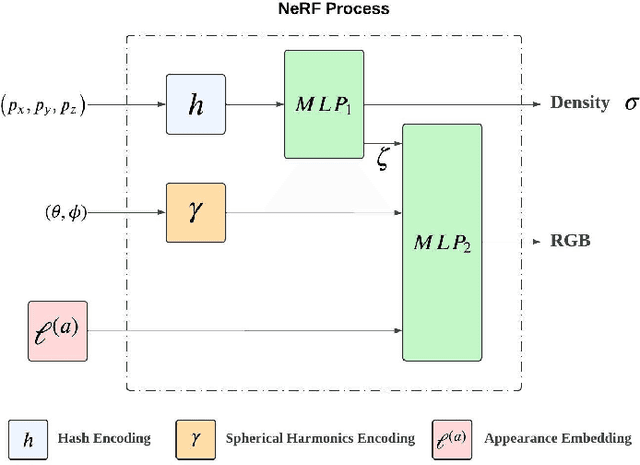
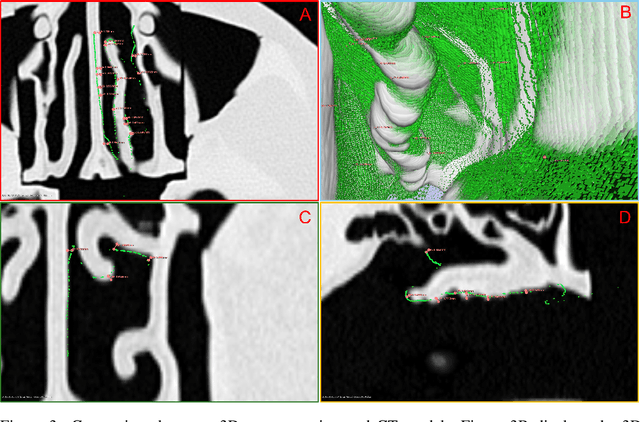
The 3D reconstruction of the surgical field in minimally invasive endoscopic surgery has posed a formidable challenge when using conventional monocular endoscopes. Existing 3D reconstruction methodologies are frequently encumbered by suboptimal accuracy and limited generalization capabilities. In this study, we introduce an innovative pipeline using Neural Radiance Fields (NeRF) for 3D reconstruction. Our approach utilizes a preliminary NeRF reconstruction that yields a coarse model, then creates a binocular scene within the reconstructed environment, which derives an initial depth map via stereo vision. This initial depth map serves as depth supervision for subsequent NeRF iterations, progressively refining the 3D reconstruction with enhanced accuracy. The binocular depth is iteratively recalculated, with the refinement process continuing until the depth map converges, and exhibits negligible variations. Through this recursive process, high-fidelity depth maps are generated from monocular endoscopic video of a realistic cranial phantom. By repeated measures of the final 3D reconstruction compared to X-ray computed tomography, all differences of relevant clinical distances result in sub-millimeter accuracy.
Synergistic Network Learning and Label Correction for Noise-robust Image Classification
Feb 27, 2022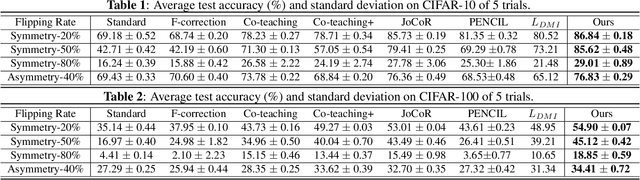
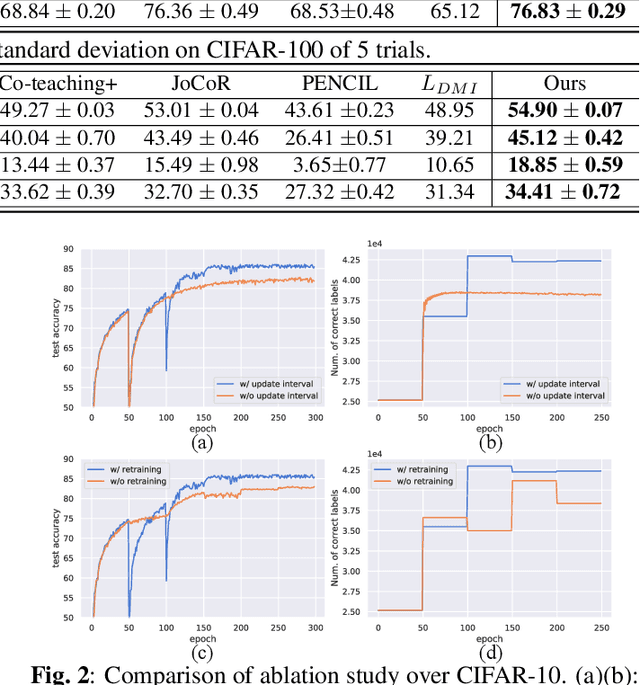
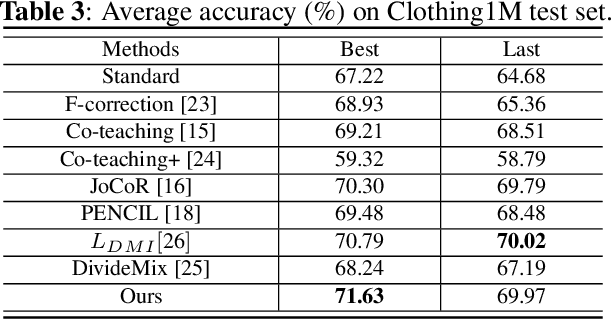
Large training datasets almost always contain examples with inaccurate or incorrect labels. Deep Neural Networks (DNNs) tend to overfit training label noise, resulting in poorer model performance in practice. To address this problem, we propose a robust label correction framework combining the ideas of small loss selection and noise correction, which learns network parameters and reassigns ground truth labels iteratively. Taking the expertise of DNNs to learn meaningful patterns before fitting noise, our framework first trains two networks over the current dataset with small loss selection. Based on the classification loss and agreement loss of two networks, we can measure the confidence of training data. More and more confident samples are selected for label correction during the learning process. We demonstrate our method on both synthetic and real-world datasets with different noise types and rates, including CIFAR-10, CIFAR-100 and Clothing1M, where our method outperforms the baseline approaches.
RetinaMatch: Efficient Template Matching of Retina Images for Teleophthalmology
Nov 28, 2018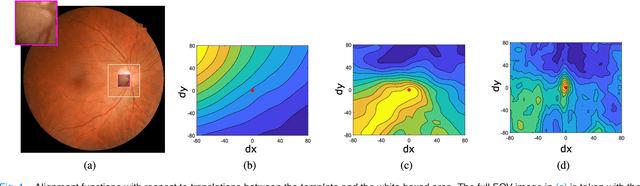
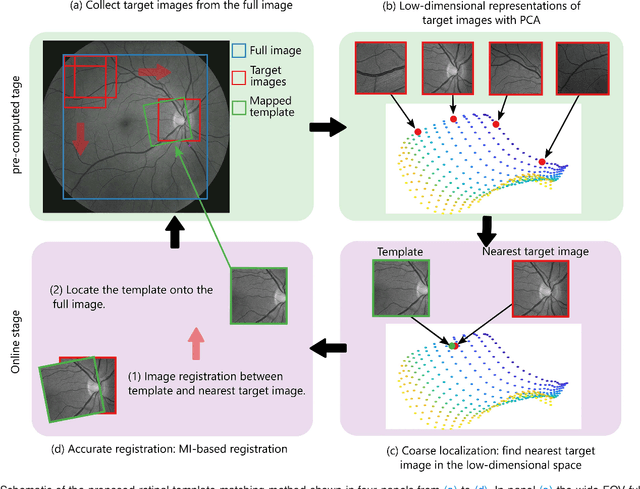
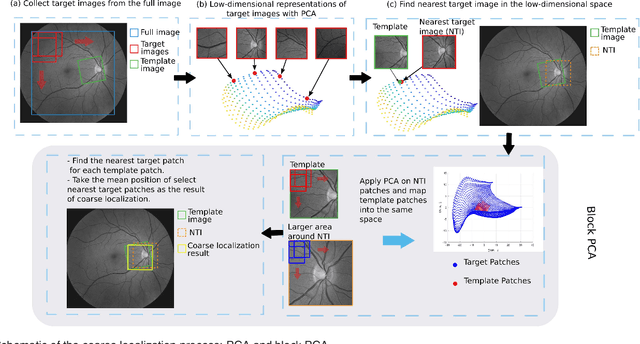
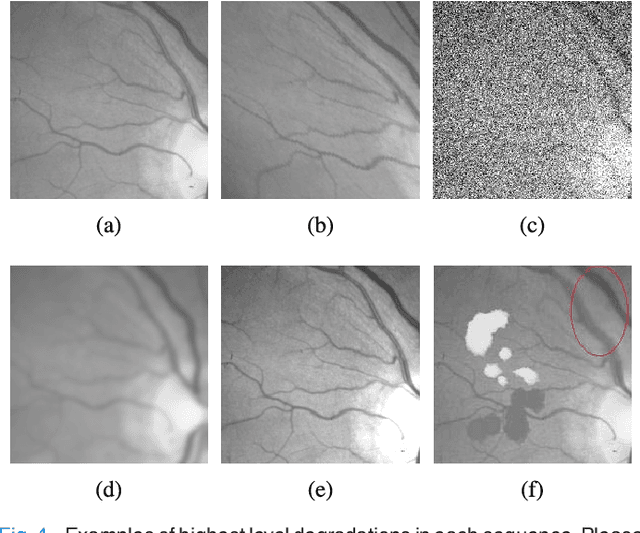
Retinal template matching and registration is an important challenge in teleophthalmology with low-cost imaging devices. However, the images from such devices generally have a small field of view (FOV) and image quality degradations, making matching difficult. In this work, we develop an efficient and accurate retinal matching technique that combines dimension reduction and mutual information (MI), called RetinaMatch. The dimension reduction initializes the MI optimization as a coarse localization process, which narrows the optimization domain and avoids local optima. The effectiveness of RetinaMatch is demonstrated on the open fundus image database STARE with simulated reduced FOV and anticipated degradations, and on retinal images acquired by adapter-based optics attached to a smartphone. RetinaMatch achieves a success rate over 94\% on human retinal images with the matched target registration errors below 2 pixels on average, excluding the observer variability. It outperforms the standard template matching solutions. In the application of measuring vessel diameter repeatedly, single pixel errors are expected. In addition, our method can be used in the process of image mosaicking with area-based registration, providing a robust approach when the feature based methods fail. To the best of our knowledge, this is the first template matching algorithm for retina images with small template images from unconstrained retinal areas. In the context of the emerging mixed reality market, we envision automated retinal image matching and registration methods as transformative for advanced teleophthalmology and long-term retinal monitoring.