 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-Judge: Disrupting Multi-Turn Jailbreaks using Semantics-Preserving Output Rewriting
May 31, 2026Multi-turn jailbreak attacks pose a growing threat to large language model (LLM) safety because they exploit feedback from auxiliary judge models to iteratively refine prompts toward harmful goals. Existing defenses largely detect or block unsafe content at individual turns or at the final response, leaving the judge-driven refinement loop intact and allowing attackers to extract informative feedback from intermediate interactions. We introduce D-Judge, a semantics-preserving output rewriting defense that intervenes directly in this loop by rewriting the victim LLM's responses before they are evaluated by the attacker's judge. By misaligning the judge's feedback signal without changing the meaning of the original response, D-Judge derails the attacker's prompt-refinement process, causing subsequent queries to be optimized against a distorted signal of attack progress. To improve D-Judge's ability to produce such rewrites, we construct a dataset of semantically equivalent response pairs that induce different judge-assigned harmfulness scores, and use it for supervised fine-tuning followed by direct preference optimization. Experiments on HarmBench show that D-Judge reduces the success rate of state-of-the-art multi-turn jailbreaks while preserving performance on benign benchmarks.
Sharpen Your Flow: Sharpness-Aware Sampling for Flow Matching
May 12, 2026Flow matching models generate samples by numerically integrating a learned velocity field, with each integration step requiring a neural network evaluation. Fast generation therefore requires using a small fixed evaluation budget effectively: the key question is not only how to integrate the flow, but where the sampler should spend its steps. We propose SharpEuler, a training-free sampler that profiles a pretrained model offline by estimating where the learned velocity field changes most rapidly along calibration trajectories. This finite-difference estimate defines a solver-aware sharpness profile, which is smoothed and converted by a quantile transform into a timestep grid for any desired inference budget. At test time, sampling remains ordinary Euler integration with the same number of model evaluations as a uniform schedule. We justify SharpEuler using three principles: a numerical principle identifying trajectory acceleration as the leading source of Euler discretization error, a variational principle deriving sharpness-based power-law timestep densities, and a statistical guarantee showing that the finite-sample calibrated sampler is stable at the terminal distribution level. Our experiments show that SharpEuler improves sample quality at fixed budgets, reducing inter-mode leakage and increasing mode coverage.
Zatom-1: A Multimodal Flow Foundation Model for 3D Molecules and Materials
Feb 24, 2026General-purpose 3D chemical modeling encompasses molecules and materials, requiring both generative and predictive capabilities. However, most existing AI approaches are optimized for a single domain (molecules or materials) and a single task (generation or prediction), which limits representation sharing and transfer. We introduce Zatom-1, the first foundation model that unifies generative and predictive learning of 3D molecules and materials. Zatom-1 is a Transformer trained with a multimodal flow matching objective that jointly models discrete atom types and continuous 3D geometries. This approach supports scalable pretraining with predictable gains as model capacity increases, while enabling fast and stable sampling. We use joint generative pretraining as a universal initialization for downstream multi-task prediction of properties, energies, and forces. Empirically, Zatom-1 matches or outperforms specialized baselines on both generative and predictive benchmarks, while reducing the generative inference time by more than an order of magnitude. Our experiments demonstrate positive predictive transfer between chemical domains from joint generative pretraining: modeling materials during pretraining improves molecular property prediction accuracy.
Quantifying Epistemic Uncertainty in Diffusion Models
Feb 09, 2026To ensure high quality outputs, it is important to quantify the epistemic uncertainty of diffusion models. Existing methods are often unreliable because they mix epistemic and aleatoric uncertainty. We introduce a method based on Fisher information that explicitly isolates epistemic variance, producing more reliable plausibility scores for generated data. To make this approach scalable, we propose FLARE (Fisher-Laplace Randomized Estimator), which approximates the Fisher information using a uniformly random subset of model parameters. Empirically, FLARE improves uncertainty estimation in synthetic time-series generation tasks, achieving more accurate and reliable filtering than other methods. Theoretically, we bound the convergence rate of our randomized approximation and provide analytic and empirical evidence that last-layer Laplace approximations are insufficient for this task.
Is Flow Matching Just Trajectory Replay for Sequential Data?
Feb 09, 2026Flow matching (FM) is increasingly used for time-series generation, but it is not well understood whether it learns a general dynamical structure or simply performs an effective "trajectory replay". We study this question by deriving the velocity field targeted by the empirical FM objective on sequential data, in the limit of perfect function approximation. For the Gaussian conditional paths commonly used in practice, we show that the implied sampler is an ODE whose dynamics constitutes a nonparametric, memory-augmented continuous-time dynamical system. The optimal field admits a closed-form expression as a similarity-weighted mixture of instantaneous velocities induced by past transitions, making the dataset dependence explicit and interpretable. This perspective positions neural FM models trained by stochastic optimization as parametric surrogates of an ideal nonparametric solution. Using the structure of the optimal field, we study sampling and approximation schemes that improve the efficiency and numerical robustness of ODE-based generation. On nonlinear dynamical system benchmarks, the resulting closed-form sampler yields strong probabilistic forecasts directly from historical transitions, without training.
Is Reasoning Capability Enough for Safety in Long-Context Language Models?
Feb 09, 2026Large language models (LLMs) increasingly combine long-context processing with advanced reasoning, enabling them to retrieve and synthesize information distributed across tens of thousands of tokens. A hypothesis is that stronger reasoning capability should improve safety by helping models recognize harmful intent even when it is not stated explicitly. We test this hypothesis in long-context settings where harmful intent is implicit and must be inferred through reasoning, and find that it does not hold. We introduce compositional reasoning attacks, a new threat model in which a harmful query is decomposed into incomplete fragments that scattered throughout a long context. The model is then prompted with a neutral reasoning query that induces retrieval and synthesis, causing the harmful intent to emerge only after composition. Evaluating 14 frontier LLMs on contexts up to 64k tokens, we uncover three findings: (1) models with stronger general reasoning capability are not more robust to compositional reasoning attacks, often assembling the intent yet failing to refuse; (2) safety alignment consistently degrades as context length increases; and (3) inference-time reasoning effort is a key mitigating factor: increasing inference-time compute reduces attack success by over 50 percentage points on GPT-oss-120b model. Together, these results suggest that safety does not automatically scale with reasoning capability, especially under long-context inference.
PRISM: Distribution-free Adaptive Computation of Matrix Functions for Accelerating Neural Network Training
Jan 29, 2026Matrix functions such as square root, inverse roots, and orthogonalization play a central role in preconditioned gradient methods for neural network training. This has motivated the development of iterative algorithms that avoid explicit eigendecompositions and rely primarily on matrix multiplications, making them well suited for modern GPU accelerators. We present PRISM (Polynomial-fitting and Randomized Iterative Sketching for Matrix functions computation), a general framework for accelerating iterative algorithms for computing matrix functions. PRISM combines adaptive polynomial approximation with randomized sketching: at each iteration, it fits a polynomial surrogate to the current spectrum via a sketched least-squares problem, adapting to the instance at hand with minimal overhead. We apply PRISM to accelerate Newton-Schulz-like iterations for matrix square roots and orthogonalization, which are core primitives in machine learning. Unlike prior methods, PRISM requires no explicit spectral bounds or singular value estimates; and it adapts automatically to the evolving spectrum. Empirically, PRISM accelerates training when integrated into Shampoo and Muon optimizers.
HydroDiffusion: Diffusion-Based Probabilistic Streamflow Forecasting with a State Space Backbone
Dec 13, 2025Recent advances have introduced diffusion models for probabilistic streamflow forecasting, demonstrating strong early flood-warning skill. However, current implementations rely on recurrent Long Short-Term Memory (LSTM) backbones and single-step training objectives, which limit their ability to capture long-range dependencies and produce coherent forecast trajectories across lead times. To address these limitations, we developed HydroDiffusion, a diffusion-based probabilistic forecasting framework with a decoder-only state space model backbone. The proposed framework jointly denoises full multi-day trajectories in a single pass, ensuring temporal coherence and mitigating error accumulation common in autoregressive prediction. HydroDiffusion is evaluated across 531 watersheds in the contiguous United States (CONUS) in the CAMELS dataset. We benchmark HydroDiffusion against two diffusion baselines with LSTM backbones, as well as the recently proposed Diffusion-based Runoff Model (DRUM). Results show that HydroDiffusion achieves strong nowcast accuracy when driven by observed meteorological forcings, and maintains consistent performance across the full simulation horizon. Moreover, HydroDiffusion delivers stronger deterministic and probabilistic forecast skill than DRUM in operational forecasting. These results establish HydroDiffusion as a robust generative modeling framework for medium-range streamflow forecasting, providing both a new modeling benchmark and a foundation for future research on probabilistic hydrologic prediction at continental scales.
FLEX: A Backbone for Diffusion-Based Modeling of Spatio-temporal Physical Systems
May 23, 2025We introduce FLEX (FLow EXpert), a backbone architecture for generative modeling of spatio-temporal physical systems using diffusion models. FLEX operates in the residual space rather than on raw data, a modeling choice that we motivate theoretically, showing that it reduces the variance of the velocity field in the diffusion model, which helps stabilize training. FLEX integrates a latent Transformer into a U-Net with standard convolutional ResNet layers and incorporates a redesigned skip connection scheme. This hybrid design enables the model to capture both local spatial detail and long-range dependencies in latent space. To improve spatio-temporal conditioning, FLEX uses a task-specific encoder that processes auxiliary inputs such as coarse or past snapshots. Weak conditioning is applied to the shared encoder via skip connections to promote generalization, while strong conditioning is applied to the decoder through both skip and bottleneck features to ensure reconstruction fidelity. FLEX achieves accurate predictions for super-resolution and forecasting tasks using as few as two reverse diffusion steps. It also produces calibrated uncertainty estimates through sampling. Evaluations on high-resolution 2D turbulence data show that FLEX outperforms strong baselines and generalizes to out-of-distribution settings, including unseen Reynolds numbers, physical observables (e.g., fluid flow velocity fields), and boundary conditions.
Block-Biased Mamba for Long-Range Sequence Processing
May 13, 2025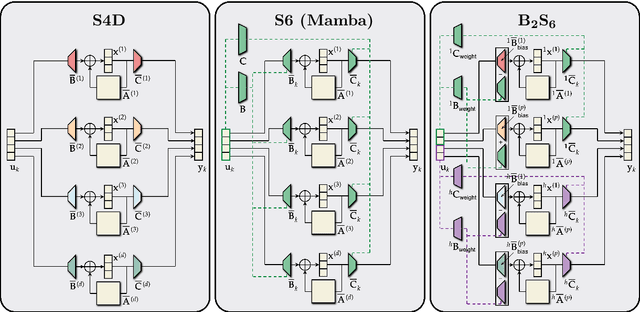
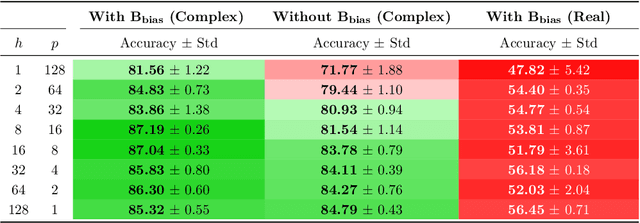
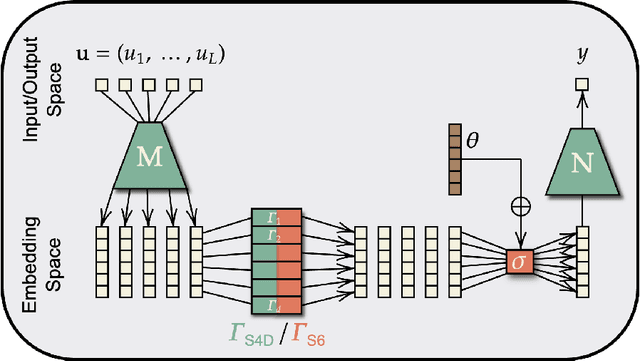
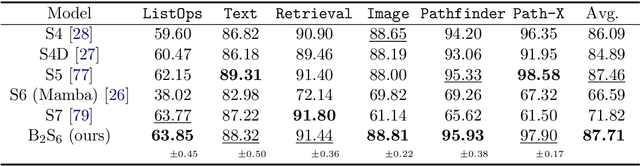
Mamba extends earlier state space models (SSMs) by introducing input-dependent dynamics, and has demonstrated strong empirical performance across a range of domains, including language modeling, computer vision, and foundation models. However, a surprising weakness remains: despite being built on architectures designed for long-range dependencies, Mamba performs poorly on long-range sequential tasks. Understanding and addressing this gap is important for improving Mamba's universality and versatility. In this work, we analyze Mamba's limitations through three perspectives: expressiveness, inductive bias, and training stability. Our theoretical results show how Mamba falls short in each of these aspects compared to earlier SSMs such as S4D. To address these issues, we propose $\text{B}_2\text{S}_6$, a simple extension of Mamba's S6 unit that combines block-wise selective dynamics with a channel-specific bias. We prove that these changes equip the model with a better-suited inductive bias and improve its expressiveness and stability. Empirically, $\text{B}_2\text{S}_6$ outperforms S4 and S4D on Long-Range Arena (LRA) tasks while maintaining Mamba's performance on language modeling benchmarks.